F2IDiff: Real-world Image Super-resolution using Feature to Image Diffusion Foundation Model
作者: Devendra K. Jangid, Ripon K. Saha, Dilshan Godaliyadda, Jing Li, Seok-Jun Lee, Hamid R. Sheikh
分类: cs.CV, cs.AI, eess.IV
发布日期: 2025-12-30
💡 一句话要点
提出F2IDiff,利用特征到图像扩散模型提升真实场景图像超分辨率效果,减少伪影。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像超分辨率 扩散模型 特征到图像 DINOv2 生成式AI
📋 核心要点
- 现有基于文本到图像扩散模型的超分辨率方法在真实场景下易产生伪影,无法满足消费级摄影需求。
- 提出F2IDiff,利用DINOv2特征作为扩散模型的条件,提供更严格和丰富的图像描述,控制生成过程。
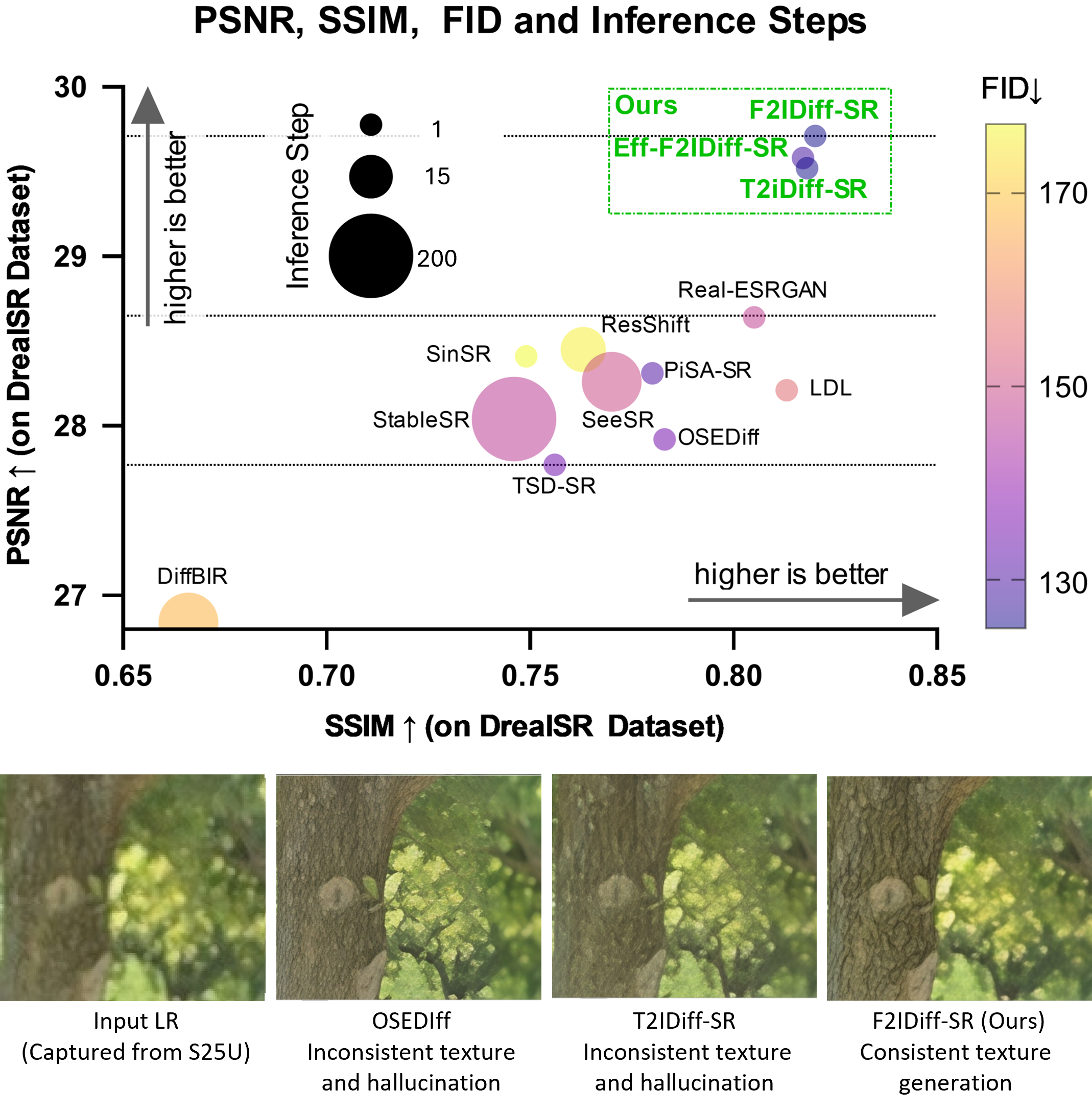
- 实验表明,F2IDiff在真实场景图像超分辨率任务中,能够有效减少伪影,提升图像质量。
📝 摘要(中文)
随着生成式AI的出现,单图像超分辨率(SISR)的质量得到了显著提高,因为文本到图像扩散(T2IDiff)基础模型(FM)学习到的强大先验知识可以弥合高分辨率(HR)和低分辨率(LR)图像之间的差距。然而,旗舰智能手机摄像头在采用生成模型方面进展缓慢,因为强大的生成能力可能导致不希望出现的伪影。对于学术界常见的严重退化的LR图像,需要强大的生成能力,并且由于LR和HR图像之间的差距很大,因此可以容忍伪影。相比之下,在消费级摄影中,LR图像具有更高的保真度,只需要最少的无伪影生成。我们假设SISR中的生成是由FM的条件特征的严格性和丰富性控制的。首先,文本特征是高级特征,通常无法描述图像中的细微纹理。此外,智能手机LR图像至少为12MP,而基于T2IDiff FM构建的SISR网络旨在对更小的图像(<1MP)执行推理。因此,SISR推理必须在小块上执行,而小块通常无法用文本特征准确描述。为了解决这些缺点,我们引入了一个基于FM构建的SISR网络,该FM具有较低级别的特征条件,特别是DINOv2特征,我们称之为特征到图像扩散(F2IDiff)基础模型(FM)。较低级别的特征提供更严格的条件,同时也是对小块的丰富描述。
🔬 方法详解
问题定义:论文旨在解决真实世界图像超分辨率(SISR)问题,特别是在消费级摄影场景下,现有基于文本到图像扩散模型的方法容易产生不希望的伪影,导致图像质量下降。现有方法的痛点在于文本特征无法准确描述图像的细微纹理,且在小图像块上进行推理时,文本特征的描述能力不足。
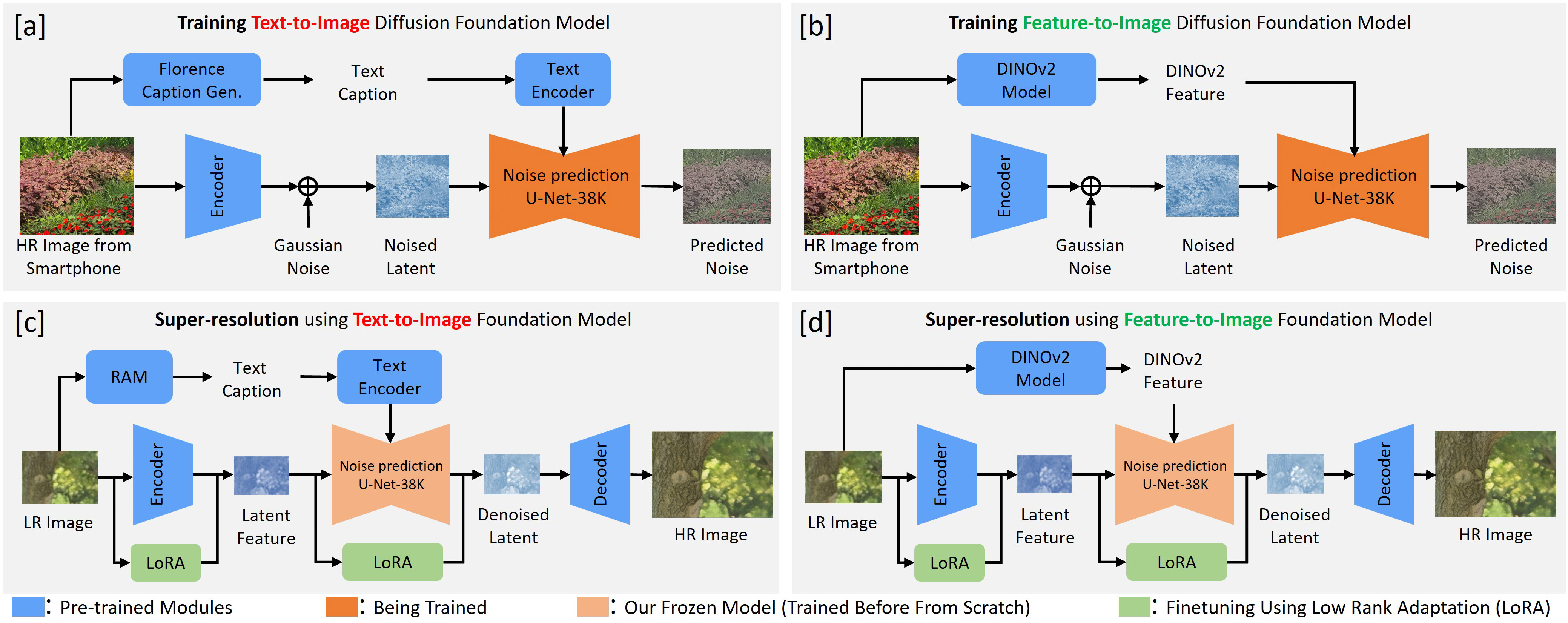
核心思路:论文的核心思路是使用更低级别的图像特征(DINOv2特征)作为扩散模型的条件,替代原有的文本特征。DINOv2特征能够提供更严格和丰富的图像描述,从而更好地控制生成过程,减少伪影的产生。这样设计的目的是为了在保证超分辨率效果的同时,避免过度生成导致的不真实细节。
技术框架:F2IDiff的整体架构基于扩散模型,主要包含以下模块:1)低分辨率图像输入;2)DINOv2特征提取器,用于提取低分辨率图像的特征;3)扩散模型,以DINOv2特征作为条件,逐步生成高分辨率图像。整个流程通过特征引导的扩散过程,将低分辨率图像转换为高分辨率图像。
关键创新:最重要的技术创新点在于使用特征到图像的扩散模型(F2IDiff),而非传统的文本到图像扩散模型。与现有方法的本质区别在于,F2IDiff使用更低级别的图像特征作为条件,从而实现更精确的图像控制和更少的伪影生成。
关键设计:论文的关键设计包括:1)选择DINOv2作为特征提取器,因为它能够提供丰富的图像描述;2)设计了特定的扩散模型结构,以适应DINOv2特征的输入;3)可能使用了特定的损失函数来优化模型的生成质量,例如感知损失或对抗损失(具体细节未知)。
🖼️ 关键图片

📊 实验亮点
论文提出的F2IDiff模型在真实场景图像超分辨率任务中表现出色,能够有效减少伪影的产生,提升图像的视觉质量。虽然论文摘要中没有给出具体的性能数据和对比基线,但强调了其在减少伪影方面的优势,这对于消费级摄影应用至关重要。(具体实验数据未知)
🎯 应用场景
该研究成果可应用于智能手机摄影、监控视频增强、医学图像处理等领域。通过提升低分辨率图像的清晰度,改善用户体验,提高图像分析的准确性。未来,该方法有望在更多需要高质量图像的场景中发挥作用,例如遥感图像处理、文物修复等。
📄 摘要(原文)
With the advent of Generative AI, Single Image Super-Resolution (SISR) quality has seen substantial improvement, as the strong priors learned by Text-2-Image Diffusion (T2IDiff) Foundation Models (FM) can bridge the gap between High-Resolution (HR) and Low-Resolution (LR) images. However, flagship smartphone cameras have been slow to adopt generative models because strong generation can lead to undesirable hallucinations. For substantially degraded LR images, as seen in academia, strong generation is required and hallucinations are more tolerable because of the wide gap between LR and HR images. In contrast, in consumer photography, the LR image has substantially higher fidelity, requiring only minimal hallucination-free generation. We hypothesize that generation in SISR is controlled by the stringency and richness of the FM's conditioning feature. First, text features are high level features, which often cannot describe subtle textures in an image. Additionally, Smartphone LR images are at least $12MP$, whereas SISR networks built on T2IDiff FM are designed to perform inference on much smaller images ($<1MP$). As a result, SISR inference has to be performed on small patches, which often cannot be accurately described by text feature. To address these shortcomings, we introduce an SISR network built on a FM with lower-level feature conditioning, specifically DINOv2 features, which we call a Feature-to-Image Diffusion (F2IDiff) Foundation Model (FM). Lower level features provide stricter conditioning while being rich descriptors of even small patches.