DyStream: Streaming Dyadic Talking Heads Generation via Flow Matching-based Autoregressive Model
作者: Bohong Chen, Haiyang Liu
分类: cs.CV
发布日期: 2025-12-30 (更新: 2026-02-02)
备注: Project Page: https://robinwitch.github.io/DyStream-Page
💡 一句话要点
DyStream:基于流匹配自回归模型的流式双人对话头像生成
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 流式生成 对话头像 流匹配 自回归模型 低延迟 唇形同步 实时通信
📋 核心要点
- 现有对话头像生成方法延迟高,无法满足实时交互需求,尤其是在听者头像生成上。
- DyStream采用流匹配自回归模型,结合因果编码器和前瞻模块,实现低延迟高质量的视频生成。
- 实验表明,DyStream能以34ms/帧的速度生成视频,总延迟低于100ms,唇形同步质量达到SOTA。
📝 摘要(中文)
本文提出DyStream,一种基于流匹配的自回归模型,用于实时生成说话者和听者的双人对话头像视频。现有基于分块的方法需要完整的非因果上下文窗口,导致显著延迟,阻碍了逼真听者所需的即时非语言反馈。DyStream采用流友好的自回归框架,利用流匹配头进行概率建模。此外,提出了一个因果编码器,通过前瞻模块增强,以纳入短期的未来上下文(例如60毫秒),从而在保持低延迟的同时提高质量。分析表明,这种简单有效的方法显著优于其他因果策略,包括蒸馏和生成编码器。实验表明,DyStream能够以每帧34毫秒的速度生成视频,保证整个系统延迟保持在100毫秒以下。此外,它实现了最先进的唇形同步质量,在HDTF上离线和在线LipSync Confidence得分分别为8.13和7.61。模型、权重和代码均已开源。
🔬 方法详解
问题定义:现有双人对话头像生成方法,特别是听者头像生成,依赖于非因果的上下文信息,导致较高的延迟。这种延迟阻碍了实时交互应用,因为听者需要即时响应说话者的内容。因此,如何在保证生成质量的前提下,降低延迟,实现流式的双人对话头像生成是一个关键问题。
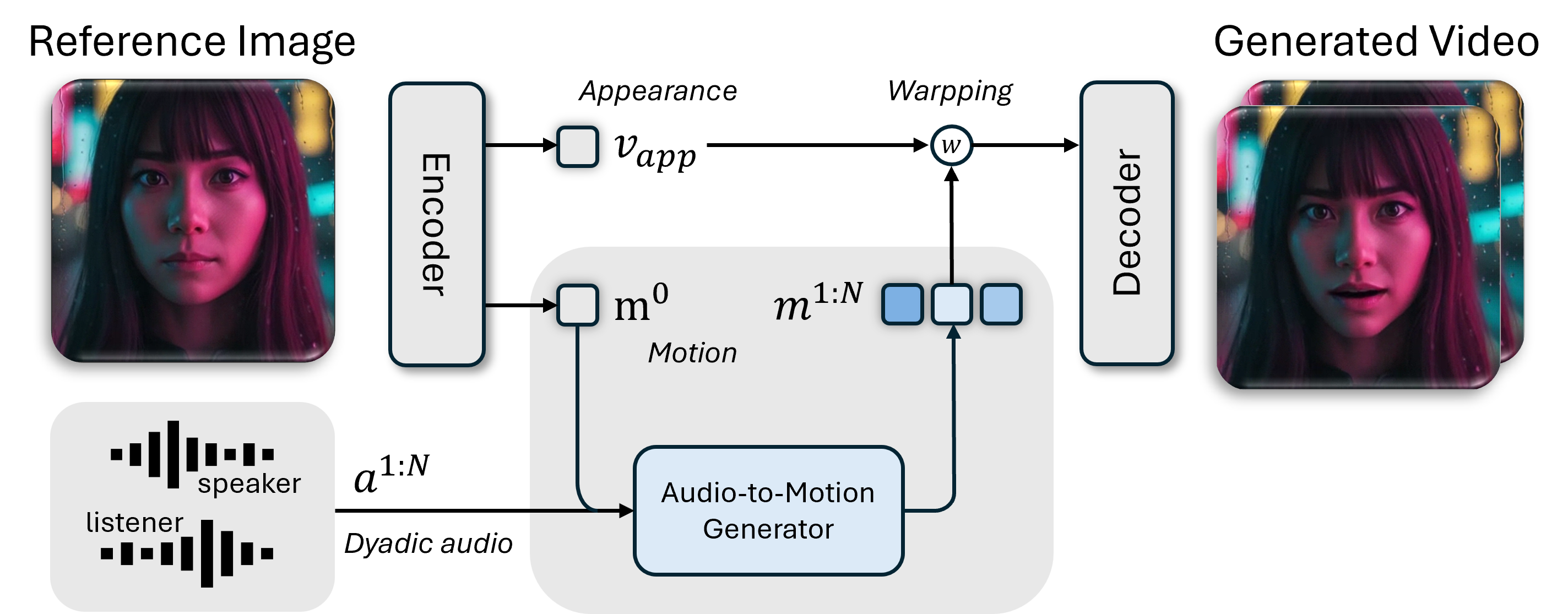
核心思路:DyStream的核心思路是采用流匹配的自回归模型,将视频生成过程建模为一个连续的概率流。通过自回归的方式,模型可以逐步生成每一帧,避免了对整个上下文的依赖。同时,利用流匹配技术,可以有效地学习视频帧之间的过渡,从而保证生成视频的流畅性。
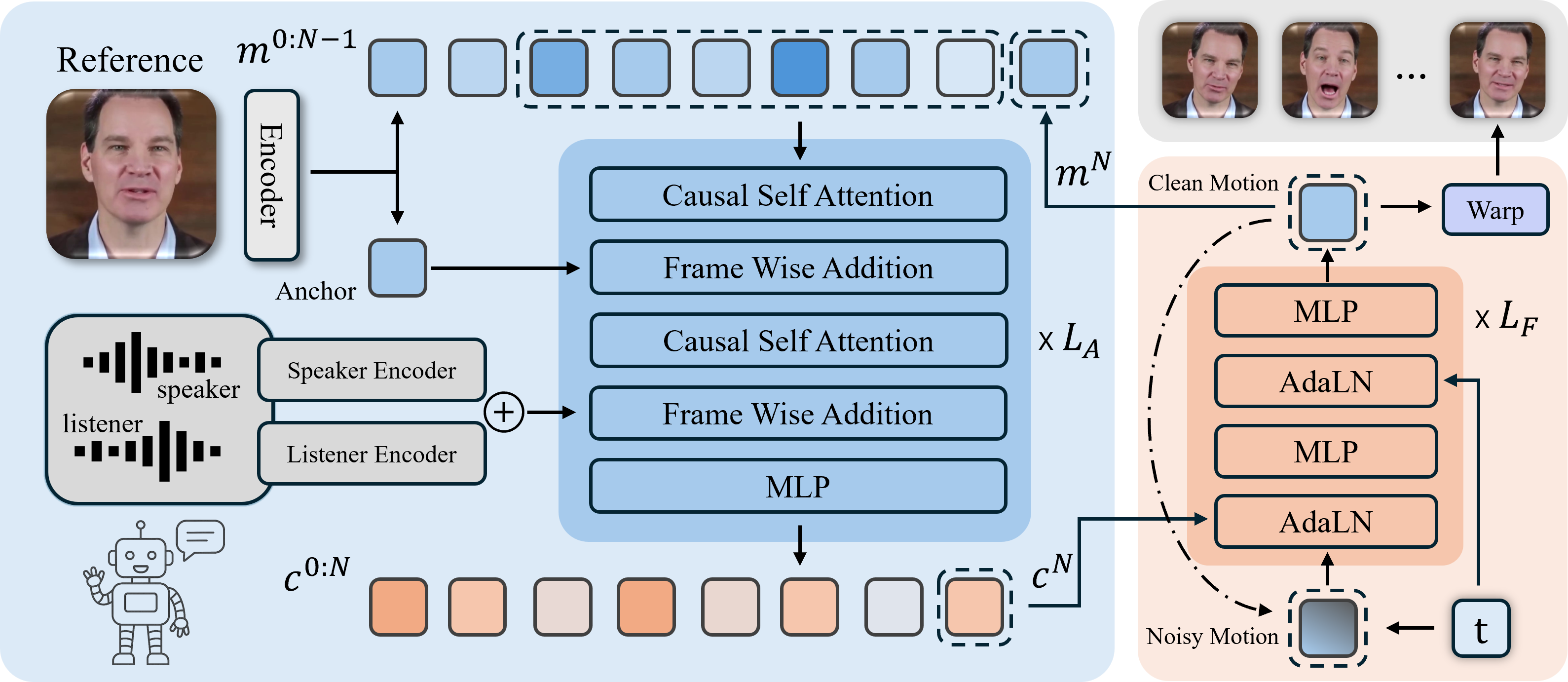
技术框架:DyStream的整体框架包括一个因果编码器和一个流匹配自回归解码器。因果编码器负责提取说话者音频和听者音频的特征,并将其编码成一个低维的潜在表示。为了进一步提高生成质量,编码器还包含一个前瞻模块,用于获取少量的未来信息。流匹配自回归解码器则根据编码器的输出,逐步生成每一帧的视频。
关键创新:DyStream的关键创新在于将流匹配技术引入到自回归视频生成模型中。传统的自回归模型通常采用GAN或VAE等方法进行训练,这些方法存在训练不稳定或生成质量不高的问题。流匹配技术通过学习一个连续的概率流,可以有效地解决这些问题,从而提高生成视频的质量和流畅性。
关键设计:DyStream的关键设计包括:1) 采用流匹配损失函数来训练自回归解码器,该损失函数可以有效地学习视频帧之间的过渡;2) 设计了一个前瞻模块,用于获取少量的未来信息,从而提高生成视频的质量;3) 对编码器和解码器的网络结构进行了优化,以提高模型的效率和生成速度。
🖼️ 关键图片
📊 实验亮点
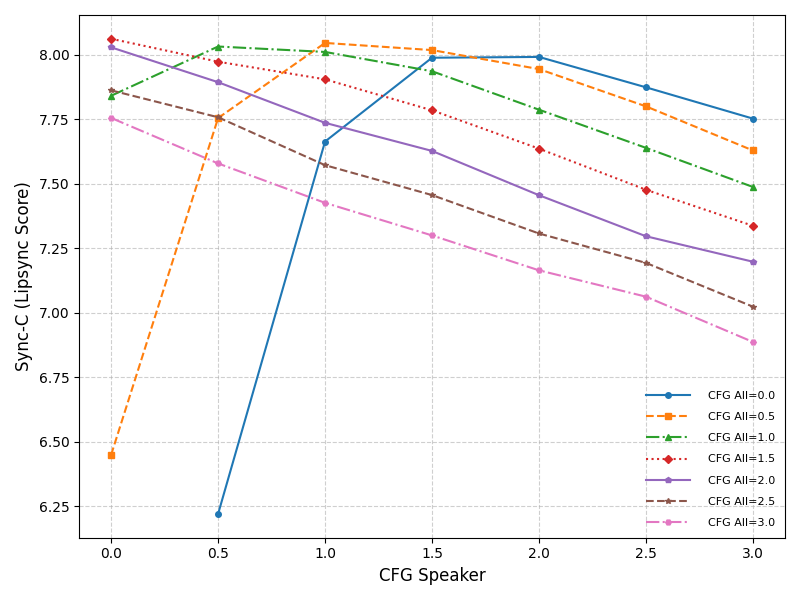
DyStream在HDTF数据集上取得了state-of-the-art的唇形同步效果,离线和在线LipSync Confidence得分分别为8.13和7.61。此外,DyStream能够以每帧34毫秒的速度生成视频,保证整个系统延迟保持在100毫秒以下,满足实时交互的需求。相比于其他因果策略,DyStream在生成质量和延迟方面都具有显著优势。
🎯 应用场景
DyStream在实时通信、虚拟会议、游戏直播等领域具有广泛的应用前景。它可以用于生成逼真的双人对话头像视频,提高用户的交互体验。此外,DyStream还可以应用于虚拟助手、智能客服等领域,实现更加自然和流畅的人机交互。未来,该技术有望进一步发展,应用于更广泛的场景,例如虚拟现实、增强现实等。
📄 摘要(原文)
Generating realistic, dyadic talking head video requires ultra-low latency. Existing chunk-based methods require full non-causal context windows, introducing significant delays. This high latency critically prevents the immediate, non-verbal feedback required for a realistic listener. To address this, we present DyStream, a flow matching-based autoregressive model that could generate video in real-time from both speaker and listener audio. Our method contains two key designs: (1) we adopt a stream-friendly autoregressive framework with flow-matching heads for probabilistic modeling, and (2) We propose a causal encoder enhanced by a lookahead module to incorporate short future context (e.g., 60 ms) to improve quality while maintaining low latency. Our analysis shows this simple-and-effective method significantly surpass alternative causal strategies, including distillation and generative encoder. Extensive experiments show that DyStream could generate video within 34 ms per frame, guaranteeing the entire system latency remains under 100 ms. Besides, it achieves state-of-the-art lip-sync quality, with offline and online LipSync Confidence scores of 8.13 and 7.61 on HDTF, respectively. The model, weights and codes are available.