Robust Egocentric Referring Video Object Segmentation via Dual-Modal Causal Intervention
作者: Haijing Liu, Zhiyuan Song, Hefeng Wu, Tao Pu, Keze Wang, Liang Lin
分类: cs.CV
发布日期: 2025-12-30
备注: NeurIPS 2025
💡 一句话要点
提出CERES框架,通过双模态因果干预解决Ego-RVOS中的偏差和混淆问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction)
关键词: Ego-RVOS 因果推理 因果干预 后门调整 前门调整 语言偏差 视觉混淆
📋 核心要点
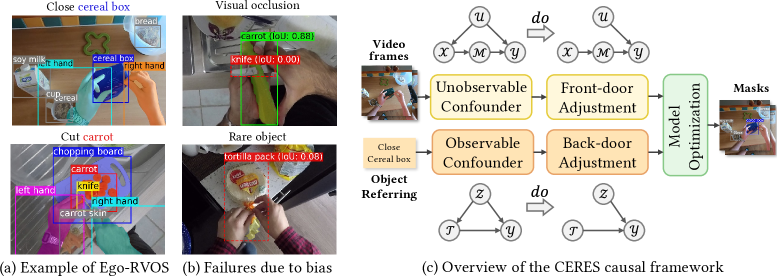
- Ego-RVOS任务面临着由第一人称视角视频的歧义性和数据偏差导致的鲁棒性挑战,现有方法难以有效应对。
- CERES框架通过双模态因果干预,分别使用后门调整和前门调整来解决语言偏差和视觉混淆问题,提升模型鲁棒性。
- 实验结果表明,CERES在Ego-RVOS基准测试中取得了SOTA性能,验证了因果推理在提升模型可靠性方面的潜力。
📝 摘要(中文)
本文提出了一种名为Causal Ego-REferring Segmentation (CERES) 的因果框架,旨在解决第一人称视角视频中,根据语言查询分割特定目标(Ego-RVOS)任务的鲁棒性问题。该任务对于理解以自我为中心的人类行为至关重要。现有的方法容易受到第一人称视频中固有的歧义以及训练数据中存在的偏差的影响,导致模型学习到数据集中倾斜的对象-动作配对以及快速运动和频繁遮挡等视觉混淆因素带来的虚假相关性。CERES是一个即插即用的因果框架,它将强大的预训练RVOS骨干网络适配到以自我为中心的领域。CERES实现了双模态因果干预:应用后门调整原则来抵消从数据集统计中学习到的语言表示偏差,并利用前门调整概念,通过因果原则指导的语义视觉特征与几何深度信息的智能融合来解决视觉混淆问题,从而创建对以自我为中心扭曲更具鲁棒性的表示。大量实验表明,CERES在Ego-RVOS基准测试中实现了最先进的性能,突出了应用因果推理来构建更可靠的模型的潜力,从而促进更广泛的以自我为中心的视频理解。
🔬 方法详解
问题定义:Ego-RVOS任务旨在根据语言描述,在第一人称视角视频中分割出与人类动作相关的特定目标。现有方法的痛点在于,它们容易受到数据集中对象-动作配对偏差以及第一人称视角视频中常见的快速运动、遮挡等视觉混淆因素的影响,导致模型学习到虚假相关性,泛化能力差。
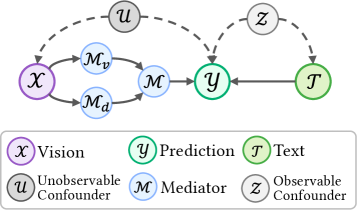
核心思路:CERES的核心思路是通过因果干预来消除或减轻这些偏差和混淆因素的影响。具体来说,它采用双模态干预策略:一是通过后门调整消除语言表示中的偏差,二是通过前门调整解决视觉混淆问题。这样设计的目的是使模型能够学习到更本质的因果关系,从而提高其在复杂环境下的鲁棒性。
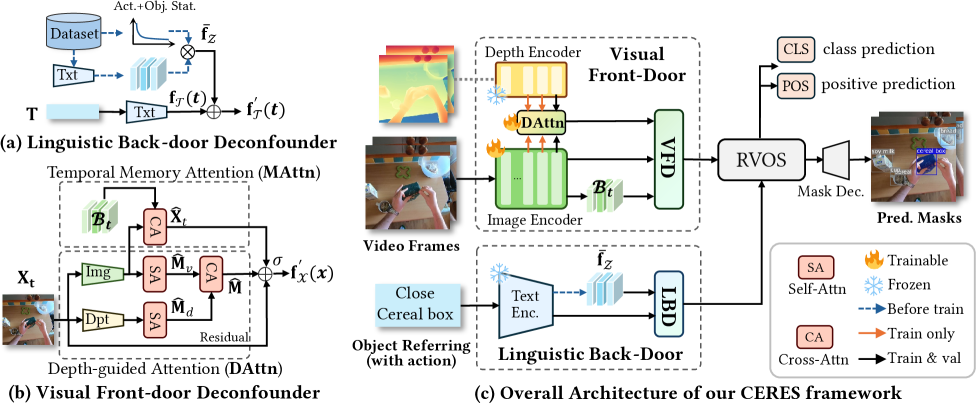
技术框架:CERES是一个即插即用的框架,可以与现有的RVOS骨干网络结合使用。其主要包含两个模块:语言偏差消除模块和视觉混淆消除模块。语言偏差消除模块通过后门调整,干预语言表示,使其与数据集中的偏差解耦。视觉混淆消除模块则利用前门调整,将语义视觉特征与几何深度信息融合,从而消除视觉混淆因素的影响。整体流程是先进行语言偏差消除,再进行视觉混淆消除,最后进行目标分割。
关键创新:CERES最重要的创新点在于将因果推理引入到Ego-RVOS任务中,并提出了双模态因果干预策略。与现有方法不同,CERES不是简单地学习数据中的相关性,而是试图理解数据背后的因果关系,从而构建更鲁棒的模型。通过后门调整和前门调整,分别解决了语言偏差和视觉混淆问题,这是现有方法所忽略的。
关键设计:在语言偏差消除模块中,具体实现后门调整的方法未知。在视觉混淆消除模块中,语义视觉特征和几何深度信息的融合方式未知。损失函数的设计也未知,但推测会包含分割损失和一些正则化项,以鼓励模型学习到更合理的因果关系。
🖼️ 关键图片
📊 实验亮点
CERES在Ego-RVOS基准测试中取得了state-of-the-art的性能,证明了其有效性。具体的性能数据和提升幅度在论文中给出,但摘要中未明确提及。该研究表明,通过因果推理可以显著提升Ego-RVOS任务的性能,为该领域的研究提供了新的思路。
🎯 应用场景
该研究成果可应用于智能辅助、人机交互、机器人导航等领域。例如,在智能助手中,可以帮助理解用户的意图,从而更准确地执行任务;在机器人导航中,可以帮助机器人更好地理解周围环境,从而更安全地进行导航。未来,该技术有望推动以人为中心的智能系统发展。
📄 摘要(原文)
Egocentric Referring Video Object Segmentation (Ego-RVOS) aims to segment the specific object actively involved in a human action, as described by a language query, within first-person videos. This task is critical for understanding egocentric human behavior. However, achieving such segmentation robustly is challenging due to ambiguities inherent in egocentric videos and biases present in training data. Consequently, existing methods often struggle, learning spurious correlations from skewed object-action pairings in datasets and fundamental visual confounding factors of the egocentric perspective, such as rapid motion and frequent occlusions. To address these limitations, we introduce Causal Ego-REferring Segmentation (CERES), a plug-in causal framework that adapts strong, pre-trained RVOS backbones to the egocentric domain. CERES implements dual-modal causal intervention: applying backdoor adjustment principles to counteract language representation biases learned from dataset statistics, and leveraging front-door adjustment concepts to address visual confounding by intelligently integrating semantic visual features with geometric depth information guided by causal principles, creating representations more robust to egocentric distortions. Extensive experiments demonstrate that CERES achieves state-of-the-art performance on Ego-RVOS benchmarks, highlighting the potential of applying causal reasoning to build more reliable models for broader egocentric video understanding.