Virtual-Eyes: Quantitative Validation of a Lung CT Quality-Control Pipeline for Foundation-Model Cancer Risk Prediction
作者: Md. Enamul Hoq, Linda Larson-Prior, Fred Prior
分类: cs.CV, cs.AI
发布日期: 2025-12-30
备注: 23 pages, and Under Review-MIDL-2026
💡 一句话要点
Virtual-Eyes:用于肺癌风险预测的CT质量控制流程,提升通用基础模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 肺癌筛查 低剂量CT 质量控制 深度学习 医学影像分析
📋 核心要点
- 现有低剂量CT肺癌筛查的深度学习流程中,预处理步骤缺乏量化评估,影响模型性能。
- 提出Virtual-Eyes质量控制流程,通过标准化图像分辨率、剔除不合格序列和提取肺部区域,提升数据质量。
- 实验表明,Virtual-Eyes能显著提升通用基础模型RAD-DINO的性能,但可能降低专用模型的性能。
📝 摘要(中文)
在低剂量CT(LDCT)肺癌筛查的深度学习流程中,稳健的预处理很少被量化。本文开发并验证了Virtual-Eyes,一个临床驱动的16位CT质量控制流程,并测量了它对通用基础模型与专用模型产生的差异性影响。Virtual-Eyes强制执行严格的512x512平面分辨率,拒绝短序列或非诊断序列,并使用Hounsfield单位滤波和双侧肺覆盖评分提取连续的肺部块,同时保留原始的16位网格。使用765名NLST患者(182名癌症患者,583名非癌症患者),我们从RAD-DINO和Merlin计算切片级别的嵌入,使用冻结的编码器并训练无泄漏的患者级别MLP头;我们还在Raw与Virtual-Eyes输入下评估了Sybil和一个2D ResNet-18基线,而无需骨干网络再训练。Virtual-Eyes将RAD-DINO切片级别AUC从0.576提高到0.610,患者级别AUC从0.646提高到0.683(均值池化),从0.619提高到0.735(最大池化),并改善了校准(Brier分数从0.188降至0.112)。相反,Sybil和ResNet-18在Virtual-Eyes下性能下降(Sybil AUC从0.886降至0.837;ResNet-18 AUC从0.571降至0.596),并存在上下文依赖性和捷径学习的证据,Merlin显示出有限的可迁移性(AUC约为0.507至0.567),无论预处理如何。这些结果表明,以解剖学为目标的QC可以稳定和改进通用基础模型工作流程,但可能会扰乱适应原始临床上下文的专用模型。
🔬 方法详解
问题定义:现有基于深度学习的低剂量CT肺癌筛查流程,在数据预处理阶段缺乏标准化的质量控制,导致模型训练数据质量参差不齐,影响模型的泛化能力和预测准确性。现有方法往往依赖于原始的临床数据,而这些数据可能包含噪声、伪影以及不一致的扫描参数,从而影响模型的性能。
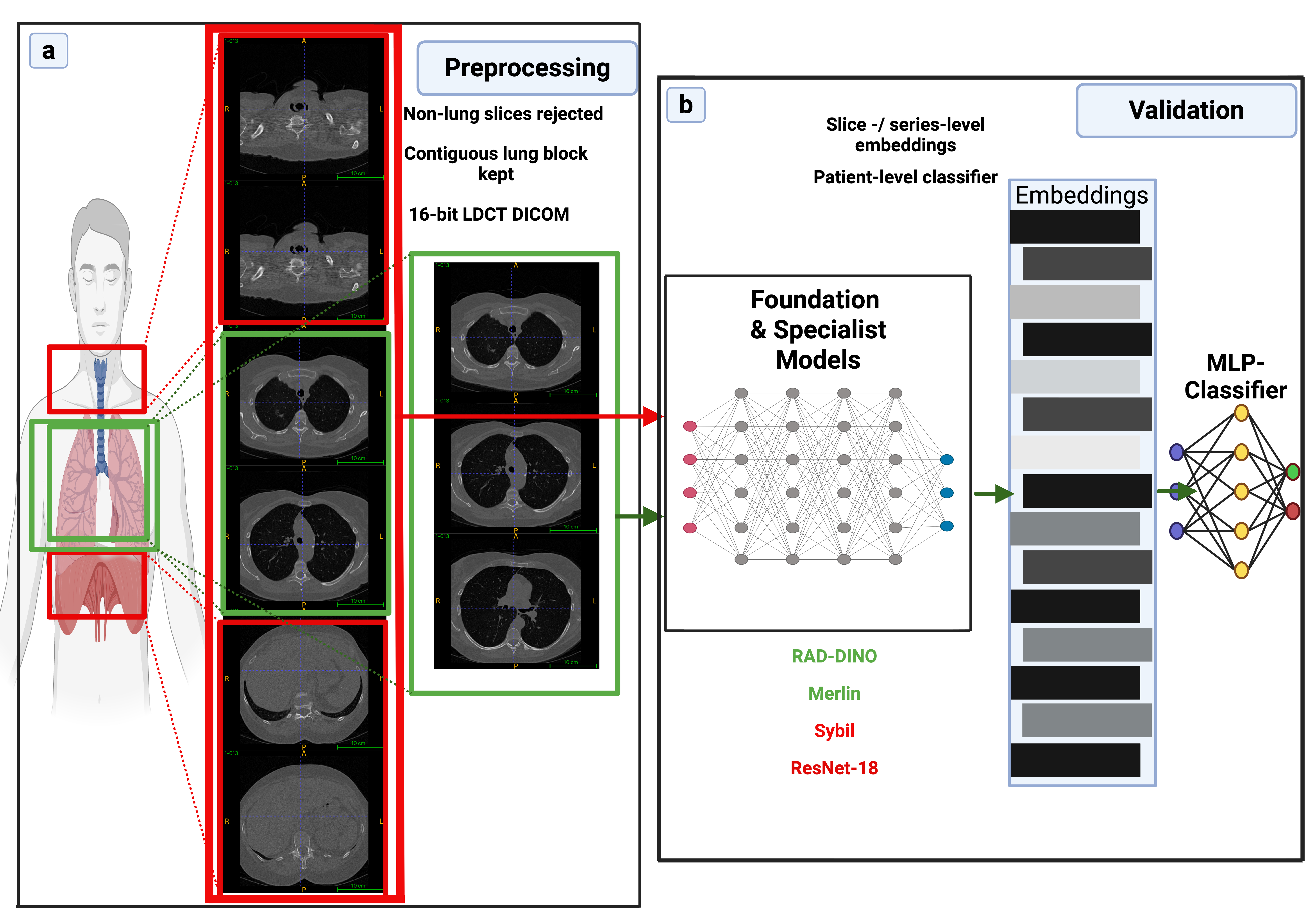
核心思路:论文的核心思路是开发一个名为Virtual-Eyes的CT质量控制流程,该流程旨在通过一系列严格的图像处理步骤,标准化CT图像的质量,从而提高深度学习模型在肺癌风险预测任务中的性能。该流程的核心在于提取高质量的肺部区域,并消除不相关的图像信息,从而使模型能够更专注于学习与肺癌相关的特征。
技术框架:Virtual-Eyes流程主要包含以下几个阶段:1) 图像标准化:强制将CT图像的分辨率调整为512x512,确保输入图像的尺寸一致。2) 序列筛选:剔除短序列或非诊断序列,保证输入数据的有效性。3) 肺部区域提取:使用Hounsfield单位滤波和双侧肺覆盖评分提取连续的肺部块,保留原始的16位灰度信息。4) 模型评估:使用经过Virtual-Eyes处理后的数据,评估通用基础模型(RAD-DINO、Merlin)和专用模型(Sybil、ResNet-18)在肺癌风险预测任务中的性能。
关键创新:该论文的关键创新在于提出了一个专门针对肺部CT图像的质量控制流程,该流程能够有效地提高通用基础模型在肺癌风险预测任务中的性能。与现有方法相比,Virtual-Eyes更加注重图像的标准化和肺部区域的提取,从而使模型能够更好地学习与肺癌相关的特征。此外,该论文还对比了Virtual-Eyes对通用基础模型和专用模型的影响,发现Virtual-Eyes能够提升通用基础模型的性能,但可能会降低专用模型的性能。
关键设计:Virtual-Eyes流程中的关键设计包括:1) 使用Hounsfield单位滤波来分割肺部区域,该方法能够有效地去除肺部周围的组织和噪声。2) 使用双侧肺覆盖评分来评估肺部区域的完整性,确保提取的肺部区域包含完整的肺部结构。3) 保留原始的16位灰度信息,避免信息损失。4) 使用冻结的编码器和无泄漏的患者级别MLP头来训练模型,避免过拟合和数据泄露。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Virtual-Eyes显著提升了RAD-DINO模型的性能,切片级别AUC从0.576提高到0.610,患者级别AUC(最大池化)从0.619提高到0.735,Brier分数从0.188降低到0.112,表明模型校准得到改善。然而,Virtual-Eyes对Sybil和ResNet-18等专用模型产生了负面影响,表明这些模型可能过度依赖原始数据的上下文信息。
🎯 应用场景
该研究成果可应用于肺癌早期筛查和诊断,通过提升CT图像质量,提高AI辅助诊断的准确性和可靠性。该流程可以集成到现有的医学影像分析系统中,辅助医生进行更准确的肺癌风险评估,从而改善患者的预后。未来,该方法有望推广到其他疾病的影像分析中,提升医疗影像AI的应用价值。
📄 摘要(原文)
Robust preprocessing is rarely quantified in deep-learning pipelines for low-dose CT (LDCT) lung cancer screening. We develop and validate Virtual-Eyes, a clinically motivated 16-bit CT quality-control pipeline, and measure its differential impact on generalist foundation models versus specialist models. Virtual-Eyes enforces strict 512x512 in-plane resolution, rejects short or non-diagnostic series, and extracts a contiguous lung block using Hounsfield-unit filtering and bilateral lung-coverage scoring while preserving the native 16-bit grid. Using 765 NLST patients (182 cancer, 583 non-cancer), we compute slice-level embeddings from RAD-DINO and Merlin with frozen encoders and train leakage-free patient-level MLP heads; we also evaluate Sybil and a 2D ResNet-18 baseline under Raw versus Virtual-Eyes inputs without backbone retraining. Virtual-Eyes improves RAD-DINO slice-level AUC from 0.576 to 0.610 and patient-level AUC from 0.646 to 0.683 (mean pooling) and from 0.619 to 0.735 (max pooling), with improved calibration (Brier score 0.188 to 0.112). In contrast, Sybil and ResNet-18 degrade under Virtual-Eyes (Sybil AUC 0.886 to 0.837; ResNet-18 AUC 0.571 to 0.596) with evidence of context dependence and shortcut learning, and Merlin shows limited transferability (AUC approximately 0.507 to 0.567) regardless of preprocessing. These results demonstrate that anatomically targeted QC can stabilize and improve generalist foundation-model workflows but may disrupt specialist models adapted to raw clinical context.