MambaSeg: Harnessing Mamba for Accurate and Efficient Image-Event Semantic Segmentation
作者: Fuqiang Gu, Yuanke Li, Xianlei Long, Kangping Ji, Chao Chen, Qingyi Gu, Zhenliang Ni
分类: cs.CV
发布日期: 2025-12-30
备注: Accepted by AAAI 2026
💡 一句话要点
提出MambaSeg,利用Mamba架构实现高效准确的图像-事件语义分割
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语义分割 事件相机 多模态融合 Mamba架构 时间序列建模
📋 核心要点
- 传统RGB图像语义分割在光照不足或快速运动场景下表现不佳,事件相机虽有高时间分辨率,但缺乏颜色纹理信息。
- MambaSeg采用双分支结构,并行使用Mamba编码器处理RGB图像和事件流,并设计双维度交互模块进行跨模态融合。
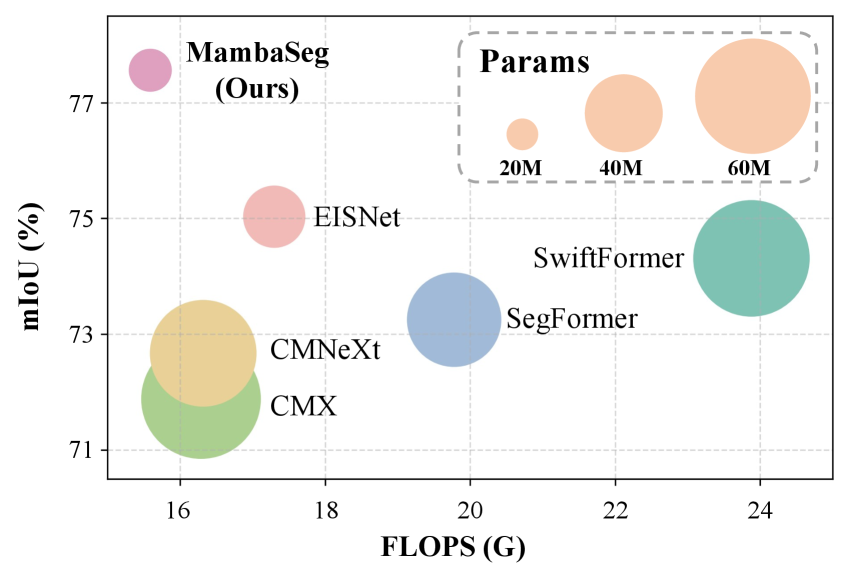
- 实验结果表明,MambaSeg在DDD17和DSEC数据集上取得了SOTA性能,并显著降低了计算成本。
📝 摘要(中文)
语义分割是计算机视觉中的一项基本任务,在自动驾驶和机器人等领域有着广泛的应用。虽然基于RGB的方法通过CNN和Transformer取得了强大的性能,但由于帧相机的局限性,它们在快速运动、低光照或高动态范围条件下效果会降低。事件相机提供了高时间分辨率和低延迟等互补优势,但缺乏颜色和纹理,使其自身不足以胜任任务。为了解决这个问题,最近的研究探索了RGB和事件数据的多模态融合;然而,许多现有方法计算成本高昂,并且主要关注空间融合,忽略了事件流中固有的时间动态。在这项工作中,我们提出了MambaSeg,一种新颖的双分支语义分割框架,它采用并行的Mamba编码器来有效地建模RGB图像和事件流。为了减少跨模态歧义,我们引入了双维度交互模块(DDIM),包括跨空间交互模块(CSIM)和跨时间交互模块(CTIM),它们共同执行沿空间和时间维度的细粒度融合。这种设计改进了跨模态对齐,减少了歧义,并利用了每种模态的互补特性。在DDD17和DSEC数据集上的大量实验表明,MambaSeg实现了最先进的分割性能,同时显著降低了计算成本,展示了其在高效、可扩展和鲁棒的多模态感知方面的潜力。
🔬 方法详解
问题定义:论文旨在解决RGB图像在恶劣光照和快速运动场景下语义分割性能下降的问题,以及事件相机缺乏颜色纹理信息的问题。现有方法通常计算成本高昂,且侧重于空间融合,忽略了事件流的时间动态信息,导致分割精度受限。
核心思路:论文的核心思路是利用Mamba架构高效建模RGB图像和事件流,并通过提出的双维度交互模块(DDIM)在空间和时间维度上进行细粒度融合,从而充分利用两种模态的互补信息,提高分割精度和效率。Mamba架构的序列建模能力使其能够有效捕捉事件流中的时间动态信息。
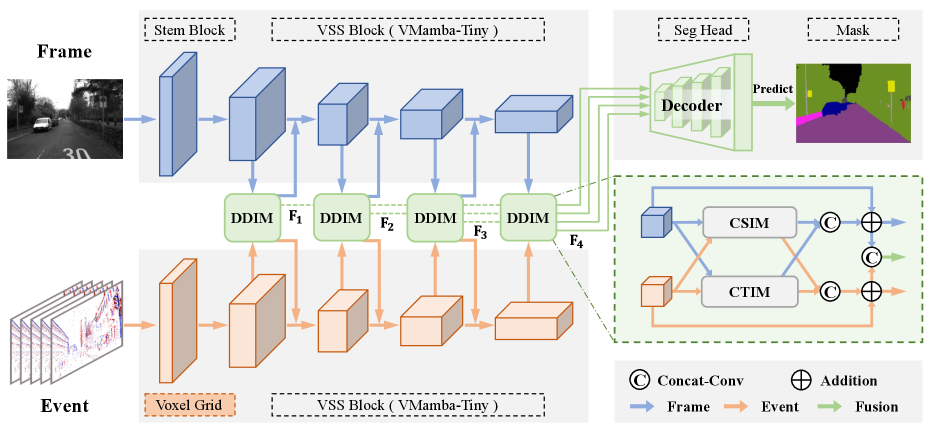
技术框架:MambaSeg采用双分支编码器-解码器结构。两个分支分别处理RGB图像和事件流,均采用Mamba作为主要编码器。编码后的特征通过DDIM进行跨模态融合。DDIM包含跨空间交互模块(CSIM)和跨时间交互模块(CTIM),分别在空间和时间维度上进行特征交互。最后,解码器将融合后的特征映射到像素级别的语义分割结果。
关键创新:论文的关键创新在于:1) 将Mamba架构引入多模态语义分割任务,利用其高效的序列建模能力处理事件流;2) 提出了双维度交互模块(DDIM),实现了空间和时间维度上的细粒度跨模态融合,有效减少了模态间的歧义,提升了分割精度。
关键设计:DDIM模块是关键设计之一,它包含CSIM和CTIM。CSIM通过注意力机制在空间维度上进行特征交互,CTIM则利用Mamba架构在时间维度上进行特征融合。具体参数设置和损失函数等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
MambaSeg在DDD17和DSEC数据集上取得了state-of-the-art的分割性能,同时显著降低了计算成本。具体性能数据和对比基线在论文中进行了详细展示,但具体提升幅度未知。实验结果表明,MambaSeg在效率和精度上都优于现有方法。
🎯 应用场景
MambaSeg具有广泛的应用前景,尤其是在自动驾驶、机器人导航、智能监控等领域。该方法能够有效应对恶劣光照和快速运动等挑战性场景,提高系统的鲁棒性和可靠性。未来,可以进一步探索MambaSeg在其他多模态感知任务中的应用,例如目标检测、场景理解等。
📄 摘要(原文)
Semantic segmentation is a fundamental task in computer vision with wide-ranging applications, including autonomous driving and robotics. While RGB-based methods have achieved strong performance with CNNs and Transformers, their effectiveness degrades under fast motion, low-light, or high dynamic range conditions due to limitations of frame cameras. Event cameras offer complementary advantages such as high temporal resolution and low latency, yet lack color and texture, making them insufficient on their own. To address this, recent research has explored multimodal fusion of RGB and event data; however, many existing approaches are computationally expensive and focus primarily on spatial fusion, neglecting the temporal dynamics inherent in event streams. In this work, we propose MambaSeg, a novel dual-branch semantic segmentation framework that employs parallel Mamba encoders to efficiently model RGB images and event streams. To reduce cross-modal ambiguity, we introduce the Dual-Dimensional Interaction Module (DDIM), comprising a Cross-Spatial Interaction Module (CSIM) and a Cross-Temporal Interaction Module (CTIM), which jointly perform fine-grained fusion along both spatial and temporal dimensions. This design improves cross-modal alignment, reduces ambiguity, and leverages the complementary properties of each modality. Extensive experiments on the DDD17 and DSEC datasets demonstrate that MambaSeg achieves state-of-the-art segmentation performance while significantly reducing computational cost, showcasing its promise for efficient, scalable, and robust multimodal perception.