Guiding a Diffusion Transformer with the Internal Dynamics of Itself
作者: Xingyu Zhou, Qifan Li, Xiaobin Hu, Hai Chen, Shuhang Gu
分类: cs.CV, cs.LG
发布日期: 2025-12-30
备注: Project Page: https://zhouxingyu13.github.io/Internal-Guidance/
💡 一句话要点
提出内部引导(IG)策略,提升扩散Transformer的图像生成质量与训练效率。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 扩散模型 Transformer 图像生成 内部引导 辅助监督
📋 核心要点
- 现有扩散模型在低概率区域生成高质量图像时存在困难,需要额外的引导策略。
- 论文提出内部引导(IG)策略,通过在训练时对中间层进行辅助监督,提升生成质量。
- 实验表明,IG策略在ImageNet上显著提升了FID指标,并取得了当前最佳性能。
📝 摘要(中文)
扩散模型在捕获完整(条件)数据分布方面表现出强大的能力。然而,由于缺乏足够的训练和数据来学习覆盖低概率区域,模型在生成对应于这些区域的高质量图像时会受到惩罚。为了实现更好的生成质量,诸如无分类器引导(CFG)之类的引导策略可以在采样阶段将样本引导到高概率区域。然而,标准的CFG通常会导致过度简化或失真的样本。另一方面,使用其不良版本引导扩散模型的替代方案受到精心设计的退化策略、额外的训练和额外的采样步骤的限制。在本文中,我们提出了一种简单而有效的策略,即内部引导(IG),它在训练过程中引入了对中间层的辅助监督,并在采样过程中推断中间层和深层层的输出以获得生成结果。这种简单的策略在各种基线上都显著提高了训练效率和生成质量。在ImageNet 256x256上,SiT-XL/2+IG在80和800个epoch时分别实现了FID=5.31和FID=1.75。更令人印象深刻的是,LightningDiT-XL/1+IG实现了FID=1.34,这在所有这些方法之间都实现了很大的差距。结合CFG,LightningDiT-XL/1+IG实现了当前最先进的FID,为1.19。
🔬 方法详解
问题定义:扩散模型在生成图像时,由于训练数据和模型容量的限制,难以覆盖数据分布中的低概率区域,导致生成质量下降。现有的引导策略,如CFG,容易导致样本过度简化或失真。而基于“坏版本”的引导方法则需要额外的训练和采样步骤,增加了计算负担。
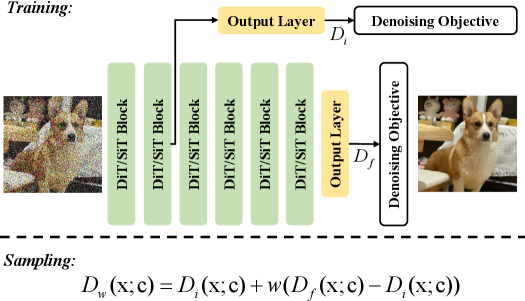
核心思路:论文的核心思路是在训练过程中,利用模型自身的中间层信息作为辅助监督信号,引导模型更好地学习数据分布。在采样阶段,则利用中间层和深层层的输出进行推断,从而生成更高质量的图像。这种方法无需额外的训练或复杂的退化策略,实现简单且有效。
技术框架:该方法主要包含两个阶段:训练阶段和采样阶段。在训练阶段,除了标准的扩散模型训练目标外,还引入了对中间层输出的辅助监督。在采样阶段,利用训练好的模型,结合中间层和深层层的输出,通过一定的推断策略生成最终的图像。整体框架是在现有的扩散Transformer基础上,增加了一个中间层监督分支。
关键创新:该方法的关键创新在于利用模型自身的内部动态信息进行引导。与传统的外部引导方法不同,IG策略无需额外的模型或数据,而是充分利用了模型自身学习到的特征表示。这种内部引导的方式更加高效和自然,能够更好地提升生成质量。
关键设计:在训练阶段,中间层监督的具体实现方式未知,论文中没有详细描述。在采样阶段,如何有效地结合中间层和深层层的输出进行推断也是一个关键的设计点,具体实现方式未知。损失函数的设计可能包含一个标准的扩散模型损失和一个中间层监督损失,两者的权重需要仔细调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,提出的IG策略在ImageNet 256x256数据集上取得了显著的性能提升。SiT-XL/2+IG在80和800个epoch时分别实现了FID=5.31和FID=1.75。更令人印象深刻的是,LightningDiT-XL/1+IG实现了FID=1.34。结合CFG,LightningDiT-XL/1+IG实现了当前最先进的FID,为1.19,超越了现有方法。
🎯 应用场景
该研究成果可应用于图像生成、图像编辑、图像修复等领域。通过提升生成图像的质量和效率,可以为艺术创作、内容生成、虚拟现实等应用提供更好的技术支持。未来,该方法有望推广到其他生成模型和数据类型,例如音频、视频等。
📄 摘要(原文)
The diffusion model presents a powerful ability to capture the entire (conditional) data distribution. However, due to the lack of sufficient training and data to learn to cover low-probability areas, the model will be penalized for failing to generate high-quality images corresponding to these areas. To achieve better generation quality, guidance strategies such as classifier free guidance (CFG) can guide the samples to the high-probability areas during the sampling stage. However, the standard CFG often leads to over-simplified or distorted samples. On the other hand, the alternative line of guiding diffusion model with its bad version is limited by carefully designed degradation strategies, extra training and additional sampling steps. In this paper, we proposed a simple yet effective strategy Internal Guidance (IG), which introduces an auxiliary supervision on the intermediate layer during training process and extrapolates the intermediate and deep layer's outputs to obtain generative results during sampling process. This simple strategy yields significant improvements in both training efficiency and generation quality on various baselines. On ImageNet 256x256, SiT-XL/2+IG achieves FID=5.31 and FID=1.75 at 80 and 800 epochs. More impressively, LightningDiT-XL/1+IG achieves FID=1.34 which achieves a large margin between all of these methods. Combined with CFG, LightningDiT-XL/1+IG achieves the current state-of-the-art FID of 1.19.