DiffThinker: Towards Generative Multimodal Reasoning with Diffusion Models
作者: Zefeng He, Xiaoye Qu, Yafu Li, Tong Zhu, Siyuan Huang, Yu Cheng
分类: cs.CV
发布日期: 2025-12-30
备注: Project page: https://diffthinker-project.github.io
💡 一句话要点
提出DiffThinker,利用扩散模型实现生成式多模态推理,提升视觉中心任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推理 扩散模型 生成式模型 视觉中心任务 图像生成 人工智能 机器人 空间推理
📋 核心要点
- 现有多模态大语言模型在复杂、长程、视觉中心任务中,由于推理过程主要以文本为中心,导致性能欠佳。
- DiffThinker将多模态推理转化为图像到图像的生成任务,利用扩散模型生成视觉表征,从而提升逻辑一致性和空间精度。
- 实验表明,DiffThinker在多个视觉推理任务上显著优于现有模型,包括GPT-5和Gemini-3-Flash等,提升幅度显著。
📝 摘要(中文)
本文提出了一种新的生成式多模态推理范式,并引入了基于扩散模型的推理框架DiffThinker。与现有以文本为中心的多模态大语言模型(MLLMs)不同,DiffThinker将多模态推理重新定义为一个原生的图像到图像生成任务,从而在视觉中心任务中实现更好的逻辑一致性和空间精确性。论文系统地比较了DiffThinker和MLLMs,深入研究了该范式的内在特性,揭示了效率、可控性、原生并行性和协作性四个核心属性。在顺序规划、组合优化、约束满足和空间配置四个领域的广泛实验表明,DiffThinker显著优于包括GPT-5(+314.2%)和Gemini-3-Flash(+111.6%)在内的领先闭源模型,以及微调后的Qwen3-VL-32B基线(+39.0%),突出了生成式多模态推理作为视觉中心推理的一种有前景的方法。
🔬 方法详解
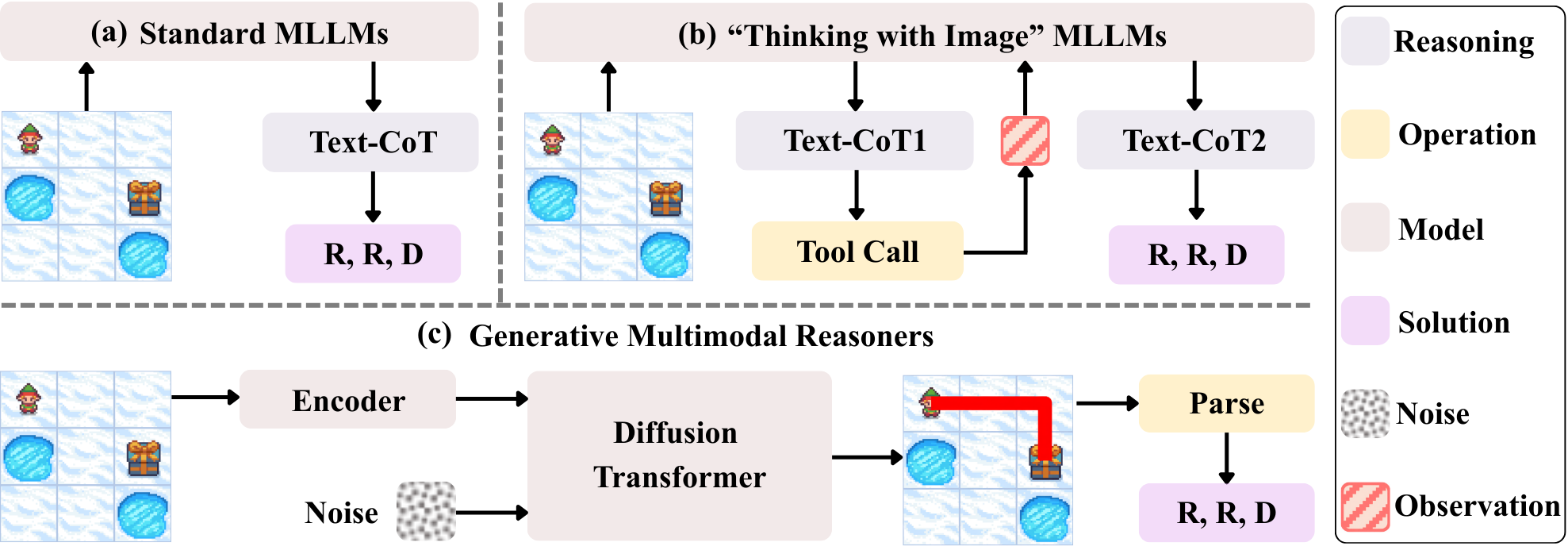
问题定义:现有Multimodal Large Language Models (MLLMs) 在处理复杂的、长时程的、以视觉为中心的任务时,由于其推理过程主要依赖于文本,导致性能受限。这些模型在视觉信息的理解和利用上存在瓶颈,难以实现精确的空间推理和逻辑一致性。
核心思路:DiffThinker的核心思路是将多模态推理问题转化为一个原生的图像到图像生成任务。通过利用扩散模型强大的生成能力,直接从输入图像生成推理结果图像,避免了文本模态的中间转换,从而更好地保留了视觉信息,提升了空间推理的准确性。
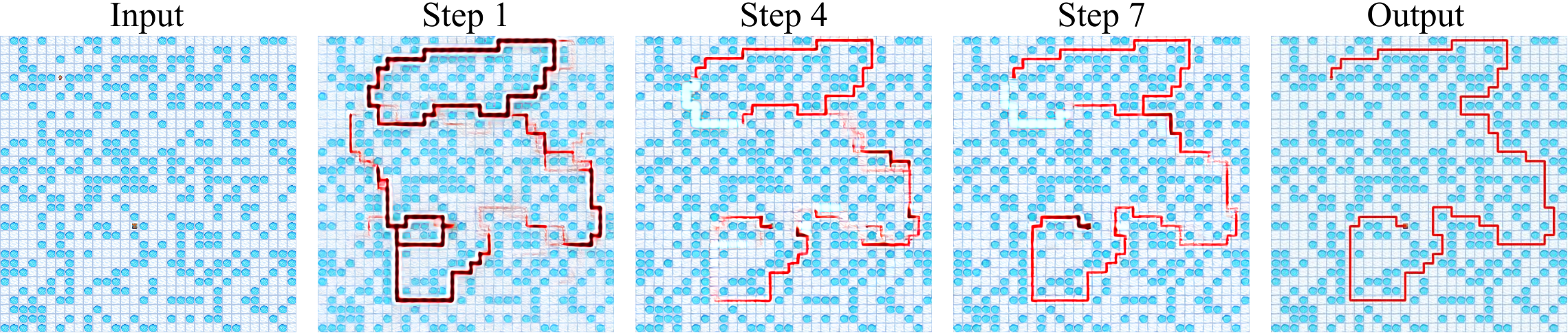
技术框架:DiffThinker的整体框架包括以下几个主要阶段:1) 输入编码:将多模态输入(例如,初始图像和文本指令)编码成统一的视觉表征。2) 扩散过程:利用扩散模型逐步向编码后的视觉表征添加噪声,将其转化为纯噪声。3) 逆扩散过程:通过迭代的去噪过程,从噪声中逐步恢复出推理结果图像,该过程受到文本指令的引导。4) 输出解码:将生成的图像解码为最终的推理结果。
关键创新:DiffThinker最重要的创新在于其将多模态推理问题重新定义为一个生成式图像到图像的任务。与传统的以文本为中心的MLLMs不同,DiffThinker直接在视觉空间进行推理,避免了文本模态的信息损失和偏差。此外,利用扩散模型强大的生成能力,可以生成高质量、逻辑一致的推理结果。
关键设计:DiffThinker的关键设计包括:1) 扩散模型的选择:可以使用不同的扩散模型架构,例如DDPM、DDIM等,以适应不同的任务需求。2) 文本引导:通过交叉注意力机制或条件扩散等技术,将文本指令融入到逆扩散过程中,引导图像生成。3) 损失函数:可以使用像素级别的损失函数(例如L1损失、L2损失)或感知损失函数(例如VGG损失)来优化生成图像的质量。4) 采样策略:可以使用不同的采样策略(例如DDIM采样、PLMS采样)来加速生成过程。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DiffThinker在顺序规划、组合优化、约束满足和空间配置四个领域显著优于现有模型。例如,DiffThinker在某些任务上比GPT-5提升了314.2%,比Gemini-3-Flash提升了111.6%,比微调后的Qwen3-VL-32B基线提升了39.0%。这些结果表明,生成式多模态推理是一种很有前途的视觉中心推理方法。
🎯 应用场景
DiffThinker具有广泛的应用前景,例如机器人导航、智能家居、自动驾驶、游戏AI等。它可以用于解决需要复杂视觉推理的任务,例如根据指令规划机器人的运动轨迹、根据用户需求生成室内设计方案、根据交通状况预测车辆行驶路径等。该研究有望推动多模态人工智能的发展,实现更智能、更可靠的视觉中心应用。
📄 摘要(原文)
While recent Multimodal Large Language Models (MLLMs) have attained significant strides in multimodal reasoning, their reasoning processes remain predominantly text-centric, leading to suboptimal performance in complex long-horizon, vision-centric tasks. In this paper, we establish a novel Generative Multimodal Reasoning paradigm and introduce DiffThinker, a diffusion-based reasoning framework. Conceptually, DiffThinker reformulates multimodal reasoning as a native generative image-to-image task, achieving superior logical consistency and spatial precision in vision-centric tasks. We perform a systematic comparison between DiffThinker and MLLMs, providing the first in-depth investigation into the intrinsic characteristics of this paradigm, revealing four core properties: efficiency, controllability, native parallelism, and collaboration. Extensive experiments across four domains (sequential planning, combinatorial optimization, constraint satisfaction, and spatial configuration) demonstrate that DiffThinker significantly outperforms leading closed source models including GPT-5 (+314.2\%) and Gemini-3-Flash (+111.6\%), as well as the fine-tuned Qwen3-VL-32B baseline (+39.0\%), highlighting generative multimodal reasoning as a promising approach for vision-centric reasoning.