Towards Open-Vocabulary Industrial Defect Understanding with a Large-Scale Multimodal Dataset
作者: TsaiChing Ni, ZhenQi Chen, YuanFu Yang
分类: cs.CV
发布日期: 2025-12-30 (更新: 2026-01-10)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出IMDD-1M大规模工业多模态缺陷数据集,用于开放词汇工业缺陷理解。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 工业缺陷检测 多模态学习 视觉-语言模型 扩散模型 大规模数据集
📋 核心要点
- 现有工业缺陷检测方法缺乏大规模多模态数据支持,限制了模型泛化能力和开放词汇理解能力。
- 构建大规模工业多模态缺陷数据集IMDD-1M,并训练基于扩散模型的视觉-语言基础模型。
- 实验表明,该模型仅需少量特定任务数据微调,即可达到与专用专家模型相当的性能。
📝 摘要(中文)
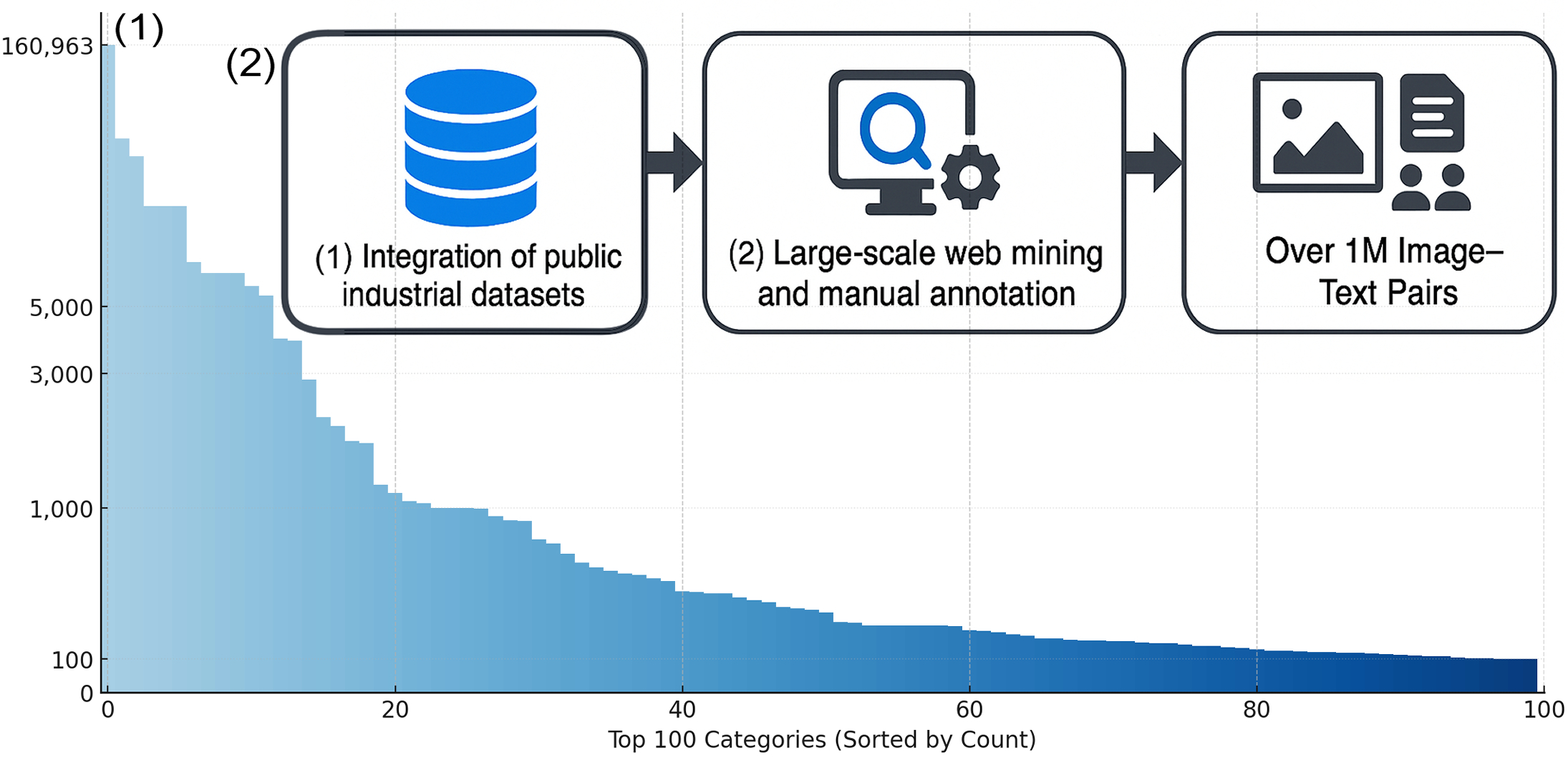
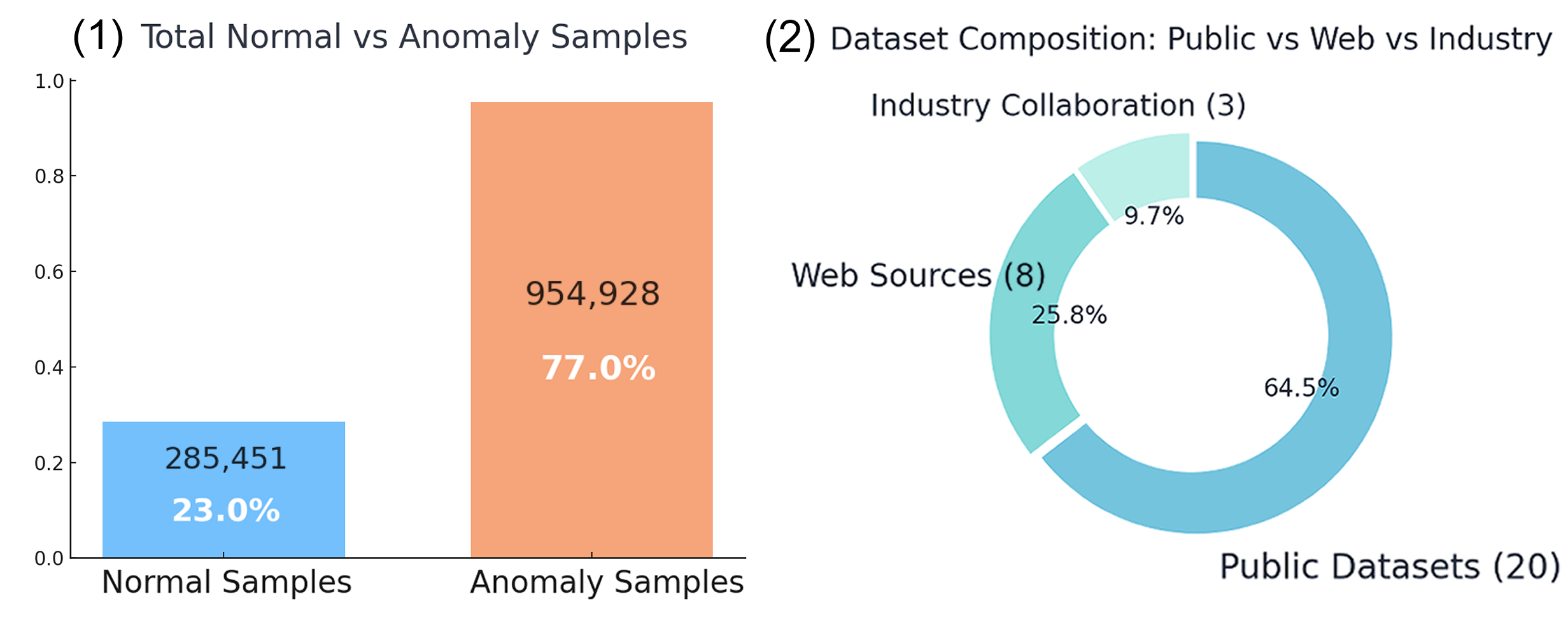
本文提出了IMDD-1M,首个大规模工业多模态缺陷数据集,包含100万个对齐的图像-文本对,旨在推进制造业和质量检测中的多模态学习。IMDD-1M包含高分辨率的真实缺陷图像,涵盖60多种材料类别和400多种缺陷类型,每个样本都附带有专家验证的标注和细粒度的文本描述,详细说明了缺陷位置、严重程度和上下文属性。该数据集支持广泛的应用,包括分类、分割、检索、图像描述和生成建模。基于IMDD-1M,我们从头开始训练了一个基于扩散的视觉-语言基础模型,专门为工业场景定制。该模型作为一个可泛化的基础,可以通过轻量级的微调有效地适应特定领域。仅需专用专家模型所需任务特定数据的5%以下,即可实现可比的性能,突出了数据高效的基础模型自适应在工业检测和生成方面的潜力,为可扩展的、领域自适应的和知识驱动的制造智能铺平了道路。
🔬 方法详解
问题定义:论文旨在解决工业缺陷检测中,由于缺乏大规模、多模态数据而导致的模型泛化能力不足和开放词汇理解困难的问题。现有方法通常依赖于特定领域的专家知识和少量标注数据,难以适应快速变化的工业场景和新型缺陷的识别。
核心思路:论文的核心思路是构建一个大规模的、包含图像和文本描述的多模态数据集,并在此基础上训练一个视觉-语言基础模型。通过预训练的方式,使模型能够学习到通用的视觉和语言特征,从而提高其在不同工业场景下的泛化能力和对新型缺陷的识别能力。
技术框架:整体框架包含两个主要部分:一是IMDD-1M数据集的构建,二是基于该数据集训练的视觉-语言基础模型。数据集构建过程包括数据收集、标注和验证等环节。视觉-语言基础模型采用基于扩散模型的架构,将图像和文本信息融合在一起进行训练。
关键创新:最重要的技术创新点在于构建了大规模的工业多模态缺陷数据集IMDD-1M,并利用该数据集训练了一个可泛化的视觉-语言基础模型。与现有方法相比,该方法不需要大量的特定领域标注数据,即可实现较好的性能,降低了模型部署和维护的成本。
关键设计:IMDD-1M数据集包含100万个图像-文本对,涵盖60多种材料类别和400多种缺陷类型。视觉-语言基础模型采用基于扩散模型的架构,具体网络结构和参数设置未知。损失函数的设计目标是使模型能够准确地将图像和文本信息关联起来,并生成高质量的缺陷描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于IMDD-1M训练的视觉-语言基础模型,仅需少量特定任务数据进行微调,即可达到与专用专家模型相当的性能。具体而言,该模型仅使用专用专家模型所需任务特定数据的5%以下,即可实现可比的性能,表明了数据高效的基础模型自适应在工业检测和生成方面的潜力。
🎯 应用场景
该研究成果可应用于智能制造、质量检测、工业自动化等领域。通过利用该数据集和基础模型,可以实现对各种工业产品的缺陷进行自动检测和诊断,提高生产效率和产品质量。未来,该研究还可以扩展到其他工业领域,例如航空航天、汽车制造等。
📄 摘要(原文)
We present IMDD-1M, the first large-scale Industrial Multimodal Defect Dataset comprising 1,000,000 aligned image-text pairs, designed to advance multimodal learning for manufacturing and quality inspection. IMDD-1M contains high-resolution real-world defects spanning over 60 material categories and more than 400 defect types, each accompanied by expert-verified annotations and fine-grained textual descriptions detailing defect location, severity, and contextual attributes. This dataset enables a wide spectrum of applications, including classification, segmentation, retrieval, captioning, and generative modeling. Building upon IMDD-1M, we train a diffusion-based vision-language foundation model from scratch, specifically tailored for industrial scenarios. The model serves as a generalizable foundation that can be efficiently adapted to specialized domains through lightweight fine-tuning. With less than 5% of the task-specific data required by dedicated expert models, it achieves comparable performance, highlighting the potential of data-efficient foundation model adaptation for industrial inspection and generation, paving the way for scalable, domain-adaptive, and knowledge-grounded manufacturing intelligence. Additional details and resources can be found in this URL: https://ninaneon.github.io/projectpage/