GeoBench: Rethinking Multimodal Geometric Problem-Solving via Hierarchical Evaluation
作者: Yuan Feng, Yue Yang, Xiaohan He, Jiatong Zhao, Jianlong Chen, Zijun Chen, Daocheng Fu, Qi Liu, Renqiu Xia, Bo Zhang, Junchi Yan
分类: cs.CV
发布日期: 2025-12-30
💡 一句话要点
GeoBench:通过分层评估重新思考多模态几何问题求解
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 几何问题求解 视觉语言模型 分层评估 基准测试 数学推理
📋 核心要点
- 现有VLM在几何推理方面存在数据污染、重结果轻过程和诊断粒度不足等问题。
- GeoBench通过分层基准测试,从视觉感知到自我反思,更全面地评估模型几何推理能力。
- 实验表明,子目标分解和过滤无关信息对提升几何问题求解至关重要,思维链提示效果不佳。
📝 摘要(中文)
几何问题求解是数学推理的一个关键分支,需要对形状和空间关系进行精确分析。目前对视觉语言模型(VLM)中几何推理的评估面临诸多限制,包括来自教科书的基准测试数据污染风险、过度强调最终答案而忽略推理过程,以及诊断粒度不足。为了解决这些问题,我们提出了GeoBench,这是一个分层基准,包含几何问题求解中的四个推理级别:视觉感知、目标导向规划、严格定理应用和自我反思回溯。通过TrustGeoGen生成的六个经过形式验证的任务,我们系统地评估了从属性提取到逻辑错误纠正的能力。实验表明,虽然像OpenAI-o3这样的推理模型优于一般的MLLM,但性能随着任务复杂性的增加而显著下降。关键发现表明,子目标分解和不相关前提过滤对最终问题求解的准确性至关重要,而思维链提示在某些任务中意外地降低了性能。这些发现将GeoBench确立为一个全面的基准,同时为开发几何问题求解系统提供了可操作的指导。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型(VLM)在几何问题求解中存在的评估不足问题。现有基准测试存在数据污染(来自教科书)、过度关注最终答案而忽略推理过程、以及诊断粒度不够精细的缺陷,难以全面评估模型的几何推理能力。
核心思路:论文的核心思路是构建一个分层的几何问题求解基准GeoBench,该基准包含四个推理级别:视觉感知、目标导向规划、严格定理应用和自我反思回溯。通过这种分层结构,可以更细粒度地评估模型在不同推理阶段的能力,从而更全面地了解模型的优势和不足。
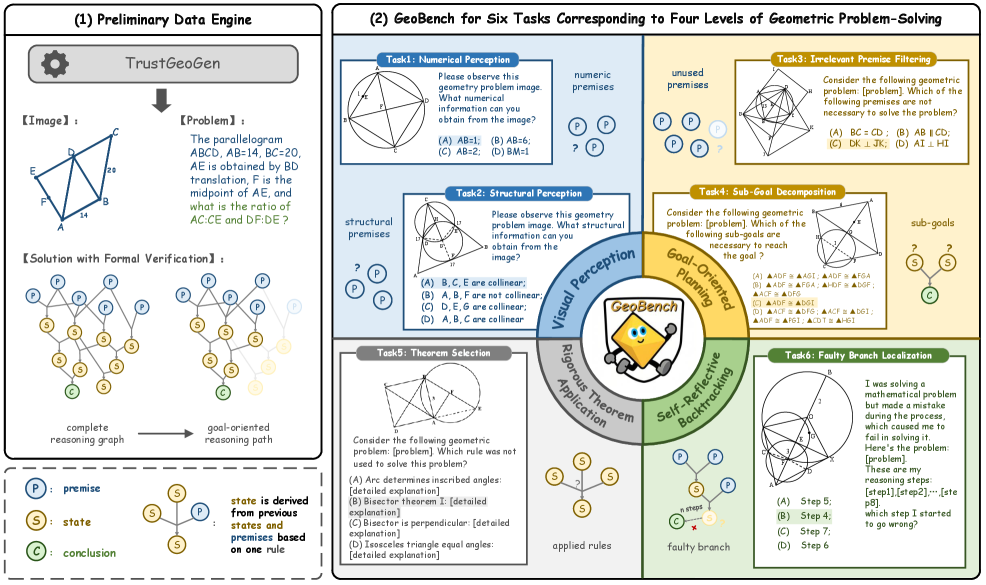
技术框架:GeoBench的技术框架主要包括以下几个部分:1) 使用TrustGeoGen生成六个经过形式验证的几何问题求解任务;2) 将每个任务分解为四个推理级别;3) 设计评估指标,用于衡量模型在每个推理级别的表现;4) 使用不同的VLM模型(如OpenAI-o3)在GeoBench上进行实验,分析模型在不同推理级别的表现。
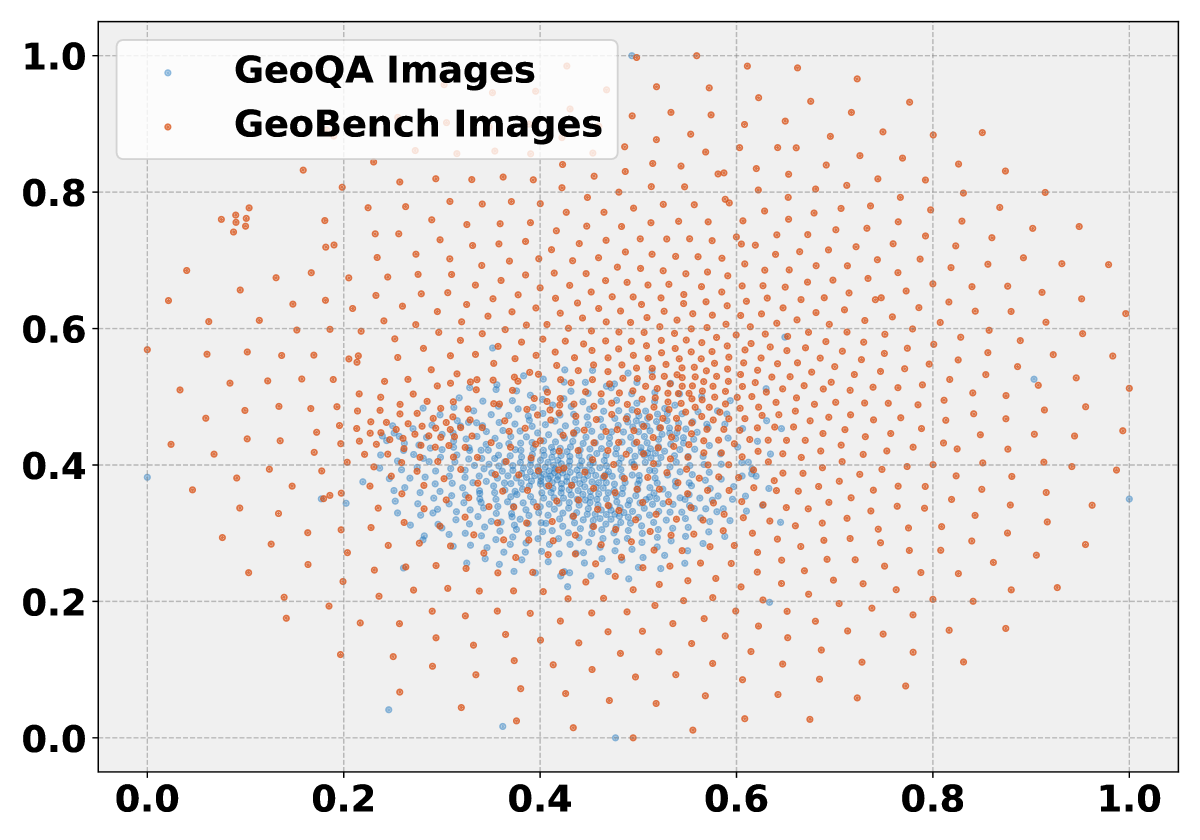
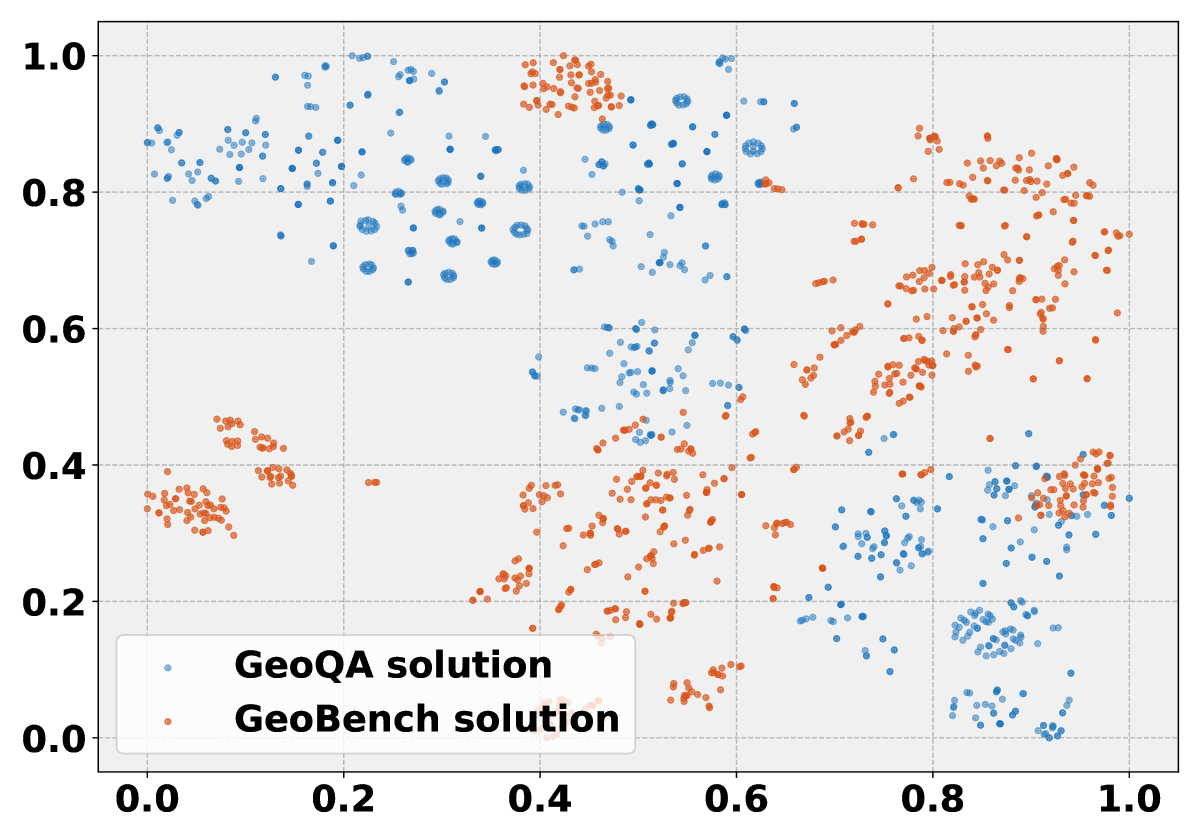
关键创新:GeoBench的关键创新在于其分层评估结构,它将几何问题求解分解为多个推理级别,从而可以更细粒度地评估模型的推理能力。此外,GeoBench使用TrustGeoGen生成经过形式验证的任务,避免了数据污染问题。
关键设计:GeoBench的关键设计包括:1) 四个推理级别的定义:视觉感知、目标导向规划、严格定理应用和自我反思回溯;2) TrustGeoGen生成的任务类型;3) 评估指标的设计,例如准确率、召回率等;4) 实验中使用的VLM模型和超参数设置。
🖼️ 关键图片
📊 实验亮点
实验结果表明,OpenAI-o3等推理模型在GeoBench上的表现优于一般的MLLM,但随着任务复杂性的增加,性能显著下降。子目标分解和不相关前提过滤对最终问题求解的准确性至关重要,而思维链提示在某些任务中意外地降低了性能。这些发现强调了模型在处理复杂几何问题时,需要更强的推理能力和更有效的策略。
🎯 应用场景
GeoBench可用于评估和改进视觉语言模型在几何问题求解方面的能力,推动VLM在数学教育、机器人导航、计算机辅助设计等领域的应用。通过更精确的几何推理,VLM可以更好地理解和操作现实世界,例如在自动驾驶中识别交通标志和道路结构,或在机器人操作中进行精确的物体定位和操作。
📄 摘要(原文)
Geometric problem solving constitutes a critical branch of mathematical reasoning, requiring precise analysis of shapes and spatial relationships. Current evaluations of geometric reasoning in vision-language models (VLMs) face limitations, including the risk of test data contamination from textbook-based benchmarks, overemphasis on final answers over reasoning processes, and insufficient diagnostic granularity. To address these issues, we present GeoBench, a hierarchical benchmark featuring four reasoning levels in geometric problem-solving: Visual Perception, Goal-Oriented Planning, Rigorous Theorem Application, and Self-Reflective Backtracking. Through six formally verified tasks generated via TrustGeoGen, we systematically assess capabilities ranging from attribute extraction to logical error correction. Experiments reveal that while reasoning models like OpenAI-o3 outperform general MLLMs, performance declines significantly with increasing task complexity. Key findings demonstrate that sub-goal decomposition and irrelevant premise filtering critically influence final problem-solving accuracy, whereas Chain-of-Thought prompting unexpectedly degrades performance in some tasks. These findings establish GeoBench as a comprehensive benchmark while offering actionable guidelines for developing geometric problem-solving systems.