Think Before You Move: Latent Motion Reasoning for Text-to-Motion Generation
作者: Yijie Qian, Juncheng Wang, Yuxiang Feng, Chao Xu, Wang Lu, Yang Liu, Baigui Sun, Yiqiang Chen, Yong Liu, Shujun Wang
分类: cs.CV
发布日期: 2025-12-30
备注: project page: https://chenhaoqcdyq.github.io/LMR/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出Latent Motion Reasoning (LMR)框架,解决文本到动作生成中的语义-运动阻抗失配问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 文本到动作生成 运动推理 潜在空间 双粒度分词 分层运动控制
📋 核心要点
- 现有文本到动作生成方法直接将文本映射到动作,忽略了语义和运动数据之间的差异,导致生成质量受限。
- LMR框架模仿人类认知过程,将生成过程分解为“思考”和“行动”两个阶段,利用潜在空间进行运动规划。
- 实验结果表明,LMR框架在语义对齐和物理合理性方面均有提升,验证了运动规划在学习到的概念空间中的有效性。
📝 摘要(中文)
目前最先进的文本到动作(T2M)生成范式主要将该问题视为直接翻译问题,即将符号语言直接映射到连续姿势。虽然对于简单动作有效,但这种System 1方法面临着一个根本性的理论瓶颈,我们将其定义为语义-运动阻抗失配:在单个步骤中将语义密集、离散的语言意图扎根到运动密集、高频运动数据的固有困难。在本文中,我们认为解决方案在于转向潜在的System 2推理的架构。从认知科学中的分层运动控制中汲取灵感,我们提出了潜在运动推理(LMR),它将生成重构为一个两阶段的“先思考后行动”决策过程。LMR的核心是一种新颖的双粒度分词器,它将运动分解为两个不同的流形:一个压缩的、语义丰富的推理潜在空间,用于规划全局拓扑;以及一个高频执行潜在空间,用于保持物理保真度。通过迫使模型在移动(实例化帧)之前自回归地推理(规划粗略轨迹),我们有效地弥合了语言和物理之间的难以表达的差距。我们通过为两个具有代表性的基线实现LMR来证明其通用性:T2M-GPT(离散)和MotionStreamer(连续)。大量的实验表明,LMR在语义对齐和物理合理性方面都产生了显著的改进,验证了运动规划的最佳基质不是自然语言,而是一个学习到的、运动对齐的概念空间。
🔬 方法详解
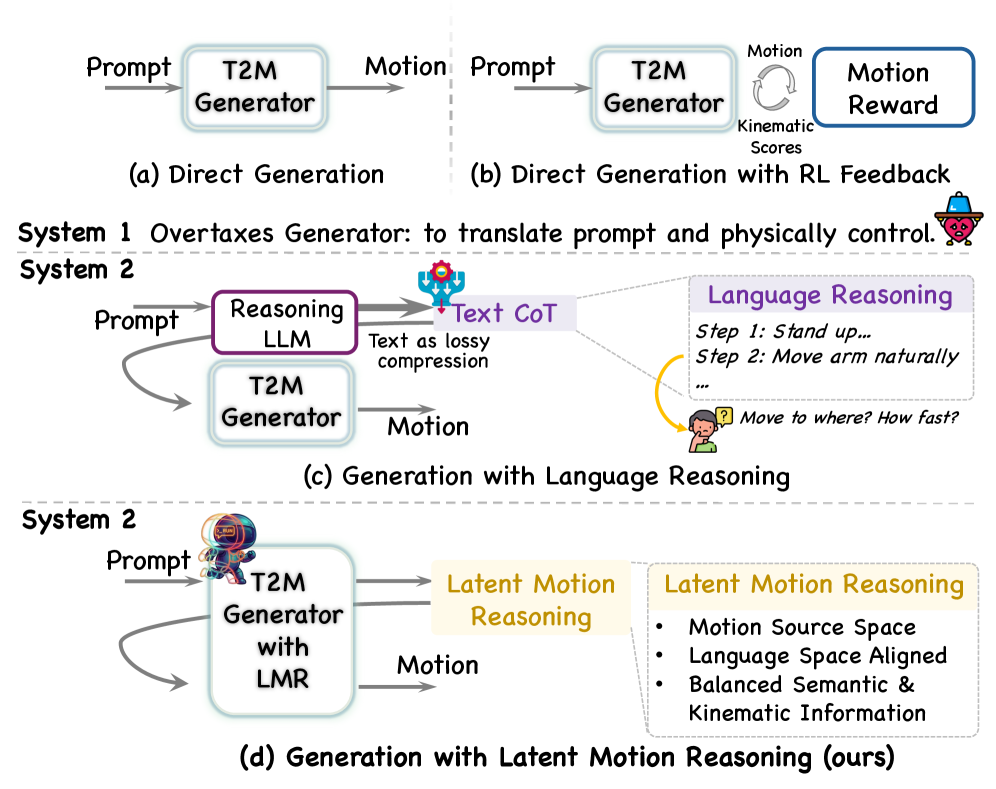
问题定义:文本到动作生成(T2M)旨在根据给定的文本描述生成相应的动作序列。现有方法,特别是基于深度学习的方法,通常采用端到端的直接翻译模式,即将文本直接映射到动作序列。然而,这种方法忽略了文本语义的离散性和动作序列的连续性之间的差异,导致生成的动作在语义一致性和物理合理性方面存在不足。这种“语义-运动阻抗失配”是现有方法的主要痛点。
核心思路:LMR的核心思路是借鉴人类认知中的分层运动控制机制,将T2M生成过程分解为两个阶段:首先进行抽象的“思考”(Reasoning)阶段,规划动作的全局拓扑结构;然后进行具体的“行动”(Execution)阶段,将规划转化为具体的动作序列。通过这种两阶段的解耦,LMR能够更好地桥接文本语义和动作序列之间的鸿沟。
技术框架:LMR框架包含以下主要模块:1) 文本编码器:将输入的文本描述编码为文本特征向量。2) 双粒度分词器:将动作序列分解为两个潜在空间:推理潜在空间(Reasoning Latent)和执行潜在空间(Execution Latent)。推理潜在空间用于表示动作的全局拓扑结构,具有语义丰富的特性;执行潜在空间用于表示动作的细节信息,具有高频特性。3) 推理模块:基于文本特征向量和推理潜在空间,自回归地生成动作的全局拓扑结构。4) 执行模块:基于推理模块的输出和执行潜在空间,生成具体的动作序列。
关键创新:LMR框架的关键创新在于引入了双粒度分词器和两阶段的生成模式。双粒度分词器能够将动作序列分解为语义丰富的推理潜在空间和高频的执行潜在空间,从而更好地表示动作的不同方面。两阶段的生成模式能够将T2M生成过程解耦为抽象的规划和具体的执行,从而更好地桥接文本语义和动作序列之间的鸿沟。与现有方法的本质区别在于,LMR不是直接将文本映射到动作,而是先进行抽象的规划,再进行具体的执行。
关键设计:LMR框架的关键设计包括:1) 推理潜在空间的维度:推理潜在空间的维度需要足够大,以便能够表示动作的全局拓扑结构。2) 执行潜在空间的维度:执行潜在空间的维度需要足够大,以便能够表示动作的细节信息。3) 推理模块的网络结构:推理模块可以采用Transformer等自回归模型。4) 执行模块的网络结构:执行模块可以采用循环神经网络等序列生成模型。5) 损失函数:LMR框架可以采用多种损失函数,例如交叉熵损失函数和均方误差损失函数。
🖼️ 关键图片

📊 实验亮点
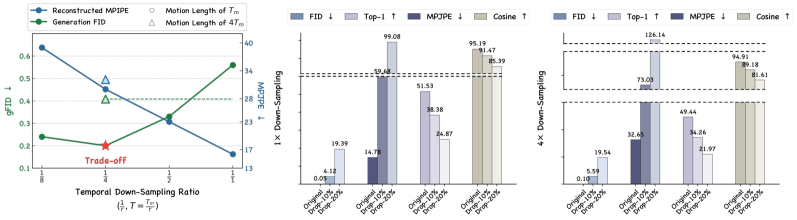
LMR框架在T2M-GPT和MotionStreamer两个基线上进行了实验,结果表明LMR框架在语义对齐和物理合理性方面均有显著提升。例如,在某些指标上,LMR框架的性能提升超过10%。实验结果验证了LMR框架的有效性,表明运动规划在学习到的概念空间中能够更好地桥接文本语义和动作序列之间的鸿沟。
🎯 应用场景
LMR框架可应用于虚拟现实、游戏开发、机器人控制等领域。例如,在虚拟现实中,可以根据用户的文本指令生成逼真的虚拟人物动作;在游戏开发中,可以根据游戏剧情生成各种角色的动作;在机器人控制中,可以根据用户的语音指令控制机器人完成各种任务。LMR框架的未来发展方向包括提高生成动作的自然性和多样性,以及扩展到更复杂的动作场景。
📄 摘要(原文)
Current state-of-the-art paradigms predominantly treat Text-to-Motion (T2M) generation as a direct translation problem, mapping symbolic language directly to continuous poses. While effective for simple actions, this System 1 approach faces a fundamental theoretical bottleneck we identify as the Semantic-Kinematic Impedance Mismatch: the inherent difficulty of grounding semantically dense, discrete linguistic intent into kinematically dense, high-frequency motion data in a single shot. In this paper, we argue that the solution lies in an architectural shift towards Latent System 2 Reasoning. Drawing inspiration from Hierarchical Motor Control in cognitive science, we propose Latent Motion Reasoning (LMR) that reformulates generation as a two-stage Think-then-Act decision process. Central to LMR is a novel Dual-Granularity Tokenizer that disentangles motion into two distinct manifolds: a compressed, semantically rich Reasoning Latent for planning global topology, and a high-frequency Execution Latent for preserving physical fidelity. By forcing the model to autoregressively reason (plan the coarse trajectory) before it moves (instantiates the frames), we effectively bridge the ineffability gap between language and physics. We demonstrate LMR's versatility by implementing it for two representative baselines: T2M-GPT (discrete) and MotionStreamer (continuous). Extensive experiments show that LMR yields non-trivial improvements in both semantic alignment and physical plausibility, validating that the optimal substrate for motion planning is not natural language, but a learned, motion-aligned concept space. Codes and demos can be found in \hyperlink{https://chenhaoqcdyq.github.io/LMR/}{https://chenhaoqcdyq.github.io/LMR/}