PipeFlow: Pipelined Processing and Motion-Aware Frame Selection for Long-Form Video Editing
作者: Mustafa Munir, Md Mostafijur Rahman, Kartikeya Bhardwaj, Paul Whatmough, Radu Marculescu
分类: cs.CV, cs.AI
发布日期: 2025-12-30
💡 一句话要点
PipeFlow:面向长视频编辑的流水线处理和运动感知帧选择方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 长视频编辑 流水线处理 运动感知 帧选择 DDIM反演 神经网络插值 视频分割
📋 核心要点
- 长视频编辑面临计算成本随视频长度指数增长的挑战,现有方法难以有效处理。
- PipeFlow通过运动分析跳过低运动帧编辑,并采用流水线任务调度并行处理视频片段。
- PipeFlow利用神经网络插值平滑片段边界和插值跳过的帧,显著提升了长视频编辑速度。
📝 摘要(中文)
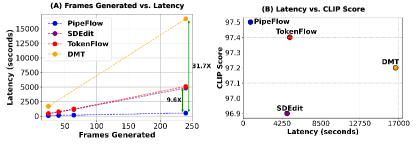
长视频编辑由于联合编辑和去噪扩散隐式模型(DDIM)反演在扩展序列上的计算成本呈指数增长,因此面临着独特的挑战。为了解决这些限制,我们提出了PipeFlow,一种可扩展的流水线视频编辑方法,它引入了三个关键创新:首先,基于使用结构相似性指数度量(SSIM)和光流的运动分析,我们识别并提出跳过低运动帧的编辑。其次,我们提出了一种流水线任务调度算法,该算法将视频分成多个片段,并基于可用的GPU内存并行执行DDIM反演和联合编辑。最后,我们利用基于神经网络的插值技术来平滑片段之间的边界帧并插值先前跳过的帧。我们的方法通过将较长的视频分成较小的片段来独特地扩展到更长的视频,从而使PipeFlow的编辑时间随视频长度线性增加。原则上,这使得可以编辑无限长的视频,而不会遇到其他方法遇到的不断增长的每帧计算开销。与TokenFlow相比,PipeFlow实现了高达9.6倍的加速,与Diffusion Motion Transfer(DMT)相比,实现了31.7倍的加速。
🔬 方法详解
问题定义:长视频编辑的主要问题在于计算复杂度随着视频长度的增加而呈指数级增长,特别是当涉及到基于扩散模型的编辑时,例如DDIM反演。现有的方法难以处理长视频,因为它们需要大量的GPU内存和计算资源,导致编辑速度慢,甚至无法完成。
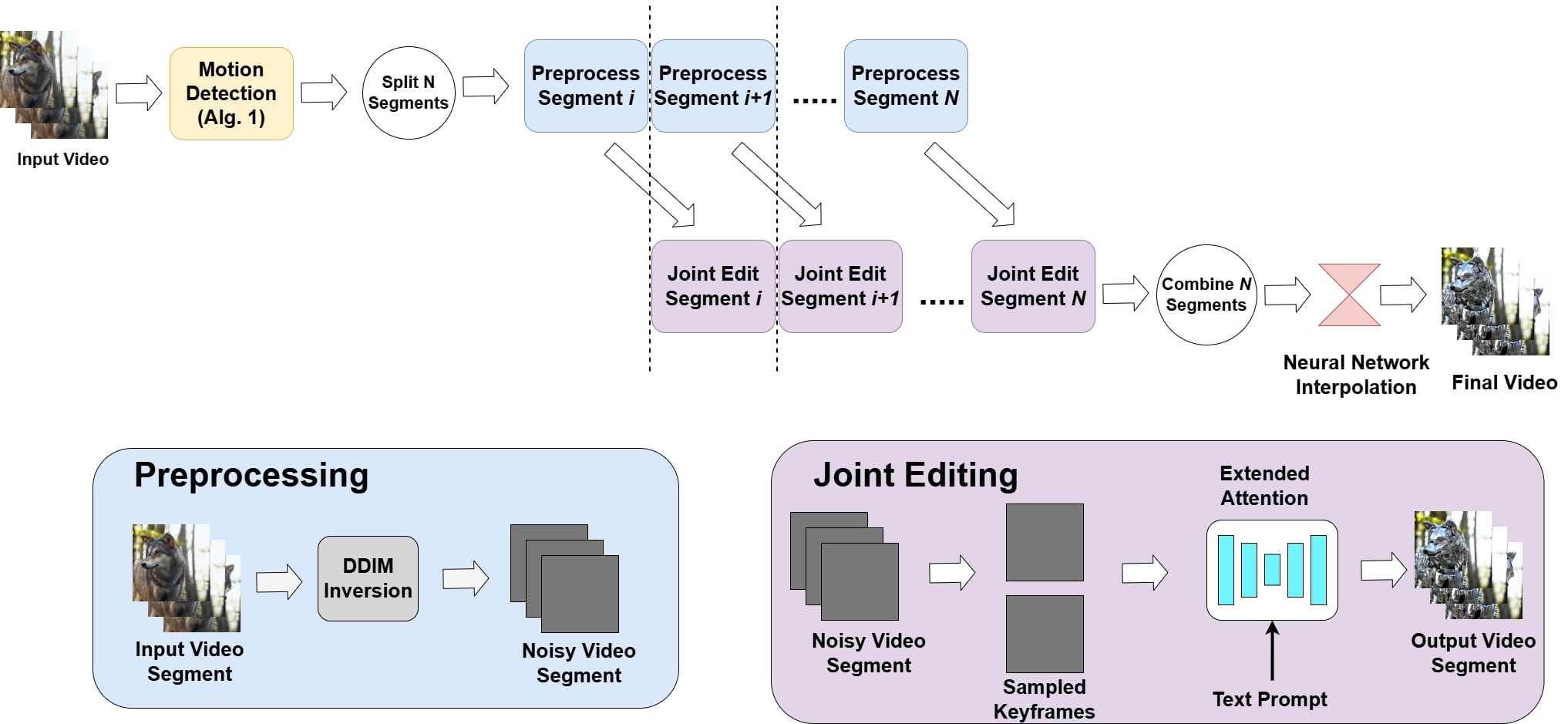
核心思路:PipeFlow的核心思路是将长视频分割成多个较小的片段,并利用流水线并行处理这些片段,从而降低单个GPU的内存需求,并提高整体的编辑速度。此外,通过运动分析,PipeFlow可以跳过编辑那些运动幅度较小的帧,进一步减少计算量。最后,使用神经网络插值技术来平滑片段之间的边界,并恢复跳过的帧,保证视频的流畅性。
技术框架:PipeFlow的整体框架包括以下几个主要阶段:1) 运动分析:使用SSIM和光流来估计视频帧之间的运动幅度。2) 帧选择:根据运动幅度,选择性地跳过一些帧的编辑。3) 视频分割:将视频分割成多个片段。4) 流水线处理:并行地对每个片段进行DDIM反演和联合编辑。5) 帧插值:使用神经网络插值技术来平滑片段之间的边界,并恢复跳过的帧。
关键创新:PipeFlow的关键创新在于其流水线处理和运动感知帧选择策略。通过流水线处理,PipeFlow可以将长视频编辑任务分解成多个可以并行执行的子任务,从而显著提高编辑速度。运动感知帧选择策略可以有效地减少需要编辑的帧的数量,进一步降低计算复杂度。与现有方法相比,PipeFlow能够处理更长的视频,并且具有更高的编辑效率。
关键设计:PipeFlow的关键设计包括:1) 运动分析的阈值设置:需要根据视频的内容和编辑需求来调整运动分析的阈值,以控制跳过的帧的数量。2) 视频分割的片段长度:需要根据GPU的内存大小和计算能力来调整片段的长度,以保证每个片段都可以在GPU上顺利处理。3) 神经网络插值模型的选择和训练:需要选择合适的神经网络插值模型,并使用大量的视频数据进行训练,以保证插值效果。
🖼️ 关键图片

📊 实验亮点
PipeFlow在长视频编辑任务中表现出色,与TokenFlow相比,实现了高达9.6倍的加速,与Diffusion Motion Transfer(DMT)相比,实现了31.7倍的加速。这些结果表明,PipeFlow能够有效地降低长视频编辑的计算复杂度,并显著提高编辑速度。
🎯 应用场景
PipeFlow可应用于电影制作、视频剪辑、在线教育等领域,尤其是在需要对长视频进行风格迁移、内容修改等操作时,可以显著提高编辑效率,降低计算成本。该方法还有潜力应用于实时视频编辑和增强,例如在直播或视频会议中进行实时风格转换或内容修改。
📄 摘要(原文)
Long-form video editing poses unique challenges due to the exponential increase in the computational cost from joint editing and Denoising Diffusion Implicit Models (DDIM) inversion across extended sequences. To address these limitations, we propose PipeFlow, a scalable, pipelined video editing method that introduces three key innovations: First, based on a motion analysis using Structural Similarity Index Measure (SSIM) and Optical Flow, we identify and propose to skip editing of frames with low motion. Second, we propose a pipelined task scheduling algorithm that splits a video into multiple segments and performs DDIM inversion and joint editing in parallel based on available GPU memory. Lastly, we leverage a neural network-based interpolation technique to smooth out the border frames between segments and interpolate the previously skipped frames. Our method uniquely scales to longer videos by dividing them into smaller segments, allowing PipeFlow's editing time to increase linearly with video length. In principle, this enables editing of infinitely long videos without the growing per-frame computational overhead encountered by other methods. PipeFlow achieves up to a 9.6X speedup compared to TokenFlow and a 31.7X speedup over Diffusion Motion Transfer (DMT).