RSAgent: Learning to Reason and Act for Text-Guided Segmentation via Multi-Turn Tool Invocations
作者: Xingqi He, Yujie Zhang, Shuyong Gao, Wenjie Li, Lingyi Hong, Mingxi Chen, Kaixun Jiang, Jiyuan Fu, Wenqiang Zhang
分类: cs.CV, cs.AI
发布日期: 2025-12-30
💡 一句话要点
提出RSAgent,通过多轮工具调用实现文本引导的图像分割,显著提升分割精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本引导分割 多模态大语言模型 Agent型学习 强化学习 迭代优化 视觉反馈 零样本学习
📋 核心要点
- 现有文本引导的图像分割方法缺乏迭代优化能力,难以处理初始定位错误的情况。
- RSAgent通过多轮工具调用,结合视觉反馈迭代优化分割结果,实现更精确的定位和分割。
- 实验表明,RSAgent在多个数据集上显著优于现有方法,展现了强大的零样本泛化能力。
📝 摘要(中文)
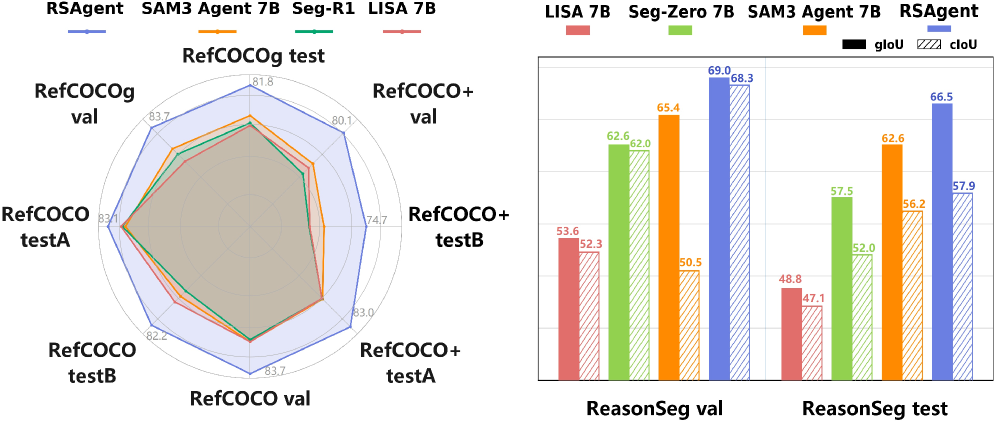
本文提出了一种名为RSAgent的Agent型多模态大语言模型(MLLM),用于解决文本引导的对象分割问题。现有方法通常将该任务视为单次grounding,限制了当初始定位错误时的验证、重新聚焦和细化能力。RSAgent通过多轮工具调用交错进行推理和行动,查询分割工具箱,观察视觉反馈,并利用历史观测修正其空间假设,从而重新定位目标并迭代细化掩码。此外,构建了一个数据pipeline来合成多轮推理分割轨迹,并采用两阶段框架训练RSAgent:冷启动监督微调,然后是具有细粒度、特定任务奖励的Agent型强化学习。实验表明,RSAgent在ReasonSeg测试集上实现了66.5%的gIoU零样本性能,比Seg-Zero-7B提高了9%,并在RefCOCOg上达到了81.5%的cIoU,在领域内和领域外基准测试中均表现出最先进的性能。
🔬 方法详解
问题定义:文本引导的图像分割旨在根据给定的文本描述,分割出图像中对应的目标对象。现有方法通常采用单次预测的方式,即模型一次性预测像素级别的提示信息,然后驱动外部分割器进行分割。这种方法的缺点在于,一旦初始定位出现错误,就难以进行纠正和优化,导致分割效果不佳。
核心思路:RSAgent的核心思路是将文本引导的图像分割任务建模为一个Agent与环境交互的过程。Agent通过观察图像和文本描述,调用分割工具进行分割,并根据分割结果的视觉反馈,调整分割策略,迭代优化分割结果。这种多轮交互的方式使得Agent能够逐步逼近目标,提高分割的准确性。
技术框架:RSAgent的整体框架包括以下几个主要模块:1) 多模态大语言模型(MLLM):负责接收图像和文本输入,进行推理和决策,生成分割工具的调用指令。2) 分割工具箱:包含各种分割算法,用于执行Agent的分割指令,并返回分割结果的视觉反馈。3) 记忆模块:用于存储Agent的历史观测和行动,为后续的推理和决策提供上下文信息。4) 奖励函数:用于评估Agent的分割结果,并指导Agent的学习。RSAgent通过多轮迭代,不断优化分割结果,直到满足停止条件。
关键创新:RSAgent的关键创新在于将文本引导的图像分割任务建模为一个Agent与环境交互的过程,并利用多模态大语言模型进行推理和决策。这种Agent型的方法能够充分利用视觉反馈,迭代优化分割结果,从而提高分割的准确性和鲁棒性。此外,RSAgent还构建了一个数据pipeline来合成多轮推理分割轨迹,并采用两阶段框架进行训练,进一步提升了模型的性能。
关键设计:RSAgent采用了多模态大语言模型作为Agent的决策模块,该模型能够同时处理图像和文本信息,并生成分割工具的调用指令。为了训练RSAgent,论文构建了一个数据pipeline来合成多轮推理分割轨迹,包括初始分割、错误定位、重新聚焦和迭代细化等步骤。在训练过程中,采用了两阶段框架:首先进行冷启动监督微调,然后进行Agent型强化学习,并设计了细粒度、特定任务的奖励函数,以指导Agent的学习。
🖼️ 关键图片


📊 实验亮点
RSAgent在ReasonSeg测试集上实现了66.5%的gIoU零样本性能,比Seg-Zero-7B提高了9%,并在RefCOCOg上达到了81.5%的cIoU,表明其在领域内和领域外基准测试中均表现出最先进的性能。这些结果验证了RSAgent的多轮推理和迭代优化策略的有效性,以及其强大的零样本泛化能力。
🎯 应用场景
RSAgent在图像编辑、自动驾驶、医疗影像分析等领域具有广泛的应用前景。例如,在图像编辑中,用户可以通过文本描述精确地分割和修改图像中的特定对象。在自动驾驶中,RSAgent可以用于识别和分割道路上的车辆、行人等目标,提高驾驶安全性。在医疗影像分析中,RSAgent可以辅助医生诊断疾病,提高诊断效率和准确性。
📄 摘要(原文)
Text-guided object segmentation requires both cross-modal reasoning and pixel grounding abilities. Most recent methods treat text-guided segmentation as one-shot grounding, where the model predicts pixel prompts in a single forward pass to drive an external segmentor, which limits verification, refocusing and refinement when initial localization is wrong. To address this limitation, we propose RSAgent, an agentic Multimodal Large Language Model (MLLM) which interleaves reasoning and action for segmentation via multi-turn tool invocations. RSAgent queries a segmentation toolbox, observes visual feedback, and revises its spatial hypothesis using historical observations to re-localize targets and iteratively refine masks. We further build a data pipeline to synthesize multi-turn reasoning segmentation trajectories, and train RSAgent with a two-stage framework: cold-start supervised fine-tuning followed by agentic reinforcement learning with fine-grained, task-specific rewards. Extensive experiments show that RSAgent achieves a zero-shot performance of 66.5% gIoU on ReasonSeg test, improving over Seg-Zero-7B by 9%, and reaches 81.5% cIoU on RefCOCOg, demonstrating state-of-the-art performance on both in-domain and out-of-domain benchmarks.