Bridging the Perception-Cognition Gap:Re-engineering SAM2 with Hilbert-Mamba for Robust VLM-based Medical Diagnosis
作者: Hao Wu, Hui Li, Yiyun Su
分类: cs.CV
发布日期: 2025-12-30
💡 一句话要点
提出Hilbert-VLM,利用Hilbert-Mamba增强SAM2,提升VLM在医学诊断中的鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学影像分析 视觉语言模型 病灶分割 Hilbert空间填充曲线 Mamba SSM 多模态融合 深度学习 医学诊断
📋 核心要点
- 现有VLM在处理复杂3D多模态医学图像时,难以有效整合互补信息,并容易忽略细微但关键的病理特征。
- Hilbert-VLM通过重设计的SAM2模块进行病灶分割,并生成多模态提示,引导VLM进行精确的疾病分类。
- 实验表明,Hilbert-VLM在BraTS2021数据集上取得了显著的分割和诊断性能提升,验证了其有效性。
📝 摘要(中文)
本研究提出了一种名为Hilbert-VLM的两阶段融合框架,旨在提升视觉语言模型(VLM)在自动医学诊断中的性能。该框架利用HilbertMed-SAM模块进行精确的病灶分割,并生成多模态增强提示,引导VLM进行准确的疾病分类。核心创新在于对Segment Anything Model 2 (SAM2)的系统性重设计:将Hilbert空间填充曲线融入Mamba状态空间模型(SSM)的扫描机制,以最大限度地保留3D数据的空间局部性。同时,引入了Hilbert-Mamba交叉注意力(HMCA)机制和尺度感知解码器,以捕获细粒度的细节。提示增强模块将分割掩码及其对应的文本属性统一为信息密集的提示,以支持VLM推理。在BraTS2021分割基准测试中,Dice系数达到82.35%,诊断分类准确率(ACC)达到78.85%。
🔬 方法详解
问题定义:医学图像,特别是3D多模态图像,包含大量信息,如何让VLM有效地理解和利用这些信息进行准确的疾病诊断是一个挑战。现有的VLM方法在处理此类图像时,常常难以捕捉细微的病理特征,并且无法充分整合不同模态的信息,导致诊断准确率不高。
核心思路:论文的核心思路是利用改进的SAM模型进行精确的病灶分割,并将分割结果和相关的文本信息结合起来,形成一个信息丰富的提示,从而引导VLM更好地理解医学图像并做出准确的诊断。通过在SAM中引入Hilbert空间填充曲线和Mamba SSM,增强模型对3D空间信息的感知能力。
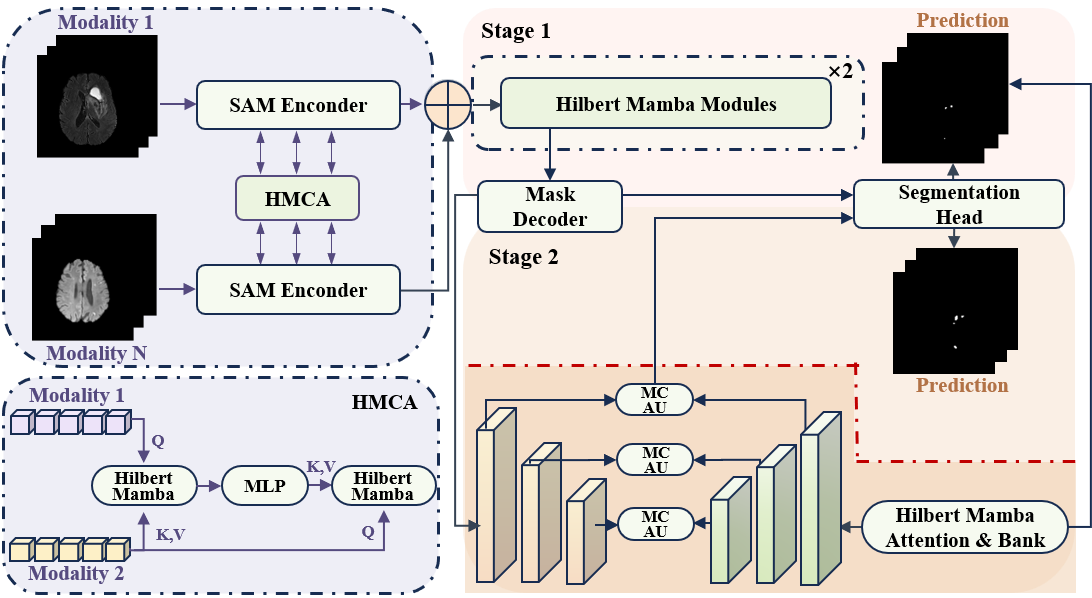
技术框架:Hilbert-VLM框架主要包含两个阶段:首先,使用HilbertMed-SAM模块对医学图像进行病灶分割,该模块是基于SAM2改进的。然后,将分割结果和相关的文本信息输入到提示增强模块,生成一个信息丰富的提示。最后,将该提示输入到VLM中进行疾病分类。
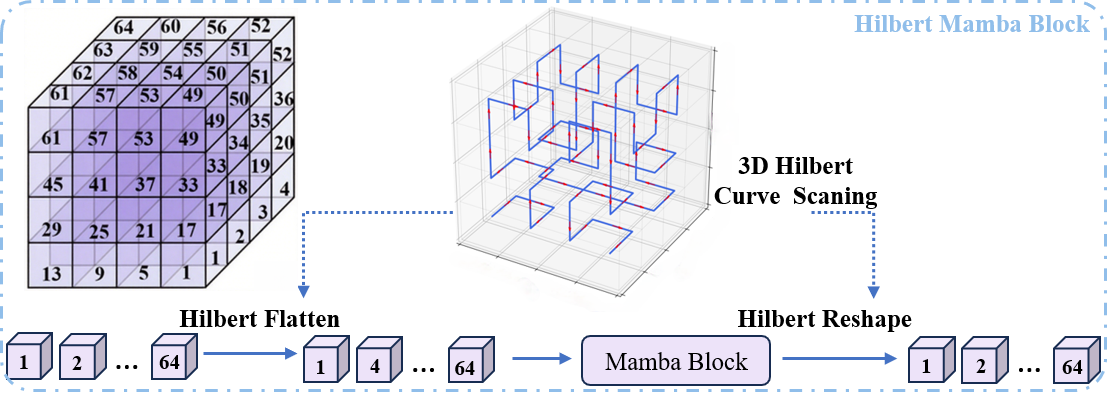
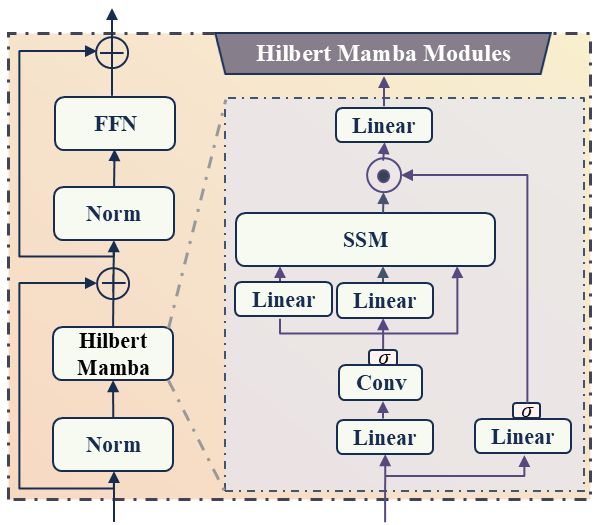
关键创新:论文的关键创新在于对SAM2的重设计,具体包括:1) 将Hilbert空间填充曲线融入Mamba SSM的扫描机制,以更好地保留3D数据的空间局部性;2) 引入Hilbert-Mamba交叉注意力(HMCA)机制和尺度感知解码器,以捕获细粒度的细节。这些创新使得模型能够更有效地处理3D医学图像,并提取出关键的病理特征。
关键设计:Hilbert空间填充曲线的选择和实现,Mamba SSM的具体参数设置,HMCA的结构设计,以及尺度感知解码器的实现细节,这些都是影响模型性能的关键设计。此外,提示增强模块如何有效地将分割掩码和文本信息融合也是一个重要的设计考虑。
🖼️ 关键图片
📊 实验亮点
Hilbert-VLM在BraTS2021脑肿瘤分割基准测试中,Dice系数达到了82.35%,显著优于其他基线方法。同时,在诊断分类任务中,准确率(ACC)达到了78.85%,表明该模型在医学图像分割和诊断方面具有显著的优势。这些结果验证了Hilbert-VLM在提升医学VLM分析准确性和可靠性方面的巨大潜力。
🎯 应用场景
该研究成果可应用于多种医学影像辅助诊断场景,例如脑肿瘤、肺结节等疾病的自动检测与诊断。通过提高诊断的准确性和效率,可以减轻医生的工作负担,并为患者提供更及时、更可靠的诊断结果。未来,该技术有望与远程医疗、智能健康等领域结合,实现更广泛的应用。
📄 摘要(原文)
Recent studies suggest that Visual Language Models (VLMs) hold great potential for tasks such as automated medical diagnosis. However, processing complex three-dimensional (3D) multimodal medical images poses significant challenges - specifically, the effective integration of complementary information and the occasional oversight of subtle yet critical pathological features. To address these issues, we present a novel two-stage fusion framework termed Hilbert-VLM. This framework leverages the HilbertMed-SAM module for precise lesion segmentation, with the generated multimodal enhanced prompts then guiding the VLM toward accurate disease classification. Our key innovation lies in the systematic redesign of the Segment Anything Model 2 (SAM2) architecture: we incorporate Hilbert space-filling curves into the scanning mechanism of the Mamba State Space Model (SSM) to maximize the preservation of spatial locality in 3D data, a property critical for medical image analysis. We also introduce a novel Hilbert-Mamba Cross-Attention (HMCA) mechanism and a scale-aware decoder to capture fine-grained details. Meanwhile, the prompt enhancement module unifies segmentation masks and their corresponding textual attributes into an information-dense prompt to support VLM inference. Extensive experiments were conducted to validate the effectiveness of the Hilbert-VLM model. On the BraTS2021 segmentation benchmark, it achieves a Dice score of 82.35 percent, with a diagnostic classification accuracy (ACC) of 78.85 percent. These results demonstrate that the proposed model offers substantial potential to improve the accuracy and reliability of medical VLM-based analysis.