Scaling Remote Sensing Foundation Models: Data Domain Tradeoffs at the Peta-Scale
作者: Charith Wickrema, Eliza Mace, Hunter Brown, Heidys Cabrera, Nick Krall, Matthew O'Neill, Shivangi Sarkar, Lowell Weissman, Eric Hughes, Guido Zarrella
分类: cs.CV
发布日期: 2025-12-29 (更新: 2026-01-14)
💡 一句话要点
探索遥感基础模型扩展性:在Peta级数据上权衡数据域
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 遥感基础模型 视觉Transformer Peta级数据 扩展性研究 数据限制 模型缩放 商业卫星EO数据
📋 核心要点
- 遥感领域缺乏对模型容量、训练计算和数据集大小之间关系的深入理解,阻碍了遥感基础模型的发展。
- 论文通过在Peta级商业卫星EO数据上训练视觉Transformer(ViT)骨干网络,探索遥感基础模型的扩展规律。
- 实验结果表明,即使在Peta级规模下,模型性能仍然受数据限制,而非模型参数限制,为遥感数据收集和模型训练提供了指导。
📝 摘要(中文)
本文探讨了人工智能的扩展行为,旨在为在高分辨率电光(EO)数据集上训练基础模型建立实用技术,这些数据集的规模超过了当前最先进水平几个数量级。现代多模态机器学习(ML)应用,如用于图像字幕、搜索和推理的生成式人工智能(GenAI)系统,依赖于针对非文本模态的强大、领域专用编码器。在自然图像领域,互联网规模的数据非常丰富,成熟的缩放定律有助于优化模型容量、训练计算和数据集大小的联合缩放。不幸的是,这些关系在高价值领域(如遥感(RS))中却鲜为人知。我们使用超过一万亿像素的商业卫星EO数据和MITRE的联邦AI沙箱,训练了逐渐增大的视觉Transformer(ViT)骨干网络,报告了在Peta级观察到的成功和失败模式,并分析了跨其他RS模态弥合领域差距的影响。我们观察到,即使在这个规模上,性能也与数据受限的机制一致,而不是模型参数受限的机制。这些实践见解旨在为数据收集策略、计算预算和优化计划提供信息,从而推进未来前沿规模RS基础模型的发展。
🔬 方法详解
问题定义:遥感领域缺乏像自然图像领域那样成熟的缩放定律,难以指导遥感基础模型的训练。现有方法难以有效利用大规模遥感数据,并且对模型容量、训练计算和数据集大小之间的关系理解不足。这导致遥感基础模型的发展受到限制,无法充分发挥其在图像字幕、搜索和推理等方面的潜力。
核心思路:论文的核心思路是通过大规模实验,探索遥感基础模型在Peta级数据上的扩展行为。通过训练不同规模的视觉Transformer(ViT)骨干网络,并分析其性能变化,从而揭示模型容量、训练计算和数据集大小之间的关系。这种方法旨在为遥感基础模型的训练提供实践指导,并促进其在各个领域的应用。
技术框架:论文使用MITRE的联邦AI沙箱和超过一万亿像素的商业卫星EO数据进行实验。整体框架包括以下几个步骤:1) 数据准备:收集和预处理大规模商业卫星EO数据。2) 模型训练:训练不同规模的视觉Transformer(ViT)骨干网络。3) 性能评估:评估模型在不同任务上的性能,并分析其变化趋势。4) 结果分析:分析实验结果,揭示模型容量、训练计算和数据集大小之间的关系。
关键创新:论文的关键创新在于首次在Peta级商业卫星EO数据上进行遥感基础模型的扩展性研究。通过大规模实验,揭示了遥感基础模型在数据受限的情况下,性能提升的规律。这为遥感基础模型的训练提供了重要的实践指导,并为未来的研究方向提供了新的思路。
关键设计:论文使用了视觉Transformer(ViT)作为基础模型,并探索了不同规模的ViT模型在Peta级数据上的性能表现。具体的技术细节包括:1) 模型结构:使用不同层数和隐藏单元数的ViT模型。2) 训练策略:使用大规模分布式训练,并采用合适的优化算法和学习率策略。3) 数据增强:使用数据增强技术,提高模型的泛化能力。4) 评估指标:使用常用的遥感图像分类和分割指标,评估模型的性能。
🖼️ 关键图片
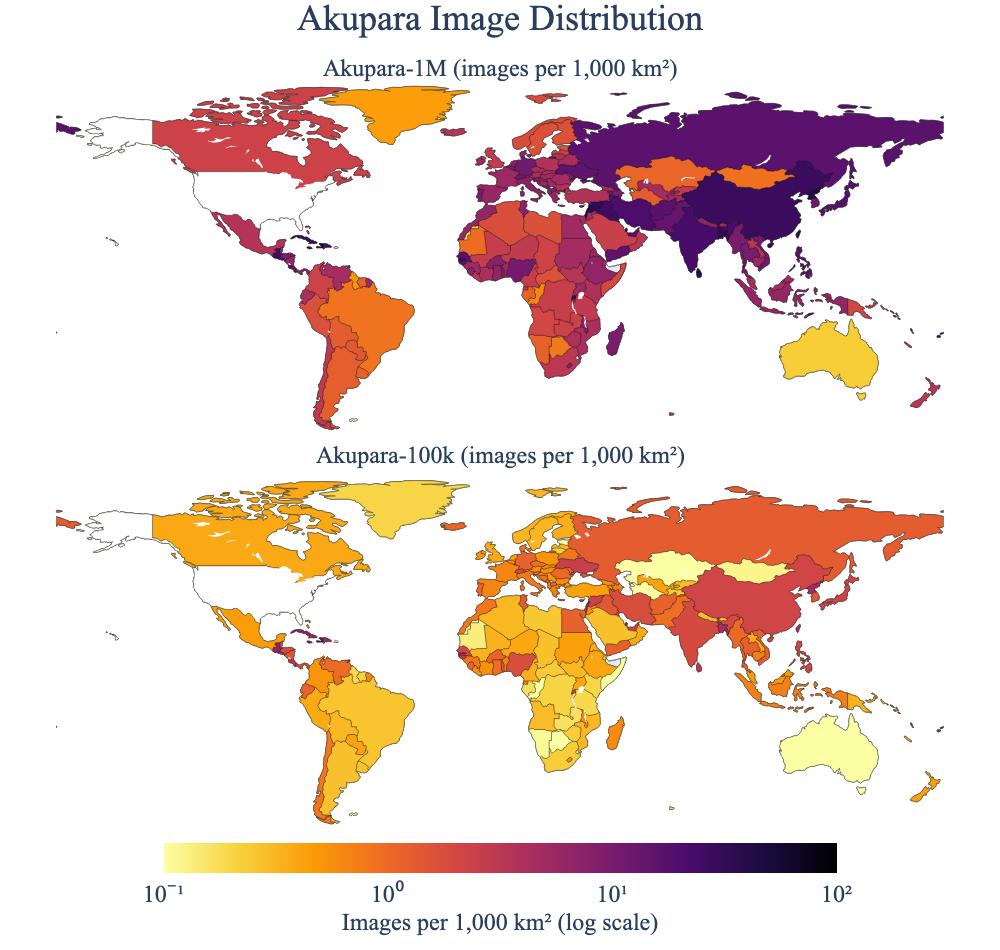

📊 实验亮点
实验结果表明,即使在Peta级规模下,遥感基础模型的性能仍然受数据限制,而非模型参数限制。这意味着,在当前阶段,增加数据量比增加模型参数更能有效地提高模型性能。此外,论文还报告了在Peta级训练过程中观察到的成功和失败模式,为未来的研究提供了宝贵的经验。
🎯 应用场景
该研究成果可应用于多种遥感应用场景,例如:土地利用分类、灾害监测、城市规划、农业估产等。通过训练更大规模的遥感基础模型,可以提高这些应用的精度和效率,为决策者提供更准确的信息支持。此外,该研究还可以促进遥感数据与其他模态数据的融合,为多模态机器学习应用提供更强大的支持。
📄 摘要(原文)
We explore the scaling behaviors of artificial intelligence to establish practical techniques for training foundation models on high-resolution electro-optical (EO) datasets that exceed the current state-of-the-art scale by orders of magnitude. Modern multimodal machine learning (ML) applications, such as generative artificial intelligence (GenAI) systems for image captioning, search, and reasoning, depend on robust, domain-specialized encoders for non-text modalities. In natural image domains where internet-scale data is plentiful, well-established scaling laws help optimize the joint scaling of model capacity, training compute, and dataset size. Unfortunately, these relationships are much less well understood in high-value domains like remote sensing (RS). Using over a quadrillion pixels of commercial satellite EO data and MITRE's Federal AI Sandbox, we train progressively larger vision transformer (ViT) backbones, report successes and failure modes observed at peta-scale, and analyze implications for bridging domain gaps across additional RS modalities. We observe that even at this scale, performance is consistent with a data-limited regime rather than a model parameter-limited one. These practical insights are intended to inform data collection strategies, compute budgets, and optimization schedules that advance the future development of frontier scale RS foundation models.