SoulX-FlashTalk: Real-Time Infinite Streaming of Audio-Driven Avatars via Self-Correcting Bidirectional Distillation
作者: Le Shen, Qian Qiao, Tan Yu, Ke Zhou, Tianhang Yu, Yu Zhan, Zhenjie Wang, Ming Tao, Shunshun Yin, Siyuan Liu
分类: cs.CV, cs.AI
发布日期: 2025-12-29 (更新: 2026-01-06)
备注: 12 pages, 6 figures
💡 一句话要点
SoulX-FlashTalk:基于自校正双向蒸馏的实时无限音频驱动头像生成
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 音频驱动头像 实时生成 双向蒸馏 自校正机制 流式生成 数字人 推理加速
📋 核心要点
- 现有音频驱动头像生成方法在计算量和延迟之间妥协,通常牺牲视觉效果来满足实时性要求。
- SoulX-FlashTalk采用自校正双向蒸馏,保留时空相关性,并引入自校正机制防止无限生成过程中的模型崩溃。
- 该系统实现了0.87秒的启动延迟和32 FPS的实时吞吐量,为高保真交互式数字人合成设立了新标准。
📝 摘要(中文)
本文提出SoulX-FlashTalk,一个140亿参数的框架,旨在优化高保真实时流式音频驱动头像生成。针对大规模扩散模型在实时无限时长头像生成中面临的计算负载与严格延迟约束之间的矛盾,该框架采用自校正双向蒸馏策略,在视频块内保留双向注意力,从而保持关键的时空相关性,显著增强运动连贯性和视觉细节。为了确保无限生成过程中的稳定性,引入多步回顾自校正机制,使模型能够自主地从累积误差中恢复,防止模型崩溃。此外,还设计了全栈推理加速套件,包括混合序列并行、并行VAE和内核级优化。实验结果表明,SoulX-FlashTalk是首个实现亚秒级启动延迟(0.87秒)并达到32 FPS实时吞吐量的140亿参数系统,为高保真交互式数字人合成树立了新标准。
🔬 方法详解
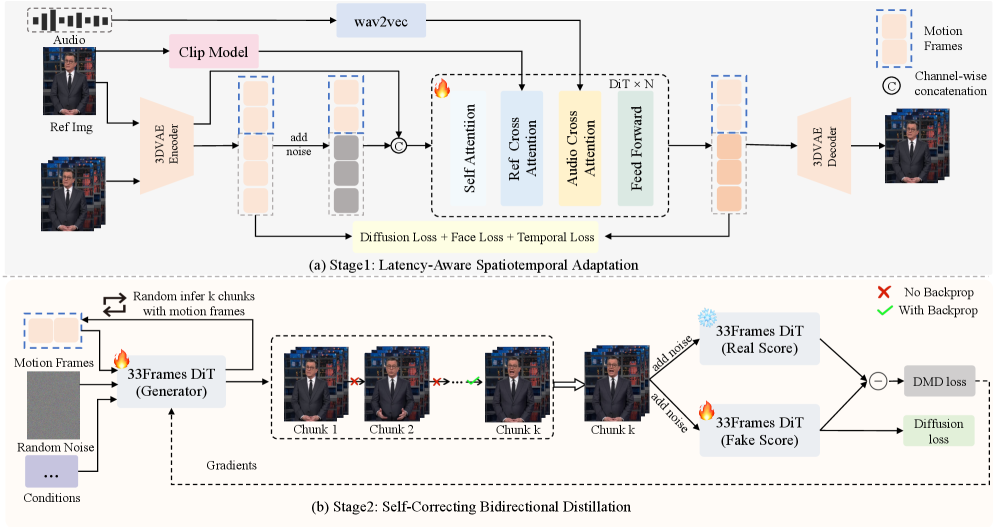
问题定义:现有音频驱动头像生成方法难以兼顾高保真和实时性,尤其是在无限时长的流式生成场景下。为了满足实时性要求,现有方法通常采用单向注意力机制或降低模型容量,导致视觉效果不佳,例如运动不连贯、细节缺失等。
核心思路:SoulX-FlashTalk的核心思路是利用自校正双向蒸馏,在保证实时性的前提下,尽可能保留双向注意力带来的时空信息,从而提升生成头像的视觉质量和运动连贯性。此外,引入自校正机制来解决无限生成过程中可能出现的累积误差和模型崩溃问题。
技术框架:SoulX-FlashTalk的整体框架包含以下几个主要模块:音频特征提取模块(提取音频特征作为驱动信号)、视频块生成模块(利用双向蒸馏生成视频块)、自校正模块(对生成的视频块进行校正,防止误差累积)、以及推理加速模块(包括混合序列并行、并行VAE和内核级优化)。整个流程是流式的,可以实现无限时长的实时生成。
关键创新:SoulX-FlashTalk的关键创新在于自校正双向蒸馏策略和多步回顾自校正机制。自校正双向蒸馏允许模型在视频块内部利用双向注意力,从而更好地捕捉时空相关性,而多步回顾自校正机制则能够有效地防止无限生成过程中的误差累积和模型崩溃。与现有方法相比,SoulX-FlashTalk在保证实时性的同时,显著提升了生成头像的视觉质量和稳定性。
关键设计:在自校正双向蒸馏中,采用了教师-学生模型的蒸馏策略,教师模型使用双向注意力,学生模型则在保证实时性的前提下尽可能模仿教师模型的输出。多步回顾自校正机制则通过对历史生成的视频块进行回顾和校正,来减小误差累积。此外,推理加速模块采用了混合序列并行、并行VAE和内核级优化等技术,进一步提升了系统的实时性。
🖼️ 关键图片


📊 实验亮点
SoulX-FlashTalk在实验中表现出色,实现了0.87秒的亚秒级启动延迟,并达到了32 FPS的实时吞吐量。与现有方法相比,SoulX-FlashTalk在视觉质量和运动连贯性方面均有显著提升。该系统是首个实现如此高性能的140亿参数音频驱动头像生成系统,为该领域树立了新的标杆。
🎯 应用场景
SoulX-FlashTalk具有广泛的应用前景,包括虚拟主播、在线会议、游戏角色定制、数字人助手等。该技术能够生成高保真、实时的音频驱动头像,为用户提供更具沉浸感和互动性的体验。未来,该技术有望应用于元宇宙、社交媒体等领域,推动数字人技术的普及和发展。
📄 摘要(原文)
Deploying massive diffusion models for real-time, infinite-duration, audio-driven avatar generation presents a significant engineering challenge, primarily due to the conflict between computational load and strict latency constraints. Existing approaches often compromise visual fidelity by enforcing strictly unidirectional attention mechanisms or reducing model capacity. To address this problem, we introduce \textbf{SoulX-FlashTalk}, a 14B-parameter framework optimized for high-fidelity real-time streaming. Diverging from conventional unidirectional paradigms, we use a \textbf{Self-correcting Bidirectional Distillation} strategy that retains bidirectional attention within video chunks. This design preserves critical spatiotemporal correlations, significantly enhancing motion coherence and visual detail. To ensure stability during infinite generation, we incorporate a \textbf{Multi-step Retrospective Self-Correction Mechanism}, enabling the model to autonomously recover from accumulated errors and preventing collapse. Furthermore, we engineered a full-stack inference acceleration suite incorporating hybrid sequence parallelism, Parallel VAE, and kernel-level optimizations. Extensive evaluations confirm that SoulX-FlashTalk is the first 14B-scale system to achieve a \textbf{sub-second start-up latency (0.87s)} while reaching a real-time throughput of \textbf{32 FPS}, setting a new standard for high-fidelity interactive digital human synthesis.