GaussianDWM: 3D Gaussian Driving World Model for Unified Scene Understanding and Multi-Modal Generation
作者: Tianchen Deng, Xuefeng Chen, Yi Chen, Qu Chen, Yuyao Xu, Lijin Yang, Le Xu, Yu Zhang, Bo Zhang, Wuxiong Huang, Hesheng Wang
分类: cs.CV
发布日期: 2025-12-29 (更新: 2026-01-12)
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于3D高斯表示的驾驶世界模型,实现统一的场景理解和多模态生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 驾驶世界模型 3D高斯表示 多模态生成 场景理解 视觉语言融合
📋 核心要点
- 现有驾驶世界模型缺乏3D场景理解能力,且只能基于输入数据生成内容,无法解释或推理驾驶环境。
- 提出基于3D高斯场景表示的统一DWM框架,通过将语言特征嵌入高斯基元实现早期模态对齐。
- 设计任务感知语言引导采样策略和双条件多模态生成模型,并在nuScenes等数据集上验证了有效性。
📝 摘要(中文)
本文提出了一种新颖的统一驾驶世界模型(DWM)框架,该框架基于3D高斯场景表示,能够实现3D场景理解和多模态场景生成,同时增强了对理解和生成任务的上下文丰富性。该方法通过将丰富的语言特征嵌入到每个高斯基元中,直接将文本信息与3D场景对齐,从而实现早期模态对齐。此外,设计了一种新颖的、任务感知的语言引导采样策略,该策略消除了冗余的3D高斯,并将准确而紧凑的3D token注入到LLM中。进一步地,设计了一个双条件多模态生成模型,其中视觉-语言模型捕获的信息被用作高级语言条件,并结合低级图像条件,共同指导多模态生成过程。在nuScenes和NuInteract数据集上进行了全面的研究,验证了该框架的有效性。该方法取得了最先进的性能。
🔬 方法详解
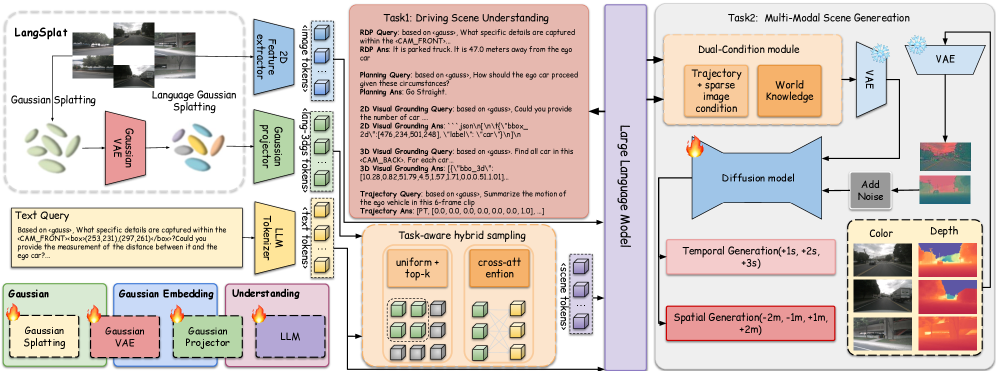
问题定义:现有驾驶世界模型(DWMs)缺乏3D场景理解能力,无法对驾驶环境进行解释和推理。此外,现有的3D空间信息表示方法(如点云或BEV特征)无法准确地将文本信息与底层3D场景对齐,阻碍了多模态信息的有效融合。
核心思路:本文的核心思路是利用3D高斯表示作为统一的场景表示,将视觉和语言信息进行早期融合。通过将丰富的语言特征嵌入到每个3D高斯基元中,实现文本信息与3D场景的直接对齐,从而增强模型对驾驶环境的理解和推理能力。同时,设计任务感知的采样策略和双条件生成模型,提升生成质量。
技术框架:该框架包含以下主要模块:1) 3D高斯场景表示模块:将3D场景表示为一组3D高斯基元,每个高斯基元包含位置、大小、颜色等属性。2) 视觉-语言嵌入模块:将图像和文本信息嵌入到3D高斯基元中,实现早期模态对齐。3) 任务感知语言引导采样模块:根据任务需求,对3D高斯基元进行采样,选择与任务相关的基元。4) 双条件多模态生成模块:利用视觉和语言信息,生成多模态场景内容。
关键创新:最重要的技术创新点在于使用3D高斯表示作为统一的场景表示,并将其与语言信息进行早期融合。与传统的点云或BEV特征相比,3D高斯表示具有更强的表达能力和可解释性,能够更准确地捕捉3D场景的结构信息。此外,任务感知的采样策略和双条件生成模型也提升了生成质量。
关键设计:任务感知语言引导采样策略:设计了一种基于语言信息的采样策略,根据任务需求选择与任务相关的3D高斯基元。双条件多模态生成模型:利用视觉和语言信息,共同指导多模态场景内容的生成。具体的损失函数和网络结构等技术细节在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
该方法在nuScenes和NuInteract数据集上取得了state-of-the-art的性能。实验结果表明,该方法能够有效地理解3D场景,并生成高质量的多模态场景内容。具体的性能数据和对比基线在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、虚拟现实等领域。通过增强对驾驶环境的理解和推理能力,可以提高自动驾驶系统的安全性和可靠性。此外,该方法还可以用于生成逼真的虚拟场景,为虚拟现实应用提供更丰富的体验。
📄 摘要(原文)
Driving World Models (DWMs) have been developing rapidly with the advances of generative models. However, existing DWMs lack 3D scene understanding capabilities and can only generate content conditioned on input data, without the ability to interpret or reason about the driving environment. Moreover, current approaches represent 3D spatial information with point cloud or BEV features do not accurately align textual information with the underlying 3D scene. To address these limitations, we propose a novel unified DWM framework based on 3D Gaussian scene representation, which enables both 3D scene understanding and multi-modal scene generation, while also enabling contextual enrichment for understanding and generation tasks. Our approach directly aligns textual information with the 3D scene by embedding rich linguistic features into each Gaussian primitive, thereby achieving early modality alignment. In addition, we design a novel task-aware language-guided sampling strategy that removes redundant 3D Gaussians and injects accurate and compact 3D tokens into LLM. Furthermore, we design a dual-condition multi-modal generation model, where the information captured by our vision-language model is leveraged as a high-level language condition in combination with a low-level image condition, jointly guiding the multi-modal generation process. We conduct comprehensive studies on the nuScenes, and NuInteract datasets to validate the effectiveness of our framework. Our method achieves state-of-the-art performance. We will release the code publicly on GitHub https://github.com/dtc111111/GaussianDWM.