With Great Context Comes Great Prediction Power: Classifying Objects via Geo-Semantic Scene Graphs
作者: Ciprian Constantinescu, Marius Leordeanu
分类: cs.CV
发布日期: 2025-12-28
备注: This paper is a development of the visual riddle game with Human-AI interaction, entitled "GuessWhat - Riddle Eye with AI", developed by Ciprian Constantinescu (POLItEHNICA Bucharest), Serena Stan (Instituto Cervantes Bucarest) and Marius Leordeanu (POLITEHNICA Bucharest), which was the winner (1st place) of the NeoArt Connect NAC 2025 Scholarship Program
💡 一句话要点
提出基于地理语义场景图的上下文感知对象分类框架,显著提升识别精度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对象识别 场景理解 上下文建模 图神经网络 地理语义场景图
📋 核心要点
- 现有对象识别系统缺乏对周围场景上下文的理解,导致识别性能受限,无法有效利用空间关系和对象共现信息。
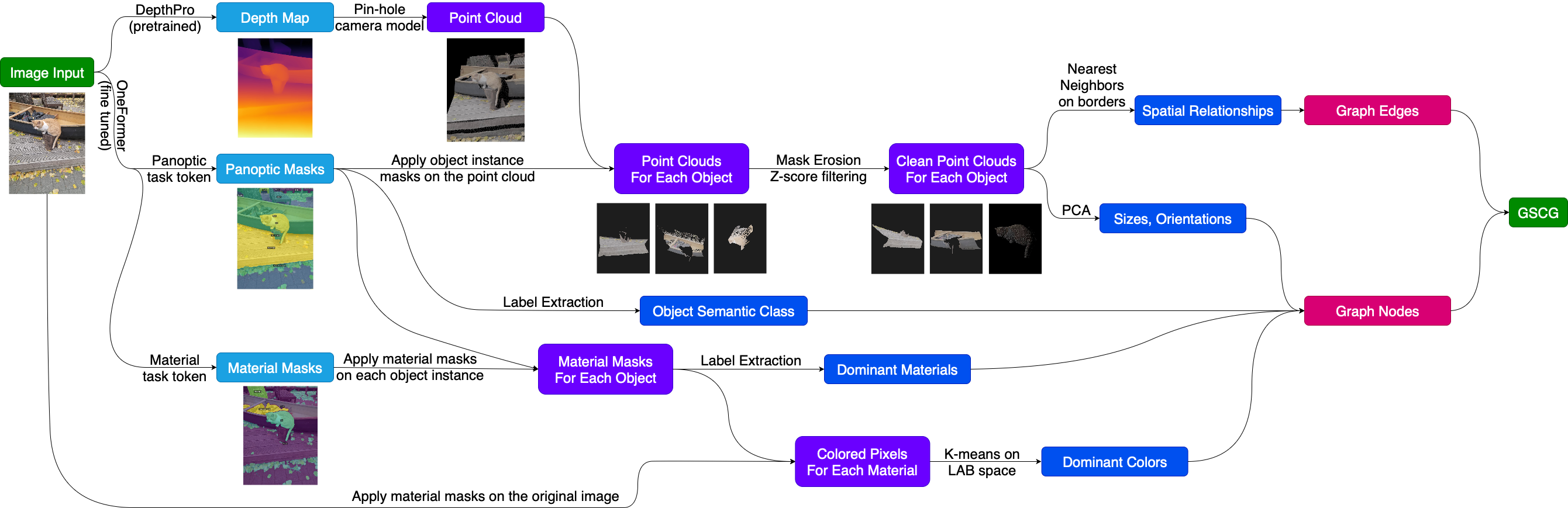
- 构建地理语义上下文图(GSCG),显式编码对象的几何、材料属性及其空间关系,并设计图分类器聚合上下文特征。
- 实验表明,该方法在COCO数据集上显著优于上下文无关模型和现有基线,证明了上下文信息在对象识别中的重要性。
📝 摘要(中文)
本文提出了一种用于上下文对象分类的新框架,强调了上下文的关键作用。该框架首先从单目图像构建一个地理语义上下文图(GSCG)。这个结构化的表示通过将度量深度估计器与统一的全景和材料分割模型集成来实现。GSCG将对象编码为具有详细几何、颜色和材料属性的节点,并将它们之间的空间关系编码为边。然后,提出了一个专门的基于图的分类器,该分类器聚合来自目标对象、其直接邻居和全局场景上下文的特征来预测其类别。在COCO 2017数据集上的实验结果表明,该上下文感知模型实现了73.4%的分类准确率,显著优于上下文无关的版本(低至38.4%),并且超越了包括微调的ResNet模型(最高53.5%)和最先进的多模态大语言模型Llama 4 Scout(最高42.3%)等强基线。
🔬 方法详解
问题定义:现有对象识别方法主要依赖于孤立的图像区域,忽略了场景上下文提供的丰富信息,例如对象之间的空间关系、材质属性以及共现模式。这导致识别精度受限,尤其是在复杂场景中。
核心思路:本文的核心思路是利用场景上下文来辅助对象识别。通过构建一个显式的图结构,将对象及其之间的关系编码到图中,并利用图神经网络来聚合上下文信息,从而提高对象识别的准确性。这种方法模拟了人类利用周围环境来理解和识别物体的认知过程。
技术框架:该框架主要包含两个阶段:1) 构建地理语义上下文图(GSCG)。首先,使用度量深度估计器和全景/材料分割模型从单目图像中提取对象的几何、语义和材料信息。然后,将对象表示为图中的节点,节点的属性包括几何特征、颜色特征和材料特征。对象之间的空间关系(例如,相邻关系、包含关系)表示为图中的边。2) 基于图的分类器。设计一个图神经网络,用于聚合来自目标对象、其邻居节点以及全局场景上下文的特征。该分类器利用图结构信息来学习对象之间的依赖关系,并预测目标对象的类别。
关键创新:该方法最重要的创新点在于显式地构建和利用地理语义上下文图(GSCG)。与隐式地学习上下文信息的方法相比,GSCG能够更有效地编码对象之间的关系,并且具有更好的可解释性。此外,该方法将几何、语义和材料信息集成到图中,从而提供了更全面的上下文表示。
关键设计:GSCG的构建依赖于高质量的深度估计和分割结果。论文中使用了现有的深度估计和分割模型,并对其输出进行了后处理,以提高GSCG的质量。图神经网络的具体结构未知,但其目标是聚合来自不同尺度的上下文信息,并学习节点之间的依赖关系。损失函数的设计目标是最大化分类准确率,同时鼓励模型学习到有意义的上下文表示。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在COCO 2017数据集上取得了显著的性能提升。上下文感知模型达到了73.4%的分类准确率,而上下文无关的版本仅为38.4%。此外,该方法还超越了包括微调的ResNet模型(最高53.5%)和最先进的多模态大语言模型Llama 4 Scout(最高42.3%)等强基线,证明了其有效性。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、智能监控等领域。通过利用场景上下文信息,机器人可以更准确地识别周围环境中的物体,从而做出更明智的决策。例如,在自动驾驶中,该方法可以帮助车辆识别交通标志、行人和其他车辆,从而提高驾驶安全性。在智能监控中,该方法可以用于识别异常行为和可疑物体。
📄 摘要(原文)
Humans effortlessly identify objects by leveraging a rich understanding of the surrounding scene, including spatial relationships, material properties, and the co-occurrence of other objects. In contrast, most computational object recognition systems operate on isolated image regions, devoid of meaning in isolation, thus ignoring this vital contextual information. This paper argues for the critical role of context and introduces a novel framework for contextual object classification. We first construct a Geo-Semantic Contextual Graph (GSCG) from a single monocular image. This rich, structured representation is built by integrating a metric depth estimator with a unified panoptic and material segmentation model. The GSCG encodes objects as nodes with detailed geometric, chromatic, and material attributes, and their spatial relationships as edges. This explicit graph structure makes the model's reasoning process inherently interpretable. We then propose a specialized graph-based classifier that aggregates features from a target object, its immediate neighbors, and the global scene context to predict its class. Through extensive ablation studies, we demonstrate that our context-aware model achieves a classification accuracy of 73.4%, dramatically outperforming context-agnostic versions (as low as 38.4%). Furthermore, our GSCG-based approach significantly surpasses strong baselines, including fine-tuned ResNet models (max 53.5%) and a state-of-the-art multimodal Large Language Model (LLM), Llama 4 Scout, which, even when given the full image alongside a detailed description of objects, maxes out at 42.3%. These results on COCO 2017 train/val splits highlight the superiority of explicitly structured and interpretable context for object recognition tasks.