OpenGround: Active Cognition-based Reasoning for Open-World 3D Visual Grounding
作者: Wenyuan Huang, Zhao Wang, Zhou Wei, Ting Huang, Fang Zhao, Jian Yang, Zhenyu Zhang
分类: cs.CV, cs.AI
发布日期: 2025-12-28 (更新: 2025-12-31)
备注: 27 pages, 15 figures, 14 tables, Project Page at https://why-102.github.io/openground.io/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出OpenGround,通过主动认知推理解决开放世界3D视觉定位问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D视觉定位 开放世界 主动认知推理 视觉语言模型 零样本学习
📋 核心要点
- 现有3D视觉定位方法依赖预定义对象查找表,无法处理开放世界中未定义或不可预见的目标。
- OpenGround通过主动认知推理模块,动态更新视觉语言模型的认知范围,实现对开放世界目标的定位。
- 实验结果表明,OpenGround在多个数据集上表现优异,并在OpenTarget数据集上取得了显著提升。
📝 摘要(中文)
本文提出OpenGround,一种新颖的零样本框架,用于开放世界3D视觉定位。现有方法依赖于预定义的对象查找表(OLT)来查询视觉语言模型(VLM),从而推理对象位置,这限制了在具有未定义或不可预见目标场景中的应用。OpenGround的核心是基于主动认知推理(ACR)模块,旨在通过逐步增强VLM的认知范围来克服预定义OLT的根本限制。ACR模块通过认知任务链执行类似人类的目标感知,并主动推理上下文相关的对象,从而通过动态更新的OLT扩展VLM认知。这使得OpenGround能够处理预定义和开放世界类别。此外,本文提出了一个新的数据集OpenTarget,其中包含超过7000个对象-描述对,用于评估该方法在开放世界场景中的性能。大量实验表明,OpenGround在Nr3D上取得了具有竞争力的性能,在ScanRefer上达到了最先进水平,并在OpenTarget上实现了显著的17.6%的改进。
🔬 方法详解
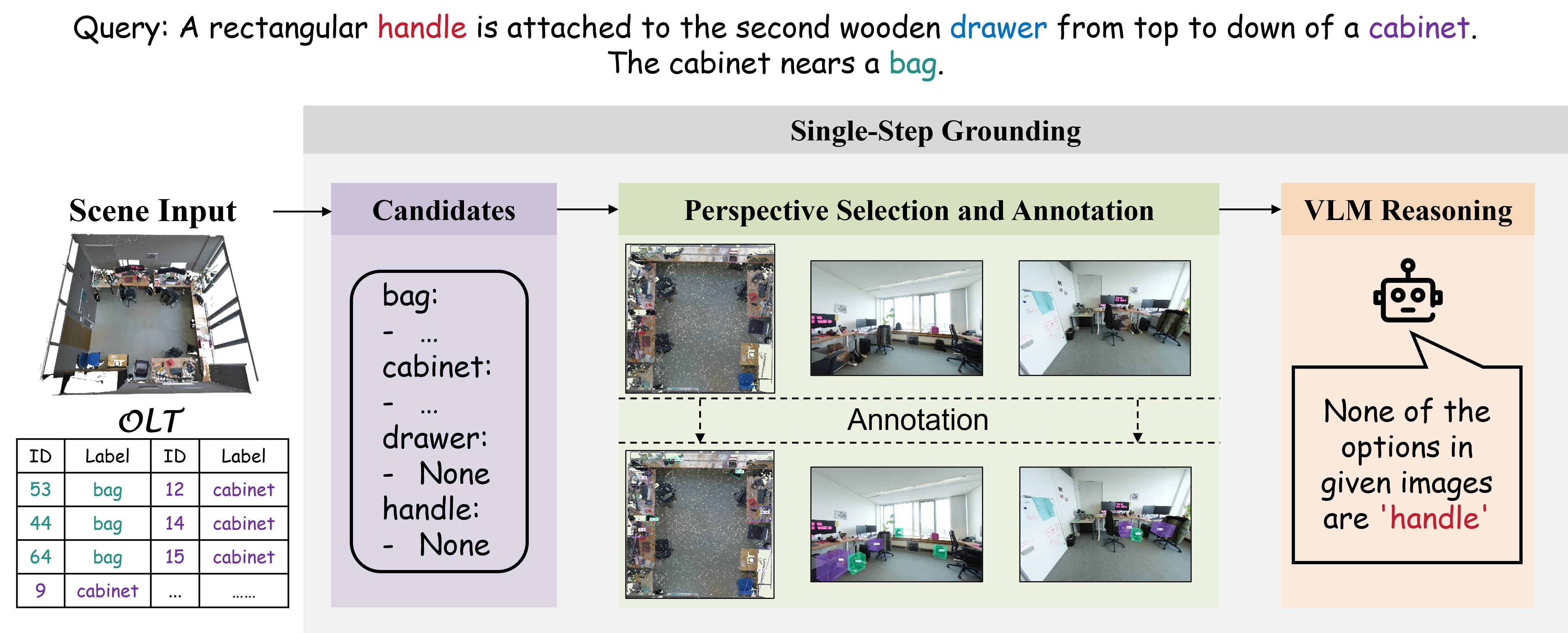
问题定义:3D视觉定位旨在根据自然语言描述在3D场景中定位对象。现有方法主要依赖于预定义的对象查找表(OLT),通过查询视觉语言模型(VLM)来推理对象的位置。这种方法的痛点在于,当目标对象不在预定义的OLT中时,例如在开放世界场景中遇到未定义或不可预见的目标时,现有方法将失效。
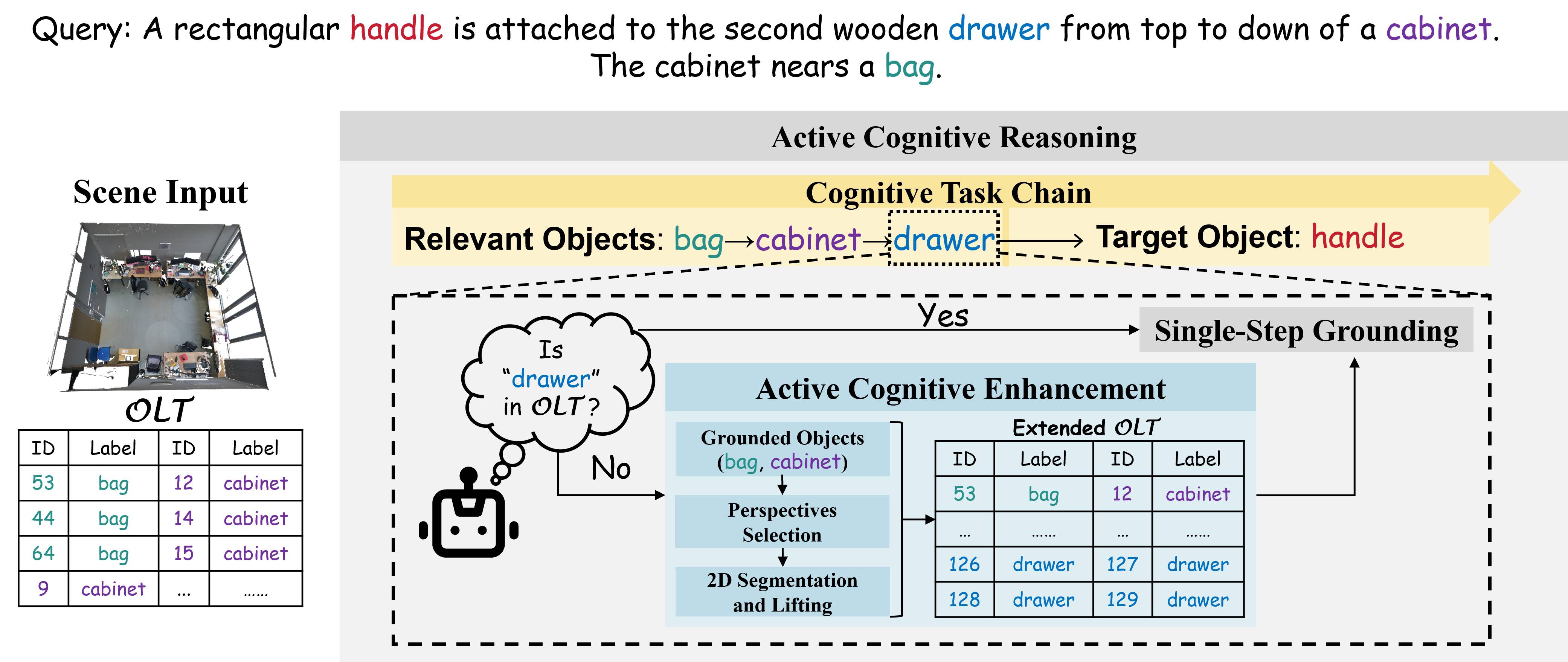
核心思路:OpenGround的核心思路是模拟人类的认知过程,通过主动地探索和理解场景中的对象,逐步扩展视觉语言模型的认知范围。它不依赖于预定义的OLT,而是通过一个动态更新的OLT来表示当前场景中的对象。这种设计使得OpenGround能够处理开放世界中的目标定位任务。
技术框架:OpenGround的主要框架包含一个基于主动认知推理(ACR)的模块。ACR模块通过一个认知任务链来模拟人类的感知过程,包括感知、推理和行动。该模块首先感知场景中的对象,然后根据自然语言描述推理出目标对象可能的位置,最后通过行动来验证推理结果并更新OLT。整个过程是一个迭代的过程,直到找到目标对象或达到最大迭代次数。
关键创新:OpenGround的关键创新在于其基于主动认知推理(ACR)的模块。与现有方法依赖于预定义的OLT不同,ACR模块能够动态地扩展视觉语言模型的认知范围,从而处理开放世界中的目标定位任务。这种方法更接近于人类的认知方式,具有更强的泛化能力。
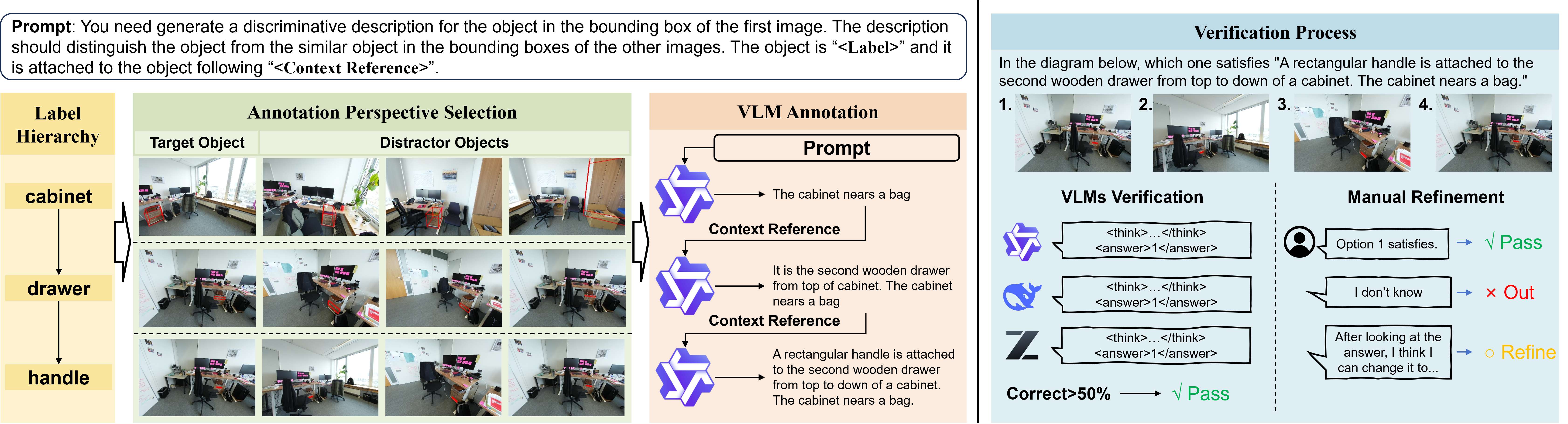
关键设计:ACR模块中的认知任务链包含多个步骤,例如对象分割、属性识别和关系推理。每个步骤都使用深度学习模型来实现。此外,OpenGround还设计了一个动态更新的OLT,用于存储当前场景中的对象信息。OLT的更新策略基于推理结果和行动反馈,以确保OLT的准确性和完整性。损失函数的设计旨在鼓励模型学习到更有效的认知策略,例如通过强化学习来优化行动策略。
🖼️ 关键图片
📊 实验亮点
OpenGround在Nr3D、ScanRefer和OpenTarget三个数据集上进行了评估。在Nr3D上取得了具有竞争力的性能,在ScanRefer上达到了最先进水平。特别是在OpenTarget数据集上,OpenGround实现了显著的17.6%的性能提升,证明了其在开放世界3D视觉定位方面的有效性。
🎯 应用场景
OpenGround在机器人导航、智能家居、增强现实等领域具有广泛的应用前景。例如,在机器人导航中,机器人可以根据用户的自然语言指令,在未知环境中定位目标对象。在智能家居中,用户可以通过语音控制,让智能家居系统定位并操作特定设备。在增强现实中,用户可以通过AR设备,在真实场景中定位虚拟对象。
📄 摘要(原文)
3D visual grounding aims to locate objects based on natural language descriptions in 3D scenes. Existing methods rely on a pre-defined Object Lookup Table (OLT) to query Visual Language Models (VLMs) for reasoning about object locations, which limits the applications in scenarios with undefined or unforeseen targets. To address this problem, we present OpenGround, a novel zero-shot framework for open-world 3D visual grounding. Central to OpenGround is the Active Cognition-based Reasoning (ACR) module, which is designed to overcome the fundamental limitation of pre-defined OLTs by progressively augmenting the cognitive scope of VLMs. The ACR module performs human-like perception of the target via a cognitive task chain and actively reasons about contextually relevant objects, thereby extending VLM cognition through a dynamically updated OLT. This allows OpenGround to function with both pre-defined and open-world categories. We also propose a new dataset named OpenTarget, which contains over 7000 object-description pairs to evaluate our method in open-world scenarios. Extensive experiments demonstrate that OpenGround achieves competitive performance on Nr3D, state-of-the-art on ScanRefer, and delivers a substantial 17.6% improvement on OpenTarget. Project Page at https://why-102.github.io/openground.io/.