ColaVLA: Leveraging Cognitive Latent Reasoning for Hierarchical Parallel Trajectory Planning in Autonomous Driving
作者: Qihang Peng, Xuesong Chen, Chenye Yang, Shaoshuai Shi, Hongsheng Li
分类: cs.CV
发布日期: 2025-12-28 (更新: 2025-12-31)
备注: 11 pages, 4 figures. Project page: https://pqh22.github.io/projects/ColaVLA/index.html
💡 一句话要点
ColaVLA:利用认知潜在推理进行自动驾驶分层并行轨迹规划
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 轨迹规划 视觉语言模型 认知推理 分层规划
📋 核心要点
- 现有基于视觉-语言模型的自动驾驶规划器面临文本推理与连续控制不匹配、推理延迟高和规划效率低等挑战。
- ColaVLA将文本推理迁移到统一的潜在空间,并结合分层并行轨迹解码器,实现高效的轨迹生成。
- 在nuScenes基准测试中,ColaVLA在开环和闭环设置下均达到SOTA性能,并展现出良好的效率和鲁棒性。
📝 摘要(中文)
自动驾驶需要在复杂的多模态输入中生成安全可靠的轨迹。传统的模块化流程分离了感知、预测和规划,而最近的端到端(E2E)系统则将它们联合学习。视觉-语言模型(VLMs)通过引入跨模态先验和常识推理进一步丰富了这种模式,但目前基于VLM的规划器面临三个关键挑战:(i)离散文本推理和连续控制之间的不匹配,(ii)来自自回归链式思考解码的高延迟,以及(iii)限制实时部署的低效或非因果规划器。我们提出了ColaVLA,一个统一的视觉-语言-动作框架,它将推理从文本转移到统一的潜在空间,并将其与分层并行轨迹解码器耦合。认知潜在推理器通过自我适应选择和仅两次VLM正向传递,将场景理解压缩为紧凑的、面向决策的元动作嵌入。然后,分层并行规划器在一次正向传递中生成多尺度、因果一致的轨迹。总之,这些组件保留了VLM的泛化性和可解释性,同时实现了高效、准确和安全的轨迹生成。在nuScenes基准上的实验表明,ColaVLA在开环和闭环设置中都实现了最先进的性能,并具有良好的效率和鲁棒性。
🔬 方法详解
问题定义:论文旨在解决自动驾驶中基于视觉-语言模型的轨迹规划问题。现有方法存在三个主要痛点:一是离散的文本推理与连续的车辆控制之间存在gap;二是自回归的链式思考(Chain-of-Thought)解码导致推理延迟过高;三是规划器效率低下或不具备因果一致性,难以满足实时部署需求。
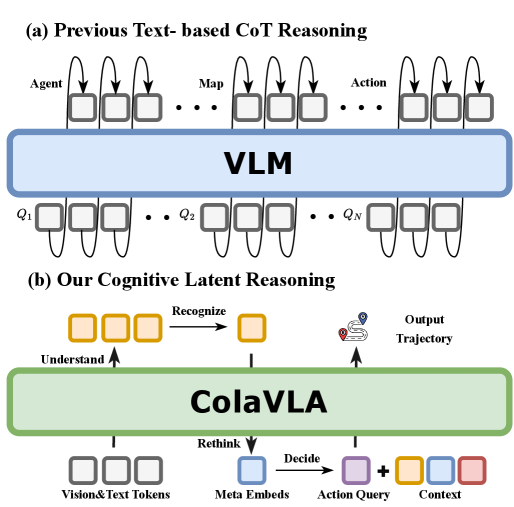
核心思路:论文的核心思路是将视觉-语言模型的推理能力从文本空间转移到统一的潜在空间,并在此基础上构建一个分层并行的轨迹规划器。通过这种方式,既保留了视觉-语言模型的泛化能力和可解释性,又能够实现高效、准确和安全的轨迹生成。
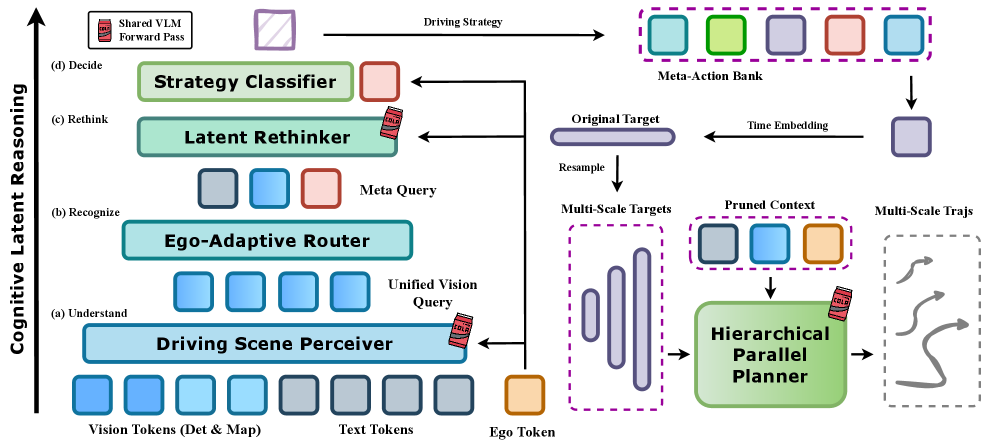
技术框架:ColaVLA框架包含两个主要模块:认知潜在推理器(Cognitive Latent Reasoner)和分层并行规划器(Hierarchical Parallel Planner)。认知潜在推理器负责将场景理解压缩为紧凑的、面向决策的元动作嵌入,它通过自我适应选择和两次VLM正向传递实现。分层并行规划器则基于这些元动作嵌入,在一次正向传递中生成多尺度、因果一致的轨迹。
关键创新:ColaVLA的关键创新在于将视觉-语言模型的推理过程从离散的文本空间转移到了连续的潜在空间。这使得模型能够更好地适应连续控制任务,并避免了自回归解码带来的高延迟问题。此外,分层并行规划器的设计也提高了轨迹生成的效率和因果一致性。
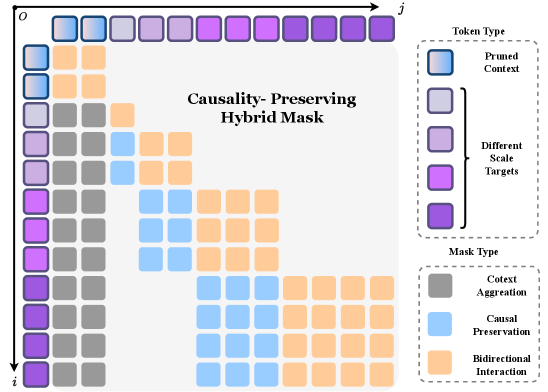
关键设计:认知潜在推理器采用ego-adaptive selection机制来选择与当前车辆状态相关的场景信息,从而提高推理效率。分层并行规划器则通过多尺度轨迹生成和因果一致性约束来保证轨迹的安全性和可靠性。具体的损失函数和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
ColaVLA在nuScenes基准测试中取得了显著的性能提升,在开环和闭环设置下均达到了state-of-the-art水平。具体的数据指标(例如平均位移误差、碰撞率等)以及与现有方法的对比结果在论文中进行了详细展示(未知)。实验结果表明,ColaVLA在效率和鲁棒性方面也具有优势。
🎯 应用场景
ColaVLA的研究成果可应用于自动驾驶车辆的运动规划和决策控制,尤其是在复杂交通场景和需要常识推理的场景下。该方法能够提高自动驾驶系统的安全性、可靠性和效率,并有望加速自动驾驶技术的商业化落地。此外,该研究思路也可以推广到其他需要视觉-语言理解和连续控制的机器人应用中。
📄 摘要(原文)
Autonomous driving requires generating safe and reliable trajectories from complex multimodal inputs. Traditional modular pipelines separate perception, prediction, and planning, while recent end-to-end (E2E) systems learn them jointly. Vision-language models (VLMs) further enrich this paradigm by introducing cross-modal priors and commonsense reasoning, yet current VLM-based planners face three key challenges: (i) a mismatch between discrete text reasoning and continuous control, (ii) high latency from autoregressive chain-of-thought decoding, and (iii) inefficient or non-causal planners that limit real-time deployment. We propose ColaVLA, a unified vision-language-action framework that transfers reasoning from text to a unified latent space and couples it with a hierarchical, parallel trajectory decoder. The Cognitive Latent Reasoner compresses scene understanding into compact, decision-oriented meta-action embeddings through ego-adaptive selection and only two VLM forward passes. The Hierarchical Parallel Planner then generates multi-scale, causality-consistent trajectories in a single forward pass. Together, these components preserve the generalization and interpretability of VLMs while enabling efficient, accurate and safe trajectory generation. Experiments on the nuScenes benchmark show that ColaVLA achieves state-of-the-art performance in both open-loop and closed-loop settings with favorable efficiency and robustness.