JavisGPT: A Unified Multi-modal LLM for Sounding-Video Comprehension and Generation
作者: Kai Liu, Jungang Li, Yuchong Sun, Shengqiong Wu, Jianzhang Gao, Daoan Zhang, Wei Zhang, Sheng Jin, Sicheng Yu, Geng Zhan, Jiayi Ji, Fan Zhou, Liang Zheng, Shuicheng Yan, Hao Fei, Tat-Seng Chua
分类: cs.CV
发布日期: 2025-12-28 (更新: 2026-01-02)
备注: Accepted by NeurIPS as a Spotlight paper. Code: https://github.com/JavisVerse/JavisGPT
💡 一句话要点
JavisGPT:用于音视频理解与生成的多模态统一大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 音视频理解 音视频生成 大语言模型 时序建模
📋 核心要点
- 现有MLLM在处理音视频联合理解和生成任务时,缺乏对时序信息的有效建模和多模态信息的深度融合。
- JavisGPT通过SyncFusion模块和同步感知可学习查询,实现了时空音视频融合和时间连贯的生成。
- JavisGPT在音视频理解和生成基准测试中,显著优于现有模型,尤其在时序同步场景下表现突出。
📝 摘要(中文)
本文提出了JavisGPT,首个用于联合音视频(JAV)理解和生成的多模态大型语言模型(MLLM)。JavisGPT采用简洁的编码器-LLM-解码器架构,包含一个用于时空音视频融合的SyncFusion模块,以及同步感知可学习查询,以桥接预训练的JAV-DiT生成器。这种设计使得能够从多模态指令中进行时间连贯的视频-音频理解和生成。我们设计了一个有效的三阶段训练流程,包括多模态预训练、音视频微调和大规模指令调优,以逐步从现有的视觉-语言模型构建多模态理解和生成能力。对于指令调优,我们构建了JavisInst-Omni,一个高质量的指令数据集,包含超过20万个GPT-4o策划的音视频-文本对话,涵盖多样化和多层次的理解和生成场景。在JAV理解和生成基准测试中,实验表明JavisGPT优于现有的MLLM,尤其是在复杂和时间同步设置中。
🔬 方法详解
问题定义:现有方法在音视频理解和生成任务中,难以有效捕捉音视频之间的时序依赖关系和模态间的细粒度交互,导致在复杂场景下性能受限。特别是在需要时间同步的音视频生成任务中,现有模型难以保证生成内容的时序一致性。
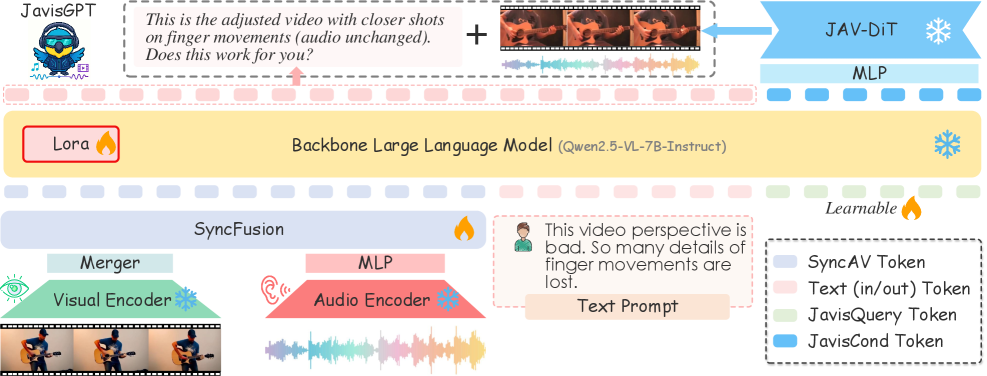
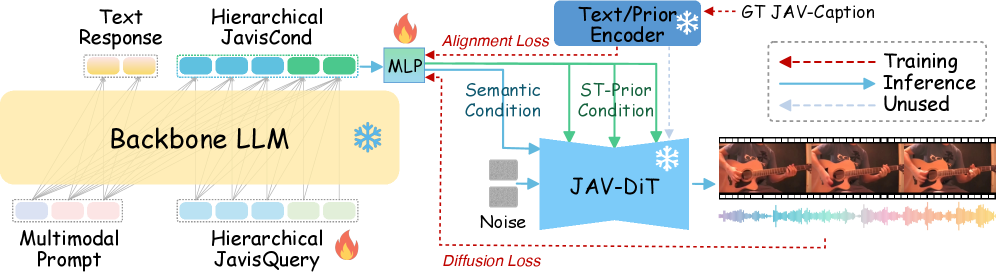
核心思路:JavisGPT的核心思路是构建一个统一的多模态大语言模型,通过显式地建模音视频的时空关系,并利用大规模指令调优,提升模型在音视频理解和生成任务中的性能。模型通过SyncFusion模块融合音视频特征,并使用同步感知可学习查询来指导生成过程,从而保证生成内容的时序一致性。
技术框架:JavisGPT采用编码器-LLM-解码器的架构。编码器负责提取音视频特征,SyncFusion模块融合音视频特征,LLM负责理解指令并生成文本描述,解码器(JAV-DiT)根据文本描述生成音视频内容。整个流程包括多模态预训练、音视频微调和大规模指令调优三个阶段。
关键创新:JavisGPT的关键创新在于SyncFusion模块和同步感知可学习查询的设计。SyncFusion模块通过时空注意力机制,有效融合音视频特征,捕捉模态间的依赖关系。同步感知可学习查询则通过学习音视频之间的同步关系,指导生成过程,保证生成内容的时序一致性。此外,JavisInst-Omni数据集的构建也为模型的指令调优提供了高质量的数据支持。
关键设计:SyncFusion模块采用多层Transformer结构,每一层包含时序注意力和跨模态注意力。时序注意力用于捕捉单个模态内的时序依赖关系,跨模态注意力用于融合音视频特征。同步感知可学习查询则通过学习一组可学习的向量,表示音视频之间的同步关系。在训练过程中,模型采用多任务学习策略,同时优化音视频理解和生成任务的损失函数。
🖼️ 关键图片

📊 实验亮点
JavisGPT在音视频理解和生成基准测试中取得了显著的性能提升。在多个数据集上,JavisGPT的性能均优于现有的多模态大语言模型。尤其是在需要时间同步的音视频生成任务中,JavisGPT的表现尤为突出,生成的内容在时序上更加连贯和自然。具体性能数据在论文中有详细展示。
🎯 应用场景
JavisGPT在视频编辑、内容创作、智能助手等领域具有广泛的应用前景。例如,可以用于自动生成带有背景音乐的视频,或者根据用户的语音指令编辑视频内容。此外,JavisGPT还可以应用于智能监控系统,用于分析监控视频中的声音和图像信息,从而实现更智能的安全监控。
📄 摘要(原文)
This paper presents JavisGPT, the first unified multimodal large language model (MLLM) for joint audio-video (JAV) comprehension and generation. JavisGPT has a concise encoder-LLM-decoder architecture, which has a SyncFusion module for spatio-temporal audio-video fusion and synchrony-aware learnable queries to bridge a pretrained JAV-DiT generator. This design enables temporally coherent video-audio understanding and generation from multimodal instructions. We design an effective three-stage training pipeline consisting of multimodal pretraining, audio-video fine-tuning, and large-scale instruction-tuning, to progressively build multimodal comprehension and generation from existing vision-language models. For instruction tuning, we construct JavisInst-Omni, a high-quality instruction dataset with over 200K GPT-4o-curated audio-video-text dialogues that cover diverse and multi-level comprehension and generation scenarios. On JAV comprehension and generation benchmarks, our experiments show that JavisGPT outperforms existing MLLMs, particularly in complex and temporally synchronized settings.