SwinTF3D: A Lightweight Multimodal Fusion Approach for Text-Guided 3D Medical Image Segmentation
作者: Hasan Faraz Khan, Noor Fatima, Muzammil Behzad
分类: cs.CV, cs.AI
发布日期: 2025-12-28
💡 一句话要点
SwinTF3D:一种轻量级多模态融合方法,用于文本引导的3D医学图像分割
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D医学图像分割 文本引导 多模态融合 Swin Transformer 自然语言处理
📋 核心要点
- 现有3D医学图像分割方法依赖大量标注数据进行视觉学习,缺乏语义理解,难以适应新领域和临床任务。
- SwinTF3D通过融合视觉和语言表征,利用文本引导实现3D医学图像分割,提升模型对用户自定义分割目标的理解。
- 实验表明,SwinTF3D在保证分割精度的同时,具有更低的计算开销,并能有效泛化到未见过的数据。
📝 摘要(中文)
本文提出SwinTF3D,一种轻量级多模态融合方法,用于文本引导的3D医学图像分割,旨在克服现有3D分割框架仅依赖视觉学习、缺乏语义理解的局限性。该模型利用基于Transformer的视觉编码器提取体数据特征,并通过高效的融合机制将其与紧凑的文本编码器集成。这种设计使系统能够理解自然语言提示,并将语义线索与医学体数据中相应的空间结构正确对齐,从而以低计算开销产生准确、上下文感知的分割结果。在BTCV数据集上的大量实验表明,SwinTF3D以其紧凑的架构,在多个器官上实现了具有竞争力的Dice和IoU分数,并且能够很好地泛化到未见过的数据。SwinTF3D将视觉感知与语言理解相结合,为交互式、文本驱动的3D医学图像分割建立了一种实用且可解释的范例,为临床成像中更具适应性和资源效率的解决方案开辟了前景。
🔬 方法详解
问题定义:现有3D医学图像分割方法主要依赖于对大量标注的视觉数据进行学习,缺乏对图像内容的语义理解。这导致模型难以适应新的临床任务和领域,无法根据用户的具体需求进行灵活的分割,例如根据文本描述分割特定区域。
核心思路:SwinTF3D的核心思路是将视觉信息和语言信息进行融合,利用自然语言描述来引导3D医学图像的分割。通过将文本信息融入到分割过程中,模型可以更好地理解用户的意图,并根据文本描述对图像进行更精确的分割。
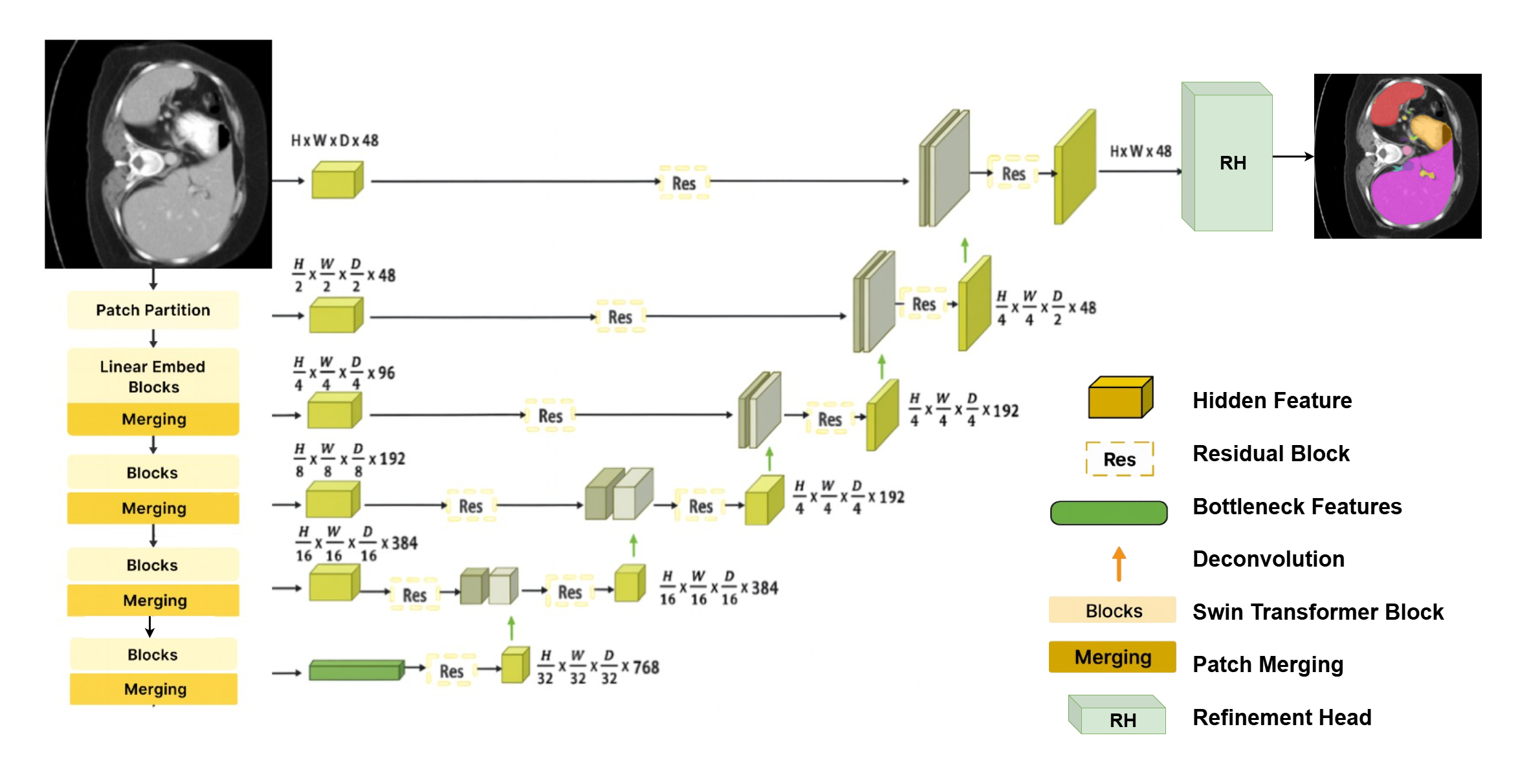
技术框架:SwinTF3D主要包含三个模块:视觉编码器、文本编码器和融合模块。视觉编码器采用基于Transformer的架构,用于提取3D医学图像的特征。文本编码器则用于提取自然语言描述的语义信息。融合模块将视觉特征和文本特征进行融合,得到最终的分割结果。整体流程为:输入3D医学图像和文本描述,分别通过视觉编码器和文本编码器提取特征,然后通过融合模块将特征融合,最后输出分割结果。
关键创新:SwinTF3D的关键创新在于其轻量级多模态融合方法。与传统的3D分割网络相比,SwinTF3D引入了文本引导,使得模型能够理解用户的意图,并根据文本描述进行分割。此外,SwinTF3D采用轻量级的架构,降低了计算开销,使其更易于部署和应用。
关键设计:SwinTF3D的视觉编码器采用Swin Transformer,文本编码器采用一个紧凑的Transformer模型。融合模块采用注意力机制,将视觉特征和文本特征进行加权融合。损失函数采用Dice Loss和Cross-Entropy Loss的组合,用于优化分割结果。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
SwinTF3D在BTCV数据集上进行了广泛的实验,结果表明,该模型在多个器官上实现了具有竞争力的Dice和IoU分数。与传统的Transformer-based分割网络相比,SwinTF3D具有更低的计算开销和更好的泛化能力。实验结果证明了SwinTF3D在文本引导的3D医学图像分割方面的有效性和优越性。
🎯 应用场景
SwinTF3D在临床医学图像分析领域具有广泛的应用前景,例如辅助医生进行器官分割、病灶检测和手术规划。通过文本引导,医生可以根据具体需求对图像进行分割,提高诊断效率和准确性。该研究还有助于推动医学影像人工智能的发展,为更智能化的医疗服务提供技术支持。
📄 摘要(原文)
The recent integration of artificial intelligence into medical imaging has driven remarkable advances in automated organ segmentation. However, most existing 3D segmentation frameworks rely exclusively on visual learning from large annotated datasets restricting their adaptability to new domains and clinical tasks. The lack of semantic understanding in these models makes them ineffective in addressing flexible, user-defined segmentation objectives. To overcome these limitations, we propose SwinTF3D, a lightweight multimodal fusion approach that unifies visual and linguistic representations for text-guided 3D medical image segmentation. The model employs a transformer-based visual encoder to extract volumetric features and integrates them with a compact text encoder via an efficient fusion mechanism. This design allows the system to understand natural-language prompts and correctly align semantic cues with their corresponding spatial structures in medical volumes, while producing accurate, context-aware segmentation results with low computational overhead. Extensive experiments on the BTCV dataset demonstrate that SwinTF3D achieves competitive Dice and IoU scores across multiple organs, despite its compact architecture. The model generalizes well to unseen data and offers significant efficiency gains compared to conventional transformer-based segmentation networks. Bridging visual perception with linguistic understanding, SwinTF3D establishes a practical and interpretable paradigm for interactive, text-driven 3D medical image segmentation, opening perspectives for more adaptive and resource-efficient solutions in clinical imaging.