M-ErasureBench: A Comprehensive Multimodal Evaluation Benchmark for Concept Erasure in Diffusion Models
作者: Ju-Hsuan Weng, Jia-Wei Liao, Cheng-Fu Chou, Jun-Cheng Chen
分类: cs.CV
发布日期: 2025-12-28
💡 一句话要点
M-ErasureBench:用于评估扩散模型概念擦除的多模态综合基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 概念擦除 扩散模型 多模态评估 鲁棒性增强 潜在变量反演
📋 核心要点
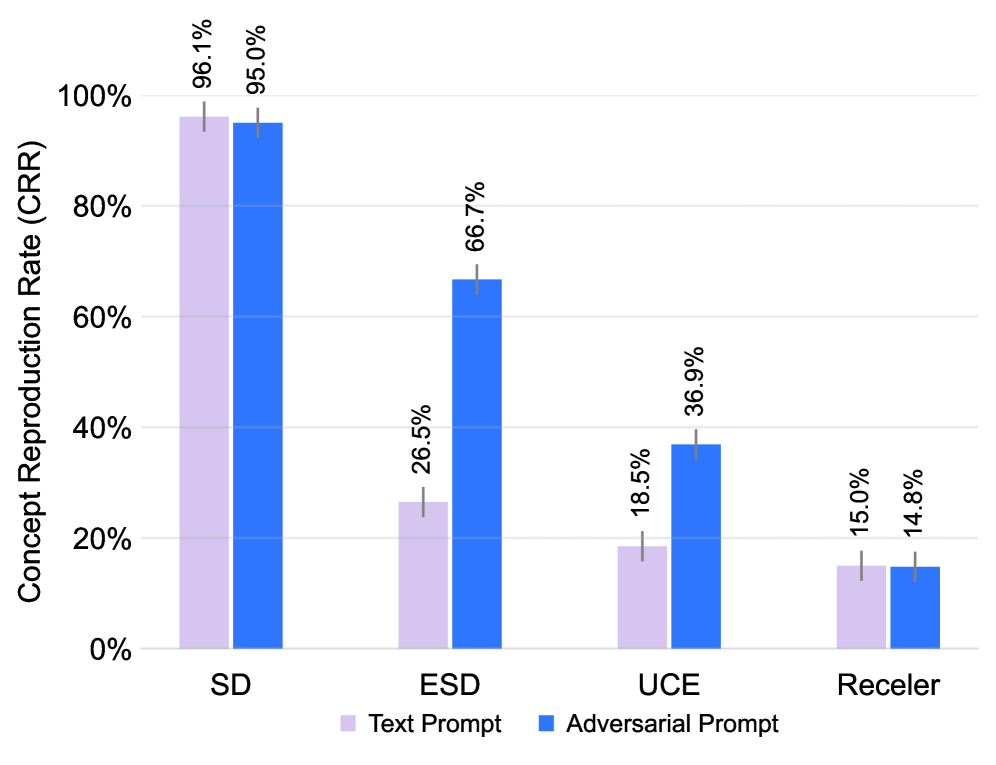
- 现有概念擦除方法主要关注文本提示,忽略了图像编辑等应用中其他模态的攻击风险。
- 提出IRECE模块,通过交叉注意力定位并扰动潜在变量,增强概念擦除的鲁棒性。
- M-ErasureBench基准测试表明,IRECE在白盒潜在反演场景下可将CRR降低高达40%。
📝 摘要(中文)
文本到图像的扩散模型可能生成有害或受版权保护的内容,这促使了对概念擦除的研究。然而,现有的方法主要集中于从文本提示中擦除概念,忽略了其他输入模态,而这些模态在图像编辑和个性化生成等实际应用中正变得越来越重要。这些模态可能成为攻击面,导致已擦除的概念重新出现,尽管存在防御措施。为了弥合这一差距,我们引入了M-ErasureBench,这是一个新颖的多模态评估框架,它系统地对跨三种输入模态(文本提示、学习嵌入和反演潜在变量)的概念擦除方法进行基准测试。对于后两种模态,我们评估了白盒和黑盒访问,产生了五种评估场景。我们的分析表明,现有方法在文本提示方面实现了强大的擦除性能,但在学习嵌入和反演潜在变量方面大多失败,在白盒设置中概念重现率(CRR)超过90%。为了解决这些漏洞,我们提出了IRECE(用于概念擦除的推理时鲁棒性增强),这是一个即插即用模块,它通过交叉注意力定位目标概念,并在去噪过程中扰动相关的潜在变量。实验表明,IRECE始终恢复鲁棒性,在最具挑战性的白盒潜在反演场景下,CRR降低了高达40%,同时保持了视觉质量。据我们所知,M-ErasureBench提供了第一个超越文本提示的概念擦除综合基准。与IRECE一起,我们的基准为构建更可靠的保护性生成模型提供了实用的保障。
🔬 方法详解
问题定义:现有概念擦除方法主要针对文本提示,忽略了其他输入模态(如学习嵌入和反演潜在变量)可能存在的概念重现风险。这些模态在图像编辑和个性化生成等实际应用中越来越重要,但现有方法在这些模态下的擦除效果不佳,存在安全隐患。
核心思路:论文的核心思路是针对扩散模型在不同输入模态下的概念擦除问题,提出一个通用的评估基准和一个鲁棒性增强模块。通过系统地评估现有方法在不同模态下的表现,发现其弱点,并利用提出的IRECE模块来提高概念擦除的鲁棒性。
技术框架:M-ErasureBench评估框架包含三个输入模态:文本提示、学习嵌入和反演潜在变量。针对后两种模态,分别进行白盒和黑盒评估,共计五种评估场景。IRECE模块是一个即插即用模块,在推理阶段工作,通过交叉注意力机制定位与目标概念相关的潜在变量,并对其进行扰动,从而增强概念擦除的鲁棒性。
关键创新:论文的关键创新在于:1) 提出了一个多模态的概念擦除评估基准M-ErasureBench,首次系统地评估了现有方法在不同输入模态下的表现;2) 提出了一个推理时鲁棒性增强模块IRECE,能够有效地提高概念擦除的鲁棒性,尤其是在最具挑战性的白盒潜在反演场景下。
关键设计:IRECE模块的关键设计包括:1) 使用交叉注意力机制来定位与目标概念相关的潜在变量;2) 设计了一种扰动策略,对定位到的潜在变量进行扰动,以阻止目标概念的生成。具体的扰动策略和参数设置(如扰动强度)需要根据具体的扩散模型和目标概念进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有方法在文本提示方面表现良好,但在学习嵌入和反演潜在变量方面表现不佳,概念重现率(CRR)超过90%。IRECE模块能够显著提高概念擦除的鲁棒性,在最具挑战性的白盒潜在反演场景下,CRR降低了高达40%,同时保持了视觉质量。
🎯 应用场景
该研究成果可应用于构建更安全的生成模型,防止生成有害或受版权保护的内容。例如,可以用于图像编辑工具中,确保用户无法通过修改图像重新引入已被擦除的概念。此外,该研究也有助于提高个性化生成模型的安全性,防止模型生成包含用户隐私信息的图像。
📄 摘要(原文)
Text-to-image diffusion models may generate harmful or copyrighted content, motivating research on concept erasure. However, existing approaches primarily focus on erasing concepts from text prompts, overlooking other input modalities that are increasingly critical in real-world applications such as image editing and personalized generation. These modalities can become attack surfaces, where erased concepts re-emerge despite defenses. To bridge this gap, we introduce M-ErasureBench, a novel multimodal evaluation framework that systematically benchmarks concept erasure methods across three input modalities: text prompts, learned embeddings, and inverted latents. For the latter two, we evaluate both white-box and black-box access, yielding five evaluation scenarios. Our analysis shows that existing methods achieve strong erasure performance against text prompts but largely fail under learned embeddings and inverted latents, with Concept Reproduction Rate (CRR) exceeding 90% in the white-box setting. To address these vulnerabilities, we propose IRECE (Inference-time Robustness Enhancement for Concept Erasure), a plug-and-play module that localizes target concepts via cross-attention and perturbs the associated latents during denoising. Experiments demonstrate that IRECE consistently restores robustness, reducing CRR by up to 40% under the most challenging white-box latent inversion scenario, while preserving visual quality. To the best of our knowledge, M-ErasureBench provides the first comprehensive benchmark of concept erasure beyond text prompts. Together with IRECE, our benchmark offers practical safeguards for building more reliable protective generative models.