MUSON: A Reasoning-oriented Multimodal Dataset for Socially Compliant Navigation in Urban Environments
作者: Zhuonan Liu, Xinyu Zhang, Zishuo Wang, Tomohito Kawabata, Xuesu Xiao, Ling Xiao
分类: cs.CV, cs.RO
发布日期: 2025-12-28
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
MUSON:面向城市环境社交合规导航的推理型多模态数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 社交导航 多模态数据集 链式思考 视觉语言模型 城市环境 机器人 推理 合规性
📋 核心要点
- 现有社交导航数据集缺乏推理监督,动作分布长尾,难以学习安全行为。
- MUSON数据集通过链式思考标注,显式建模物理约束,平衡动作空间,提供更全面的社交导航数据。
- 实验表明,Qwen2.5-VL-3B在MUSON数据集上取得了0.8625的决策准确率,验证了数据集的有效性。
📝 摘要(中文)
本文提出了MUSON,一个用于短时程社交导航的多模态数据集,该数据集涵盖了多样化的室内和室外校园场景。社交合规导航需要在动态行人以及物理约束上进行结构化推理,以确保安全且可解释的决策。然而,现有的社交导航数据集通常缺乏显式的推理监督,并且呈现出高度长尾的动作分布,限制了模型学习安全关键行为的能力。MUSON采用了一个结构化的五步链式思考标注,包括感知、预测、推理、行动和解释,并显式地建模了静态物理约束以及一个理性平衡的离散动作空间。与SNEI相比,MUSON提供了连贯的推理、行动和解释。在MUSON上对多个最先进的小型视觉语言模型进行基准测试表明,Qwen2.5-VL-3B实现了最高的决策准确率0.8625,证明了MUSON可以作为一个有效且可复用的社交合规导航基准。
🔬 方法详解
问题定义:现有的社交导航数据集在模拟真实世界行人交互时存在不足,主要体现在缺乏明确的推理过程监督,以及动作分布呈现长尾效应,导致模型难以学习到安全且符合社会规范的导航策略。这些问题限制了模型在复杂城市环境中安全导航的能力。
核心思路:MUSON数据集的核心思路是通过引入结构化的“链式思考”(Chain-of-Thought)标注,显式地建模智能体在导航过程中的推理步骤。同时,通过平衡离散动作空间,并考虑静态物理约束,来构建一个更全面、更具代表性的社交导航数据集,从而促进模型学习更安全、更合理的导航策略。
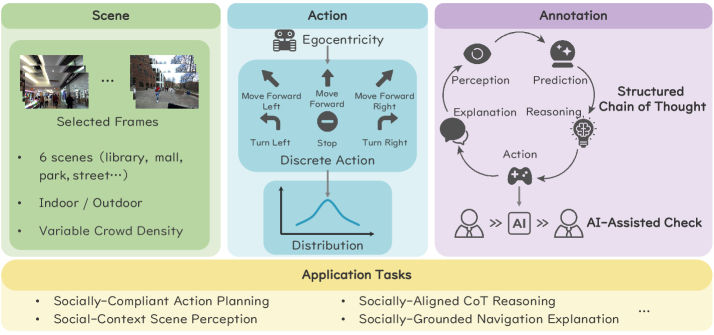
技术框架:MUSON数据集的标注流程包含五个主要步骤:感知(Perception)、预测(Prediction)、推理(Reasoning)、行动(Action)和解释(Explanation)。感知模块负责从场景中提取视觉信息;预测模块用于预测行人的未来轨迹;推理模块基于感知和预测结果,进行逻辑推理,判断最佳行动方案;行动模块执行选定的导航动作;解释模块提供行动的理由,增强模型的可解释性。数据集还显式地建模了静态物理约束,例如墙壁、障碍物等。
关键创新:MUSON数据集的关键创新在于其结构化的链式思考标注方法,以及对静态物理约束的显式建模。传统的社交导航数据集通常只提供输入图像和对应的动作标签,而MUSON数据集则提供了更丰富的推理过程信息,有助于模型学习更深层次的导航策略。此外,对物理约束的建模也使得模型能够更好地理解环境,避免碰撞等安全问题。
关键设计:MUSON数据集采用了离散动作空间,并对其进行了平衡,以避免长尾效应。数据集的标注人员需要为每个场景生成五步链式思考标注,并确保推理、行动和解释的一致性。数据集的规模和多样性也经过精心设计,以覆盖各种常见的社交导航场景。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Qwen2.5-VL-3B在MUSON数据集上实现了0.8625的决策准确率,显著优于其他基线模型。这表明MUSON数据集能够有效评估和提升社交导航模型的性能,并为未来的研究提供了一个可靠的基准。
🎯 应用场景
MUSON数据集可应用于开发更安全、更智能的社交导航机器人,例如服务型机器人、自动驾驶汽车等。通过在该数据集上训练模型,可以提高机器人在复杂城市环境中与行人安全交互的能力,并使其导航决策更具可解释性。该数据集也有助于研究人员探索基于视觉语言模型的社交导航方法。
📄 摘要(原文)
Socially compliant navigation requires structured reasoning over dynamic pedestrians and physical constraints to ensure safe and interpretable decisions. However, existing social navigation datasets often lack explicit reasoning supervision and exhibit highly long-tailed action distributions, limiting models' ability to learn safety-critical behaviors. To address these issues, we introduce MUSON, a multimodal dataset for short-horizon social navigation collected across diverse indoor and outdoor campus scenes. MUSON adopts a structured five-step Chain-of-Thought annotation consisting of perception, prediction, reasoning, action, and explanation, with explicit modeling of static physical constraints and a rationally balanced discrete action space. Compared to SNEI, MUSON provides consistent reasoning, action, and explanation. Benchmarking multiple state-of-the-art Small Vision Language Models on MUSON shows that Qwen2.5-VL-3B achieves the highest decision accuracy of 0.8625, demonstrating that MUSON serves as an effective and reusable benchmark for socially compliant navigation. The dataset is publicly available at https://huggingface.co/datasets/MARSLab/MUSON