Depth Anything in $360^\circ$: Towards Scale Invariance in the Wild
作者: Hualie Jiang, Ziyang Song, Zhiqiang Lou, Rui Xu, Minglang Tan
分类: cs.CV
发布日期: 2025-12-28
备注: https://insta360-research-team.github.io/DA360
💡 一句话要点
提出DA360以解决360度全景深度估计的尺度不变性问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 全景深度估计 尺度不变性 机器人导航 增强现实 虚拟现实 深度学习 计算机视觉
📋 核心要点
- 现有的全景深度估计方法在开放世界领域的零-shot泛化能力较差,无法有效利用丰富的透视图像训练数据。
- 本文提出DA360,通过学习位移参数和整合圆形填充,解决了尺度不变性和接缝伪影的问题,提升了深度估计的准确性。
- DA360在室内和户外基准测试中相较于基线模型分别减少了50%和10%的相对深度误差,且在多个测试数据集上超越了现有的全景深度估计方法。
📝 摘要(中文)
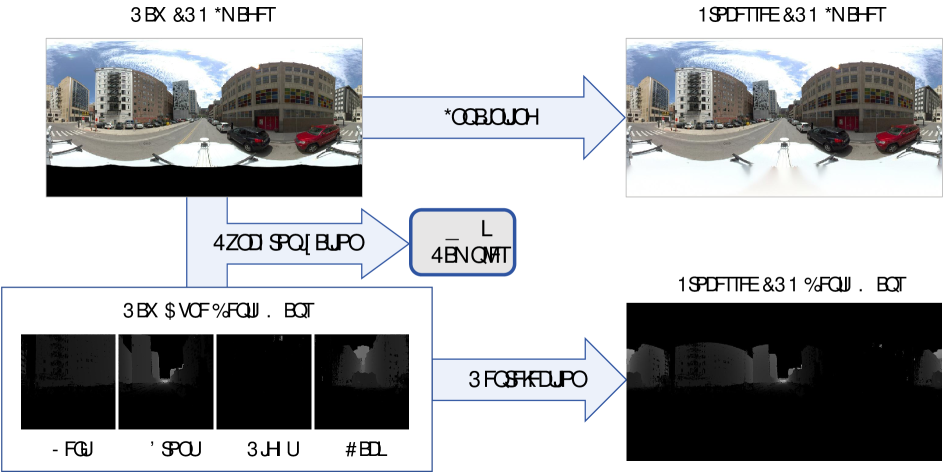
全景深度估计为捕捉完整的360度环境结构信息提供了全面的解决方案,对机器人和增强现实/虚拟现实应用具有重要意义。然而,尽管在室内环境中得到了广泛研究,其在开放世界领域的零-shot泛化能力仍远不及透视图像。为了解决这一问题,本文提出了Depth Anything in $360^ extcirc$ (DA360),这是Depth Anything V2的全景适配版本。我们的关键创新在于从ViT骨干网络中学习一个位移参数,将模型的尺度和位移不变输出转化为直接生成良好3D点云的尺度不变估计。此外,结合圆形填充到DPT解码器中,消除了接缝伪影,确保了空间一致的深度图。DA360在标准室内基准和新创建的户外数据集Metropolis上评估,显示出显著的性能提升。
🔬 方法详解
问题定义:本文旨在解决360度全景深度估计在开放世界中的尺度不变性问题。现有方法在室内环境中表现良好,但在实际应用中缺乏有效的零-shot泛化能力,导致性能不足。
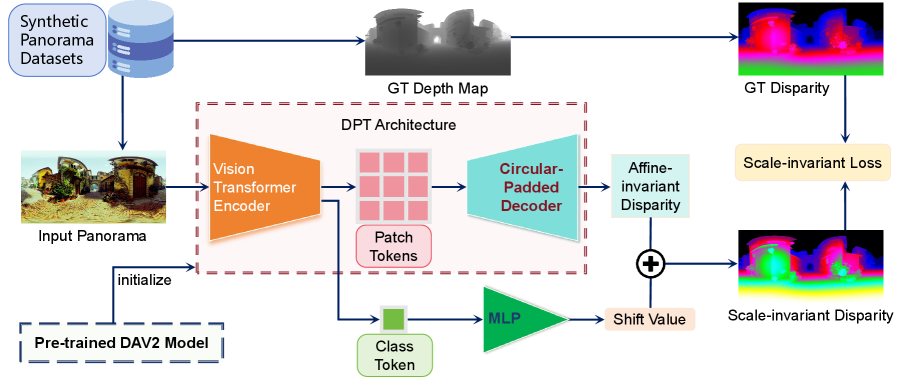
核心思路:论文的核心思路是通过学习一个位移参数,将模型输出转化为尺度不变的深度估计,从而直接生成高质量的3D点云。这种设计能够有效克服传统方法在尺度变化下的局限性。
技术框架:整体架构包括ViT骨干网络、DPT解码器和圆形填充模块。ViT网络负责特征提取,DPT解码器用于生成深度图,而圆形填充则用于消除接缝伪影,确保深度图的空间一致性。
关键创新:最重要的技术创新是引入了位移参数学习和圆形填充技术。这与现有方法的本质区别在于,DA360不仅关注深度估计的准确性,还考虑了输出的空间一致性和连续性。
关键设计:在网络结构上,DA360采用了ViT作为骨干网络,并在DPT解码器中集成了圆形填充。此外,损失函数设计上注重深度图的空间一致性,确保生成的深度图在视觉上无缝连接。
🖼️ 关键图片

📊 实验亮点
DA360在标准室内基准测试中实现了超过50%的相对深度误差减少,在户外基准测试中也达到了10%的误差降低。此外,相较于PanDA等稳健的全景深度估计方法,DA360在所有三个测试数据集上实现了约30%的相对误差改善,确立了零-shot全景深度估计的新状态。
🎯 应用场景
该研究的潜在应用领域包括机器人导航、增强现实和虚拟现实等场景。通过提供高质量的360度深度估计,DA360能够显著提升这些应用的环境理解能力和交互体验,具有广泛的实际价值和未来影响。
📄 摘要(原文)
Panoramic depth estimation provides a comprehensive solution for capturing complete $360^\circ$ environmental structural information, offering significant benefits for robotics and AR/VR applications. However, while extensively studied in indoor settings, its zero-shot generalization to open-world domains lags far behind perspective images, which benefit from abundant training data. This disparity makes transferring capabilities from the perspective domain an attractive solution. To bridge this gap, we present Depth Anything in $360^\circ$ (DA360), a panoramic-adapted version of Depth Anything V2. Our key innovation involves learning a shift parameter from the ViT backbone, transforming the model's scale- and shift-invariant output into a scale-invariant estimate that directly yields well-formed 3D point clouds. This is complemented by integrating circular padding into the DPT decoder to eliminate seam artifacts, ensuring spatially coherent depth maps that respect spherical continuity. Evaluated on standard indoor benchmarks and our newly curated outdoor dataset, Metropolis, DA360 shows substantial gains over its base model, achieving over 50\% and 10\% relative depth error reduction on indoor and outdoor benchmarks, respectively. Furthermore, DA360 significantly outperforms robust panoramic depth estimation methods, achieving about 30\% relative error improvement compared to PanDA across all three test datasets and establishing new state-of-the-art performance for zero-shot panoramic depth estimation.