Plug In, Grade Right: Psychology-Inspired AGIQA
作者: Zhicheng Liao, Baoliang Chen, Hanwei Zhu, Lingyu Zhu, Shiqi Wang, Weisi Lin
分类: cs.CV, eess.IV
发布日期: 2025-12-28
💡 一句话要点
提出基于心理测量学的AGIQA模型,解决语义漂移问题,提升图像质量评估准确性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像质量评估 AGIQA 分级响应模型 心理测量学 语义漂移
📋 核心要点
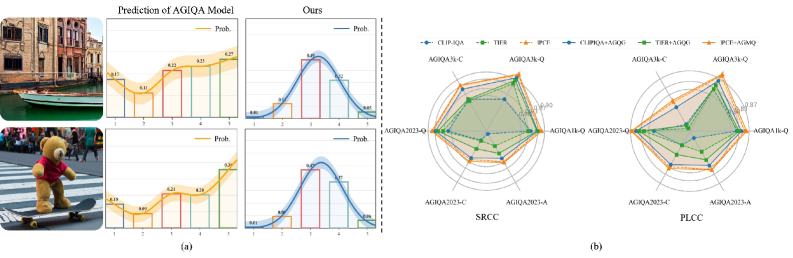
- 现有AGIQA模型依赖相似度分布,但存在“语义漂移”问题,导致质量评估不准确。
- 借鉴心理测量学GRM模型,将图像质量评估视为图像满足不同质量等级的能力。
- 提出的AGQG模块具有即插即用优势,可提升现有AGIQA框架性能,并泛化到不同类型图像。
📝 摘要(中文)
现有的AGIQA模型通常通过测量和聚合图像嵌入与来自多等级质量描述的文本嵌入之间的相似性来估计图像质量。尽管有效,但我们观察到跨等级的这种相似性分布通常表现出多模态模式。例如,一个图像嵌入可能与“优秀”和“差”等级描述都表现出高相似性,但与“良好”等级描述相差甚远。我们将这种现象称为“语义漂移”,即文本嵌入与其预期描述之间的语义不一致性会削弱文本-图像共享空间学习的可靠性。为了缓解这个问题,我们从心理测量学中汲取灵感,并提出了一种改进的用于AGIQA的分级响应模型(GRM)。GRM是一种经典的评估模型,它使用具有不同难度级别的测试项目对受试者在各个等级上的能力进行分类。这种范式与人类质量评级非常吻合,其中图像质量可以解释为图像满足各种质量等级的能力。基于这种理念,我们设计了一个双分支质量分级模块:一个分支估计图像能力,而另一个分支构建多个难度级别。为了确保难度级别的单调性,我们进一步以算术方式对难度生成进行建模,这固有地强制执行单峰且可解释的质量分布。我们基于算术GRM的质量分级(AGQG)模块具有即插即用的优势,当集成到各种最先进的AGIQA框架中时,始终可以提高性能。此外,它还可以有效地推广到自然图像和屏幕内容图像质量评估,揭示了其作为未来IQA模型关键组件的潜力。
🔬 方法详解
问题定义:现有AGIQA模型通过比较图像和文本嵌入的相似度进行质量评估,但这种相似度分布常常呈现多模态,导致“语义漂移”现象,即图像可能同时与多个极端质量等级的描述相似,而与中间等级不符。这降低了评估的可靠性。
核心思路:借鉴心理测量学中的分级响应模型(GRM),将图像质量评估类比为测试学生能力。图像的质量等级对应于学生的能力等级,而不同质量等级的描述对应于不同难度的测试题目。通过评估图像“通过”不同难度等级的“测试”的能力,来确定其质量等级。这样可以更好地模拟人类的质量评估过程。
技术框架:论文提出了一个双分支的质量分级模块AGQG。一个分支用于估计图像的“能力”,即图像的质量水平;另一个分支用于构建多个难度级别,对应于不同的质量等级。这两个分支共同决定图像的最终质量评分。该模块可以作为插件集成到现有的AGIQA框架中。
关键创新:核心创新在于将心理测量学中的GRM模型引入到AGIQA领域,并设计了相应的网络结构来实现这一思想。通过模拟人类的质量评估过程,可以更准确地捕捉图像的质量特征,并缓解语义漂移问题。此外,使用算术方式建模难度生成,保证了难度级别的单调性,从而确保了质量分布的合理性。
关键设计:为了保证难度级别的单调性,论文采用算术方式生成难度级别,即每个难度级别在前一个级别的基础上增加一个固定的步长。这种设计简化了难度级别的建模,并确保了其单调性。损失函数的设计也至关重要,需要能够有效地训练网络,使其能够准确地估计图像的能力和难度级别。具体的网络结构和损失函数细节在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
AGQG模块作为插件集成到多个SOTA的AGIQA模型中,均取得了性能提升。实验结果表明,该方法在自然图像和屏幕内容图像质量评估方面都表现出色,验证了其有效性和泛化能力。具体的性能提升数据在论文中进行了详细展示。
🎯 应用场景
该研究成果可广泛应用于图像质量评估领域,例如图像增强算法的评估、图像压缩算法的优化、视频监控系统的质量监控等。此外,该方法还可以扩展到其他需要进行多等级评估的领域,例如产品质量评估、用户体验评估等,具有广泛的应用前景。
📄 摘要(原文)
Existing AGIQA models typically estimate image quality by measuring and aggregating the similarities between image embeddings and text embeddings derived from multi-grade quality descriptions. Although effective, we observe that such similarity distributions across grades usually exhibit multimodal patterns. For instance, an image embedding may show high similarity to both "excellent" and "poor" grade descriptions while deviating from the "good" one. We refer to this phenomenon as "semantic drift", where semantic inconsistencies between text embeddings and their intended descriptions undermine the reliability of text-image shared-space learning. To mitigate this issue, we draw inspiration from psychometrics and propose an improved Graded Response Model (GRM) for AGIQA. The GRM is a classical assessment model that categorizes a subject's ability across grades using test items with various difficulty levels. This paradigm aligns remarkably well with human quality rating, where image quality can be interpreted as an image's ability to meet various quality grades. Building on this philosophy, we design a two-branch quality grading module: one branch estimates image ability while the other constructs multiple difficulty levels. To ensure monotonicity in difficulty levels, we further model difficulty generation in an arithmetic manner, which inherently enforces a unimodal and interpretable quality distribution. Our Arithmetic GRM based Quality Grading (AGQG) module enjoys a plug-and-play advantage, consistently improving performance when integrated into various state-of-the-art AGIQA frameworks. Moreover, it also generalizes effectively to both natural and screen content image quality assessment, revealing its potential as a key component in future IQA models.