Envision: Embodied Visual Planning via Goal-Imagery Video Diffusion
作者: Yuming Gu, Yizhi Wang, Yining Hong, Yipeng Gao, Hao Jiang, Angtian Wang, Bo Liu, Nathaniel S. Dennler, Zhengfei Kuang, Hao Li, Gordon Wetzstein, Chongyang Ma
分类: cs.CV
发布日期: 2025-12-27
备注: Page: https://envision-paper.github.io
💡 一句话要点
Envision:基于目标图像视频扩散的具身视觉规划框架,解决空间漂移和目标不一致问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱四:生成式动作 (Generative Motion)
关键词: 具身视觉规划 视频扩散模型 目标导向生成 机器人操作 图像编辑
📋 核心要点
- 现有具身视觉规划方法依赖前向预测,忽略了目标建模,导致生成轨迹容易出现空间漂移和目标不一致的问题。
- Envision通过引入目标图像作为显式约束,利用扩散模型生成连接起始状态和目标状态的平滑视频轨迹,保证物理合理性和目标一致性。
- 实验表明,Envision在物体操作和图像编辑任务上,相比现有方法,显著提升了目标对齐、空间一致性和物体保持能力。
📝 摘要(中文)
本文提出Envision,一个基于扩散模型的具身智能体视觉规划框架。现有方法主要采用前向预测,仅根据初始观测生成轨迹,缺乏显式的目标建模,导致空间漂移和目标不一致。Envision通过目标图像显式约束生成过程,保证生成轨迹的物理合理性和目标一致性。该方法分为两个阶段:首先,目标图像模型识别任务相关区域,执行场景和指令之间的区域感知交叉注意力,合成连贯的目标图像;然后,Env-Goal视频模型基于首尾帧条件视频扩散模型(FL2V),在初始观测和目标图像之间插值,生成平滑且物理上合理的视频轨迹,连接起始和目标状态。在物体操作和图像编辑基准测试中,Envision优于现有方法,实现了更好的目标对齐、空间一致性和物体保持。生成的视觉规划可以直接支持下游机器人规划和控制。
🔬 方法详解
问题定义:具身视觉规划旨在通过想象场景如何演变为期望的目标状态,并利用想象的轨迹来指导智能体的动作。然而,现有方法主要依赖于前向预测,即基于初始观测生成轨迹,而缺乏对目标状态的显式建模。这导致生成的轨迹容易出现空间漂移,最终状态与期望目标不一致,难以用于指导实际的机器人操作。
核心思路:Envision的核心思路是通过显式地将目标图像作为约束条件融入到视频生成过程中,从而确保生成的轨迹不仅在视觉上是连贯的,而且能够可靠地引导智能体达到期望的目标状态。这种方法避免了传统前向预测方法中容易出现的漂移问题,提高了规划的准确性和可靠性。
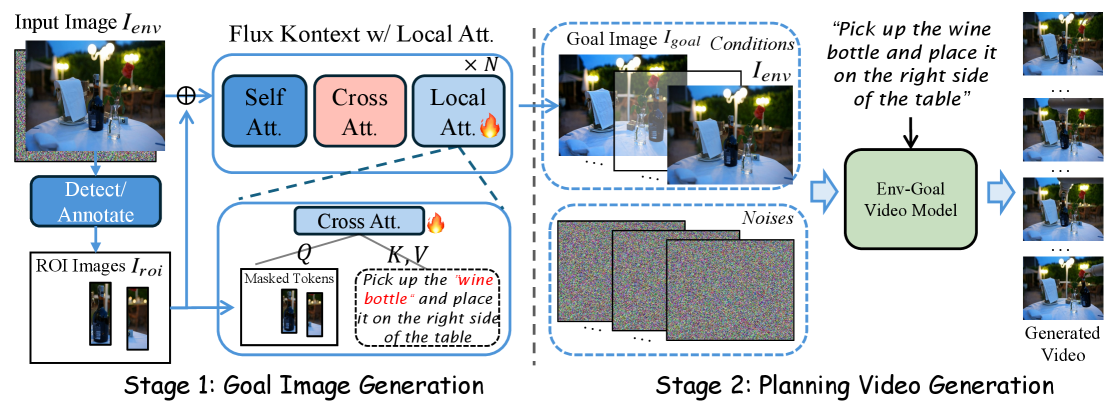
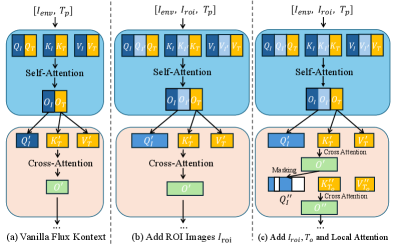
技术框架:Envision框架包含两个主要模块:目标图像模型(Goal Imagery Model)和环境-目标视频模型(Env-Goal Video Model)。首先,目标图像模型接收初始场景图像和任务指令,通过区域感知的交叉注意力机制,生成一个与任务目标对齐的目标图像。然后,环境-目标视频模型利用首尾帧条件视频扩散模型(FL2V),将初始场景图像和生成的目标图像作为条件,生成一系列中间帧,形成一个平滑的视频轨迹。
关键创新:Envision的关键创新在于将目标图像显式地融入到视频生成过程中,从而实现了目标导向的视觉规划。与传统的仅依赖初始状态进行前向预测的方法不同,Envision通过目标图像约束,确保生成的轨迹能够可靠地引导智能体达到期望的目标状态。这种方法显著提高了规划的准确性和可靠性。
关键设计:目标图像模型采用区域感知的交叉注意力机制,关注与任务相关的图像区域,并融合指令信息,生成高质量的目标图像。环境-目标视频模型基于FL2V,通过调整扩散模型的训练策略,使其能够更好地处理起始帧和目标帧之间的插值问题。具体的损失函数和网络结构细节在论文中有详细描述,但未在此处明确指出。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Envision在物体操作和图像编辑任务上均取得了显著的性能提升。与基线方法相比,Envision在目标对齐、空间一致性和物体保持方面均有明显优势。具体的数据指标和对比结果在论文中进行了详细展示,证明了Envision的有效性和优越性。
🎯 应用场景
Envision在机器人操作、图像编辑等领域具有广泛的应用前景。它可以用于指导机器人完成复杂的物体操作任务,例如装配、抓取等。在图像编辑领域,Envision可以用于生成从初始图像到目标图像的平滑过渡动画,例如将一个物体从一个位置移动到另一个位置。该研究有望推动具身智能和机器人技术的进一步发展。
📄 摘要(原文)
Embodied visual planning aims to enable manipulation tasks by imagining how a scene evolves toward a desired goal and using the imagined trajectories to guide actions. Video diffusion models, through their image-to-video generation capability, provide a promising foundation for such visual imagination. However, existing approaches are largely forward predictive, generating trajectories conditioned on the initial observation without explicit goal modeling, thus often leading to spatial drift and goal misalignment. To address these challenges, we propose Envision, a diffusion-based framework that performs visual planning for embodied agents. By explicitly constraining the generation with a goal image, our method enforces physical plausibility and goal consistency throughout the generated trajectory. Specifically, Envision operates in two stages. First, a Goal Imagery Model identifies task-relevant regions, performs region-aware cross attention between the scene and the instruction, and synthesizes a coherent goal image that captures the desired outcome. Then, an Env-Goal Video Model, built upon a first-and-last-frame-conditioned video diffusion model (FL2V), interpolates between the initial observation and the goal image, producing smooth and physically plausible video trajectories that connect the start and goal states. Experiments on object manipulation and image editing benchmarks demonstrate that Envision achieves superior goal alignment, spatial consistency, and object preservation compared to baselines. The resulting visual plans can directly support downstream robotic planning and control, providing reliable guidance for embodied agents.