Self-Rewarded Multimodal Coherent Reasoning Across Diverse Visual Domains
作者: Jesen Zhang, Ningyuan Liu, Kaitong Cai, Sidi Liu, Jing Yang, Ziliang Chen, Xiaofei Sun, Keze Wang
分类: cs.CV, cs.AI
发布日期: 2025-12-27
💡 一句话要点
提出SR-MCR框架,通过自奖励机制提升多模态LLM在视觉领域的推理连贯性和准确性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉推理 自奖励学习 大型语言模型 过程监督
📋 核心要点
- 现有方法仅关注最终答案监督,忽略了多模态LLM中间推理过程的可靠性,导致推理连贯性和视觉基础不足。
- SR-MCR框架利用模型自身输出的内在信号,通过自奖励机制对齐推理过程,无需额外标签。
- SR-MCR在多个视觉基准测试中显著提升了答案准确性和推理连贯性,并在同等规模开源模型中达到领先水平。
📝 摘要(中文)
多模态大型语言模型(LLM)通常产生流畅但不甚可靠的推理结果,表现出较弱的逐步连贯性和不足的视觉基础。这主要是因为现有的对齐方法仅监督最终答案,而忽略了中间推理过程的可靠性。我们引入了SR-MCR,一个轻量级且无标签的框架,通过利用直接从模型输出中获得的内在过程信号来对齐推理。五个自参照线索——语义对齐、词汇保真度、非冗余性、视觉基础和步骤一致性——被整合到一个归一化的、可靠性加权的奖励中,从而提供细粒度的过程级指导。一种无评论家的GRPO目标,通过置信度感知的冷却机制增强,进一步稳定了训练并抑制了琐碎或过度自信的生成。基于Qwen2.5-VL,SR-MCR提高了各种视觉基准上的答案准确性和推理连贯性;在同等规模的开源模型中,SR-MCR-7B实现了最先进的性能,平均准确率为81.4%。消融研究证实了每个奖励项和冷却模块的独立贡献。
🔬 方法详解
问题定义:多模态大型语言模型在视觉推理任务中,虽然能够生成流畅的文本,但其推理过程往往缺乏连贯性,并且对视觉信息的理解不够深入。现有的对齐方法主要关注最终答案的正确性,而忽略了中间推理步骤的合理性和可靠性,导致模型容易产生“幻觉”或不准确的推理。
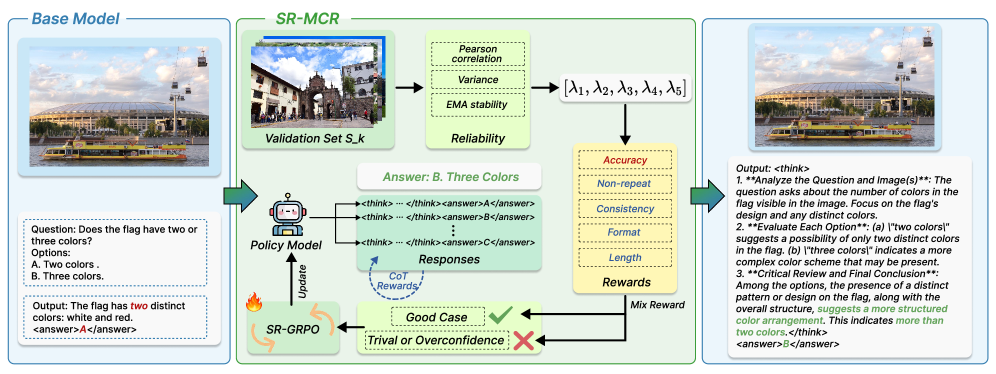
核心思路:SR-MCR的核心思想是利用模型自身生成的中间推理过程作为反馈信号,通过自奖励机制来引导模型进行更连贯、更可靠的推理。它假设一个好的推理过程应该具备语义对齐、词汇保真度、非冗余性、视觉基础和步骤一致性等特征。通过对这些特征进行量化,并将其转化为奖励信号,可以有效地监督模型的中间推理过程。
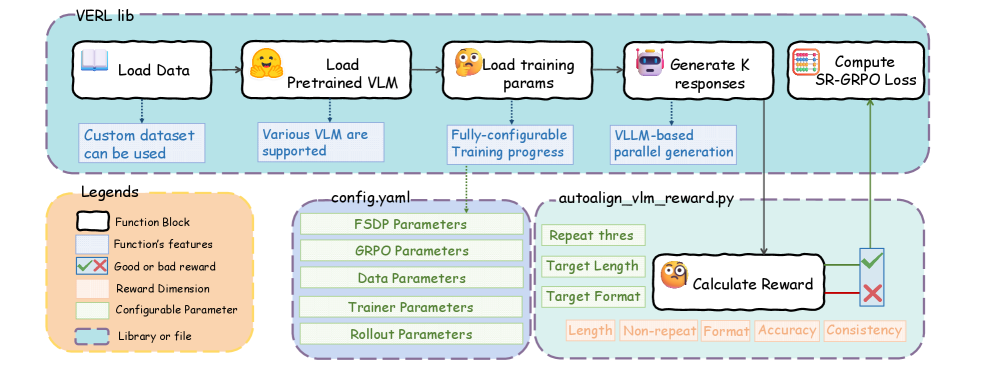
技术框架:SR-MCR框架主要包含以下几个模块:1) 多模态LLM:作为推理的主体,负责接收视觉输入并生成推理过程和最终答案。2) 自奖励模块:负责评估模型生成的推理过程,并根据五个自参照线索计算奖励信号。3) GRPO优化器:利用计算得到的奖励信号,对模型进行优化,使其能够生成更连贯、更可靠的推理过程。4) 置信度感知的冷却机制:用于稳定训练过程,并抑制模型生成过于自信或琐碎的答案。
关键创新:SR-MCR的关键创新在于提出了一个轻量级且无标签的自奖励框架,能够有效地监督多模态LLM的中间推理过程。与传统的监督学习方法相比,SR-MCR不需要人工标注的中间推理步骤,而是直接利用模型自身的输出作为反馈信号,从而降低了标注成本,并提高了模型的泛化能力。此外,SR-MCR还引入了置信度感知的冷却机制,进一步稳定了训练过程,并提高了模型的性能。
关键设计:SR-MCR的关键设计包括:1) 五个自参照线索的定义和量化方法,例如,语义对齐通过计算推理步骤与问题之间的语义相似度来衡量。2) 奖励信号的归一化和加权方法,确保不同线索的奖励信号能够有效地整合。3) GRPO优化器的具体实现,以及置信度感知的冷却机制的参数设置。例如,冷却系数的设置会影响训练的稳定性和收敛速度。
🖼️ 关键图片
📊 实验亮点
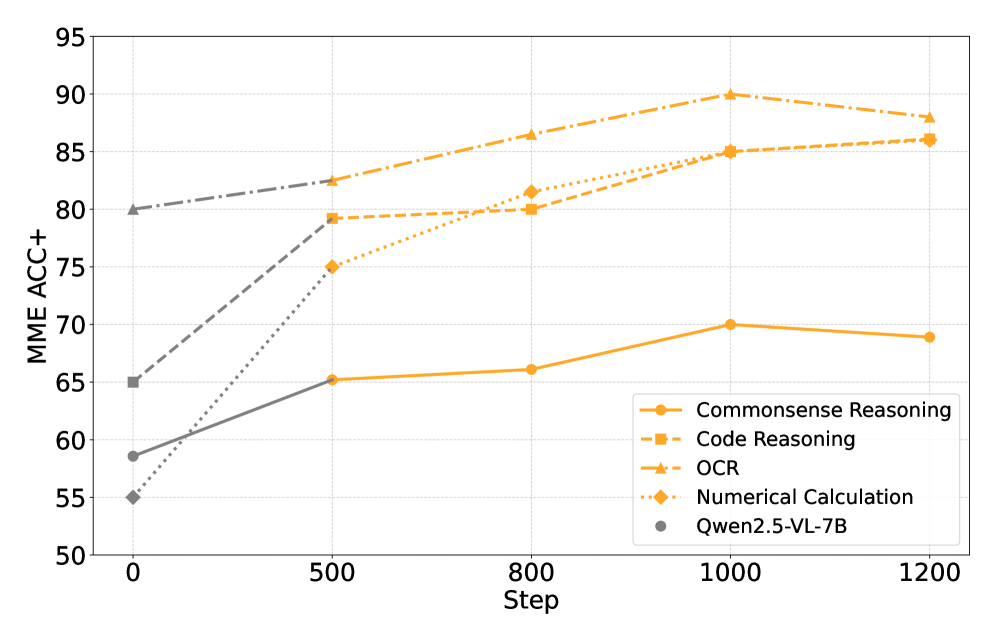
SR-MCR在多个视觉基准测试中取得了显著的性能提升。例如,在平均准确率方面,SR-MCR-7B达到了81.4%,在同等规模的开源模型中实现了最先进的性能。消融实验表明,每个奖励项和冷却模块都对最终性能有独立的贡献,验证了SR-MCR框架的有效性。
🎯 应用场景
SR-MCR框架可应用于各种需要多模态信息融合和复杂推理的场景,例如视觉问答、图像描述生成、机器人导航等。该研究有助于提升AI系统在理解和处理视觉信息方面的能力,使其能够更准确、更可靠地完成各种任务,具有广泛的应用前景。
📄 摘要(原文)
Multimodal LLMs often produce fluent yet unreliable reasoning, exhibiting weak step-to-step coherence and insufficient visual grounding, largely because existing alignment approaches supervise only the final answer while ignoring the reliability of the intermediate reasoning process. We introduce SR-MCR, a lightweight and label-free framework that aligns reasoning by exploiting intrinsic process signals derived directly from model outputs. Five self-referential cues -- semantic alignment, lexical fidelity, non-redundancy, visual grounding, and step consistency -- are integrated into a normalized, reliability-weighted reward that provides fine-grained process-level guidance. A critic-free GRPO objective, enhanced with a confidence-aware cooling mechanism, further stabilizes training and suppresses trivial or overly confident generations. Built on Qwen2.5-VL, SR-MCR improves both answer accuracy and reasoning coherence across a broad set of visual benchmarks; among open-source models of comparable size, SR-MCR-7B achieves state-of-the-art performance with an average accuracy of 81.4%. Ablation studies confirm the independent contributions of each reward term and the cooling module.