Tracking by Predicting 3-D Gaussians Over Time
作者: Tanish Baranwal, Himanshu Gaurav Singh, Jathushan Rajasegaran, Jitendra Malik
分类: cs.CV
发布日期: 2025-12-27 (更新: 2025-12-30)
🔗 代码/项目: GITHUB
💡 一句话要点
提出Video-GMAE,通过预测3D高斯演化实现视频表征学习与目标跟踪。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视频表征学习 自监督学习 3D高斯 目标跟踪 掩码自编码器
📋 核心要点
- 现有视频表征学习方法缺乏对3D场景结构的有效建模,限制了其在目标跟踪等任务中的性能。
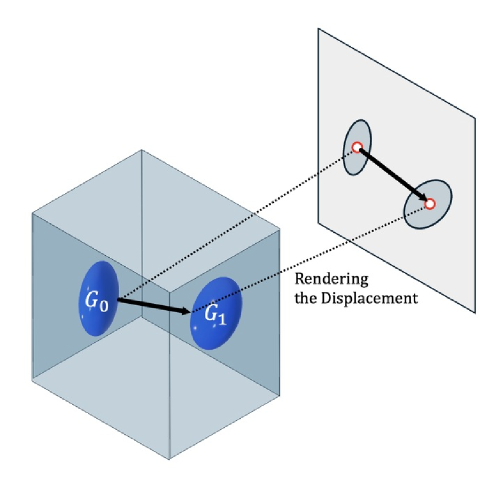
- Video-GMAE将视频帧编码为一组3D高斯斑点,利用高斯分布的运动轨迹来表示视频中的动态信息。
- 实验表明,Video-GMAE在零样本跟踪上表现出色,微调后在Kinetics和Kubric数据集上显著超越现有方法。
📝 摘要(中文)
我们提出了一种名为视频高斯掩码自编码器(Video-GMAE)的自监督表征学习方法,该方法将图像序列编码为一组随时间移动的3D高斯斑点。将视频表示为一组高斯分布,强制执行了一个合理的归纳偏置:即2D视频通常是动态3D场景的一致投影。我们发现,使用这种架构预训练网络时,可以涌现出目标跟踪能力。将学习到的高斯轨迹映射到图像平面上,可以获得与最先进水平相当的零样本跟踪性能。通过小规模的微调,我们的模型在Kinetics数据集上实现了34.6%的改进,在Kubric数据集上实现了13.1%的改进,超过了现有的自监督视频方法。项目主页和代码已公开。
🔬 方法详解
问题定义:现有视频表征学习方法难以有效捕捉视频中蕴含的3D场景结构和动态信息,导致在目标跟踪等下游任务中性能受限。缺乏对3D场景的建模能力,使得模型难以理解视频中物体的运动轨迹和遮挡关系,从而影响跟踪的准确性和鲁棒性。
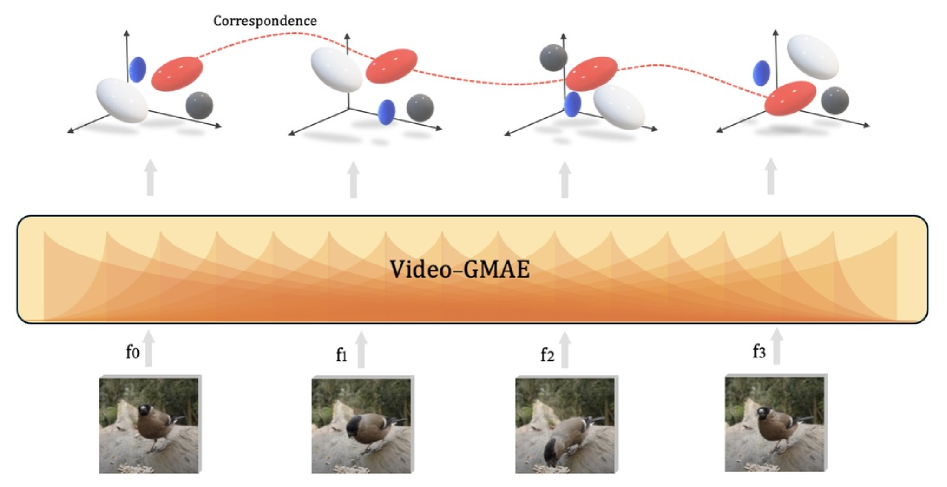
核心思路:论文的核心思路是将视频帧编码为一组随时间演化的3D高斯斑点。通过学习这些高斯斑点的运动轨迹,模型可以隐式地学习到视频中物体的3D结构和运动信息。这种基于3D高斯的表示方法,能够更好地捕捉视频中的动态信息,并为目标跟踪等任务提供更有效的特征表示。
技术框架:Video-GMAE的整体架构是一个自编码器结构,包含编码器和解码器两个主要模块。编码器将输入的视频帧序列编码为一组3D高斯斑点,每个高斯斑点包含位置、尺度、旋转等参数。解码器则根据这些高斯斑点的参数,重构出原始的视频帧序列。通过自监督学习的方式,模型可以学习到有效的视频表征,并涌现出目标跟踪能力。
关键创新:最重要的技术创新点在于将视频表示为一组3D高斯斑点,并利用高斯斑点的运动轨迹来表示视频中的动态信息。与传统的基于像素或特征点的视频表示方法相比,基于3D高斯的表示方法能够更好地捕捉视频中的3D结构和运动信息,从而提高目标跟踪等任务的性能。
关键设计:Video-GMAE的关键设计包括:1) 使用掩码自编码器(MAE)进行预训练,提高模型的表征学习能力;2) 设计特定的损失函数,鼓励模型学习到准确的3D高斯斑点参数;3) 使用Transformer结构来建模高斯斑点之间的关系,从而更好地捕捉视频中的动态信息。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
Video-GMAE在Kinetics数据集上实现了34.6%的性能提升,在Kubric数据集上实现了13.1%的性能提升,显著超越了现有的自监督视频表征学习方法。此外,该方法在零样本目标跟踪任务中也表现出色,无需任何训练数据即可达到与最先进水平相当的性能。这些实验结果表明,Video-GMAE能够有效地学习到视频中的3D结构和运动信息,并为各种下游任务提供更有效的特征表示。
🎯 应用场景
Video-GMAE具有广泛的应用前景,包括视频目标跟踪、动作识别、视频编辑和三维重建等领域。该方法可以用于开发更智能的视频监控系统、更精确的运动分析工具和更逼真的虚拟现实体验。此外,Video-GMAE还可以应用于自动驾驶领域,帮助车辆更好地理解周围环境,提高行驶安全性。
📄 摘要(原文)
We propose Video Gaussian Masked Autoencoders (Video-GMAE), a self-supervised approach for representation learning that encodes a sequence of images into a set of Gaussian splats moving over time. Representing a video as a set of Gaussians enforces a reasonable inductive bias: that 2-D videos are often consistent projections of a dynamic 3-D scene. We find that tracking emerges when pretraining a network with this architecture. Mapping the trajectory of the learnt Gaussians onto the image plane gives zero-shot tracking performance comparable to state-of-the-art. With small-scale finetuning, our models achieve 34.6% improvement on Kinetics, and 13.1% on Kubric datasets, surpassing existing self-supervised video approaches. The project page and code are publicly available at https://videogmae.org/ and https://github.com/tekotan/video-gmae.