VULCAN: Tool-Augmented Multi Agents for Iterative 3D Object Arrangement
作者: Zhengfei Kuang, Rui Lin, Long Zhao, Gordon Wetzstein, Saining Xie, Sanghyun Woo
分类: cs.CV, cs.AI
发布日期: 2025-12-26 (更新: 2026-01-06)
💡 一句话要点
VULCAN:工具增强的多智能体迭代式3D物体排列方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D物体排列 多模态大型语言模型 多智能体系统 视觉工具 人机交互
📋 核心要点
- 现有MLLM在3D场景操作中应用不足,主要挑战在于视觉基础薄弱,难以将语言指令与精确的3D操作关联。
- VULCAN通过引入MCP-based API、视觉工具和多智能体框架,增强MLLM的3D场景理解和操作能力。
- 实验表明,VULCAN在复杂3D物体排列任务中显著优于现有基线,验证了其有效性。
📝 摘要(中文)
尽管多模态大型语言模型(MLLM)在2D视觉-语言任务中取得了显著进展,但它们在复杂3D场景操作中的应用仍未得到充分探索。本文通过使用MLLM解决3D物体排列任务中的三个关键挑战,弥补了这一重要差距。首先,为了解决MLLM的弱视觉基础问题,即难以将程序编辑与精确的3D结果联系起来,我们引入了基于MCP的API。这使得交互从脆弱的原始代码操作转变为更健壮的函数级更新。其次,我们使用一套专门的视觉工具来增强MLLM的3D场景理解能力,以分析场景状态、收集空间信息和验证动作结果。这种感知反馈循环对于弥合基于语言的更新和精确的3D感知操作之间的差距至关重要。第三,为了管理迭代的、容易出错的更新,我们提出了一个协作的多智能体框架,为规划、执行和验证指定角色。这种分解使系统能够稳健地处理多步骤指令并从中间错误中恢复。我们在25个复杂的物体排列任务中证明了该方法的有效性,它明显优于现有的基线。
🔬 方法详解
问题定义:论文旨在解决3D物体排列任务,即根据给定的指令,在3D场景中合理地安排物体。现有方法,特别是直接使用MLLM的方法,存在视觉基础薄弱的问题,难以将语言指令转化为精确的3D操作,容易出错且难以调试。
核心思路:论文的核心思路是利用工具增强的多智能体框架,将复杂的3D物体排列任务分解为规划、执行和验证三个阶段,并使用专门的视觉工具来增强MLLM的3D场景理解能力,从而提高操作的准确性和鲁棒性。
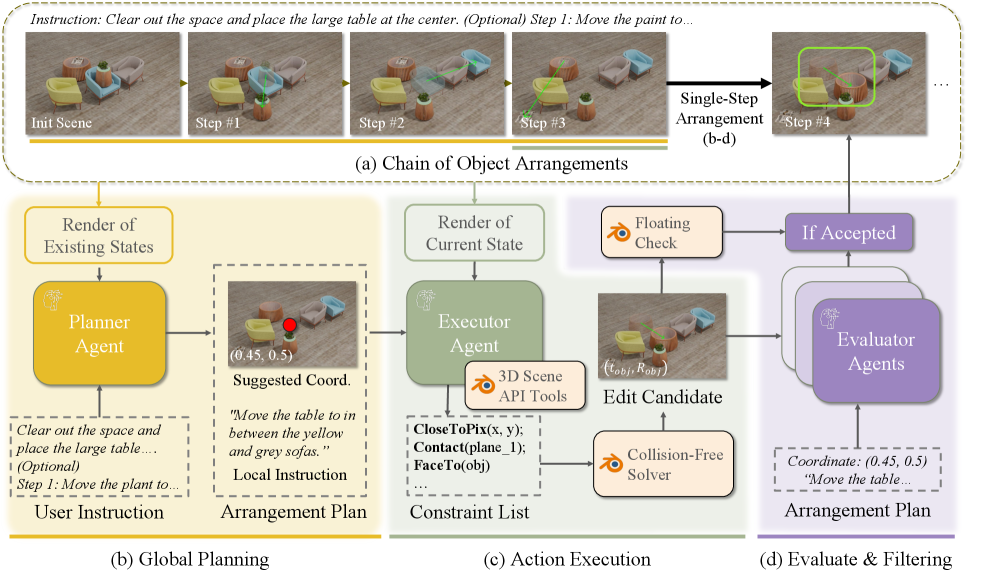
技术框架:VULCAN框架包含三个主要模块:规划智能体、执行智能体和验证智能体。规划智能体负责将高层指令分解为一系列可执行的步骤;执行智能体负责根据规划的步骤,调用MCP-based API和视觉工具来执行3D操作;验证智能体负责验证执行结果,并提供反馈信息,以便进行迭代优化。整个过程是一个迭代循环,直到满足指令要求。
关键创新:论文的关键创新在于以下几个方面:1) 引入了MCP-based API,将原始代码操作转化为更健壮的函数级更新;2) 使用专门的视觉工具来增强MLLM的3D场景理解能力;3) 提出了协作的多智能体框架,将任务分解为规划、执行和验证三个阶段,从而提高操作的鲁棒性。与现有方法相比,VULCAN能够更准确、更鲁棒地完成3D物体排列任务。
关键设计:MCP-based API的具体函数包括物体选择、位置调整、旋转等操作。视觉工具包括场景状态分析、空间信息收集和动作结果验证等功能。多智能体框架中,每个智能体都有明确的角色和职责,并通过共享信息进行协作。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
VULCAN在25个复杂的物体排列任务中进行了评估,实验结果表明,VULCAN显著优于现有基线方法。具体的性能数据和提升幅度在摘要中未给出,属于未知信息。但整体而言,实验结果验证了VULCAN在3D物体排列任务中的有效性和优越性。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、机器人等领域,例如智能家居场景设计、虚拟环境搭建、机器人操作等。通过结合自然语言指令和3D场景理解,可以实现更智能、更便捷的人机交互,提高工作效率和用户体验。未来,该技术有望应用于更复杂的3D场景操作和任务规划。
📄 摘要(原文)
Despite the remarkable progress of Multimodal Large Language Models (MLLMs) in 2D vision-language tasks, their application to complex 3D scene manipulation remains underexplored. In this paper, we bridge this critical gap by tackling three key challenges in 3D object arrangement task using MLLMs. First, to address the weak visual grounding of MLLMs, which struggle to link programmatic edits with precise 3D outcomes, we introduce an MCP-based API. This shifts the interaction from brittle raw code manipulation to more robust, function-level updates. Second, we augment the MLLM's 3D scene understanding with a suite of specialized visual tools to analyze scene state, gather spatial information, and validate action outcomes. This perceptual feedback loop is critical for closing the gap between language-based updates and precise 3D-aware manipulation. Third, to manage the iterative, error-prone updates, we propose a collaborative multi-agent framework with designated roles for planning, execution, and verification. This decomposition allows the system to robustly handle multi-step instructions and recover from intermediate errors. We demonstrate the effectiveness of our approach on a diverse set of 25 complex object arrangement tasks, where it significantly outperforms existing baselines. Website: vulcan-3d.github.io