Attack-Aware Deepfake Detection under Counter-Forensic Manipulations
作者: Noor Fatima, Hasan Faraz Khan, Muzammil Behzad
分类: cs.CV, cs.AI
发布日期: 2025-12-26
💡 一句话要点
提出一种攻击感知的Deepfake检测器,增强在对抗取证下的鲁棒性与可信度。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: Deepfake检测 对抗取证 红队训练 测试时防御 图像取证 鲁棒性 可解释性
📋 核心要点
- 现有Deepfake检测方法在对抗取证攻击下鲁棒性不足,难以在实际部署中提供可靠的检测结果。
- 该方法结合红队训练和测试时防御,利用双流网络提取语义和取证特征,并生成篡改热图。
- 实验结果表明,该方法在各种攻击下具有近乎完美的排序性能,并实现了低校准误差和最小的拒绝风险。
📝 摘要(中文)
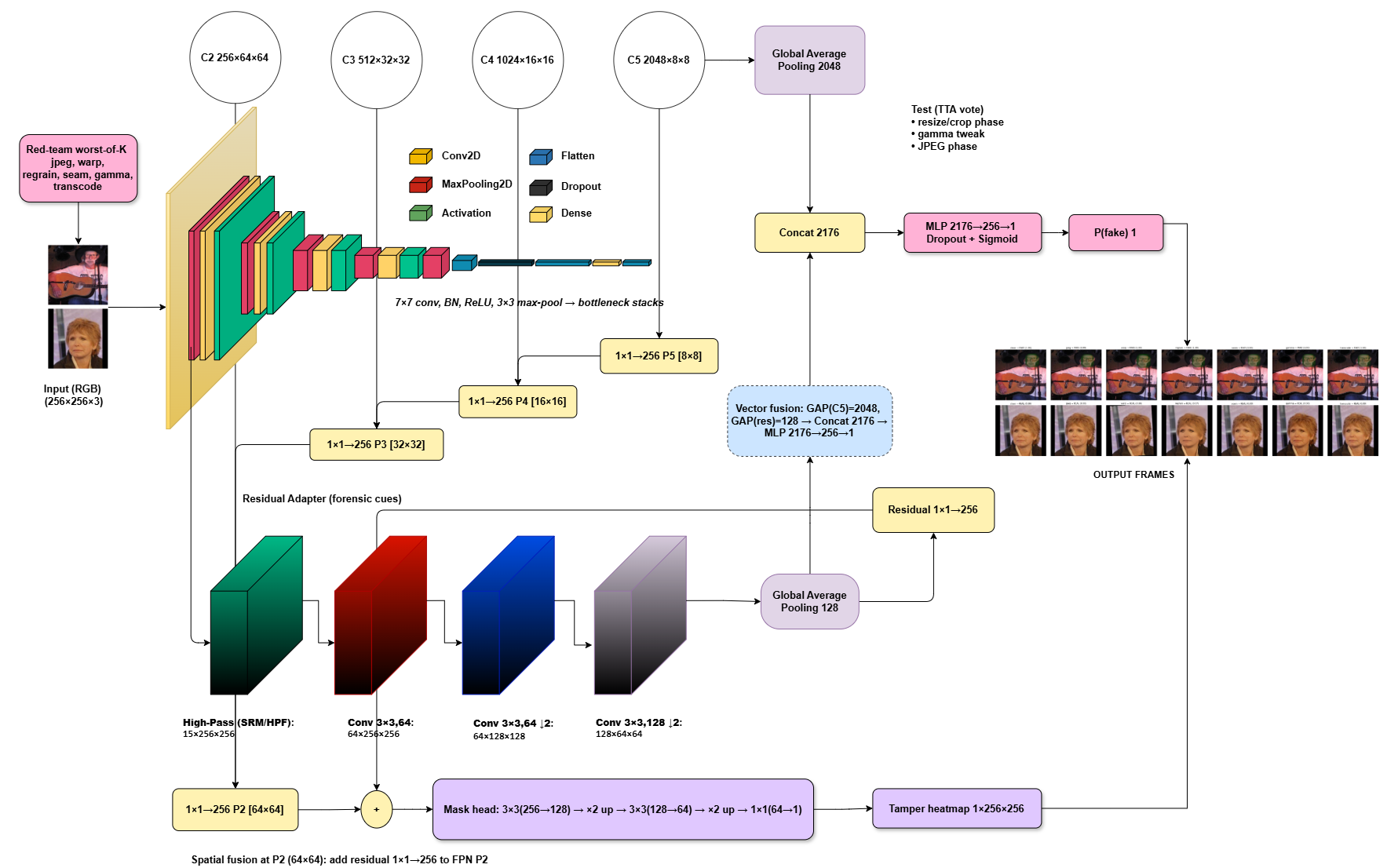
本文提出了一种攻击感知的Deepfake和图像取证检测器,旨在提高在实际部署条件下的鲁棒性、校准良好的概率和透明的证据。该方法结合了红队训练和随机化测试时防御,采用双流架构:一个流使用预训练骨干网络编码语义内容,另一个流提取取证残差,并通过轻量级残差适配器融合进行分类;同时,一个浅层的特征金字塔网络风格的头部在弱监督下生成篡改热图。红队训练对每个批次应用最差的K个对抗取证操作,包括JPEG重对齐和重压缩、重采样扭曲、去噪到重加噪操作、接缝平滑、小的颜色和伽马偏移以及社交应用转码,而测试时防御注入低成本的抖动,如调整大小和裁剪相位变化、轻微的伽马变化和JPEG相位偏移,并聚合预测。热图在面部框掩码的引导下集中在面部区域内,无需严格的像素级注释。在现有基准(包括标准Deepfake数据集和一个具有低光和重压缩的监控风格分割)上的评估报告了干净和攻击下的性能、AUC、最坏情况准确性、可靠性、拒绝质量和弱定位分数。结果表明,在各种攻击下近乎完美的排序、低校准误差、最小的拒绝风险以及在重加噪下的可控降级,从而建立了一个模块化、数据高效且可实际部署的基线,用于具有校准概率和可操作热图的攻击感知检测。
🔬 方法详解
问题定义:现有Deepfake检测器容易受到对抗取证操作的攻击,例如JPEG压缩、图像重采样和噪声添加等。这些操作会破坏Deepfake留下的痕迹,导致检测性能显著下降。因此,需要一种能够抵抗这些攻击的鲁棒Deepfake检测器。
核心思路:本文的核心思路是通过红队训练和测试时防御来提高检测器的鲁棒性。红队训练模拟了攻击者的行为,使检测器能够学习识别各种对抗取证操作。测试时防御则通过引入随机扰动来进一步增强检测器的泛化能力。
技术框架:该方法采用双流架构。一个流使用预训练的骨干网络提取图像的语义特征,另一个流提取图像的取证残差。这两个流的特征通过一个轻量级的残差适配器进行融合,然后输入到分类器中进行Deepfake检测。此外,该方法还使用一个浅层的特征金字塔网络风格的头部来生成篡改热图,以可视化Deepfake的篡改区域。
关键创新:该方法的主要创新在于结合了红队训练和测试时防御。红队训练使检测器能够学习识别各种对抗取证操作,而测试时防御则通过引入随机扰动来进一步增强检测器的泛化能力。此外,该方法还使用篡改热图来可视化Deepfake的篡改区域,从而提高检测的可解释性。
关键设计:红队训练使用worst-of-K策略,即在每个批次中选择最难的K个对抗取证操作进行训练。测试时防御则通过注入低成本的抖动,如调整大小和裁剪相位变化、轻微的伽马变化和JPEG相位偏移,并聚合预测。篡改热图的训练使用弱监督,即只使用面部框掩码来引导热图集中在面部区域内,而不需要像素级的标注。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在各种攻击下都具有近乎完美的排序性能(AUC接近1),并且实现了低校准误差和最小的拒绝风险。在重加噪攻击下,该方法的性能下降可控,表明其具有良好的鲁棒性。此外,该方法在弱定位任务中也取得了较好的成绩,表明其能够有效地定位Deepfake的篡改区域。
🎯 应用场景
该研究成果可应用于数字媒体内容安全、网络信息安全、身份认证等领域。例如,可以用于检测社交媒体上的Deepfake视频,防止虚假信息的传播;也可以用于保护个人隐私,防止未经授权的图像篡改和伪造。未来,该技术有望在更广泛的场景中发挥作用,例如金融欺诈检测、智能监控等。
📄 摘要(原文)
This work presents an attack-aware deepfake and image-forensics detector designed for robustness, well-calibrated probabilities, and transparent evidence under realistic deployment conditions. The method combines red-team training with randomized test-time defense in a two-stream architecture, where one stream encodes semantic content using a pretrained backbone and the other extracts forensic residuals, fused via a lightweight residual adapter for classification, while a shallow Feature Pyramid Network style head produces tamper heatmaps under weak supervision. Red-team training applies worst-of-K counter-forensics per batch, including JPEG realign and recompress, resampling warps, denoise-to-regrain operations, seam smoothing, small color and gamma shifts, and social-app transcodes, while test-time defense injects low-cost jitters such as resize and crop phase changes, mild gamma variation, and JPEG phase shifts with aggregated predictions. Heatmaps are guided to concentrate within face regions using face-box masks without strict pixel-level annotations. Evaluation on existing benchmarks, including standard deepfake datasets and a surveillance-style split with low light and heavy compression, reports clean and attacked performance, AUC, worst-case accuracy, reliability, abstention quality, and weak-localization scores. Results demonstrate near-perfect ranking across attacks, low calibration error, minimal abstention risk, and controlled degradation under regrain, establishing a modular, data-efficient, and practically deployable baseline for attack-aware detection with calibrated probabilities and actionable heatmaps.