Learning Dynamic Scene Reconstruction with Sinusoidal Geometric Priors
作者: Tian Guo, Hui Yuan, Philip Xu, David Elizondo
分类: cs.CV
发布日期: 2025-12-25
💡 一句话要点
提出SirenPose,结合正弦几何先验学习动态场景重建,提升时空一致性。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱八:物理动画 (Physics-based Animation)
关键词: 动态场景重建 正弦表示网络 几何先验 时空一致性 关键点预测
📋 核心要点
- 现有动态场景重建方法在快速运动和多目标场景中,难以保持运动建模的准确性和时空一致性。
- SirenPose结合正弦表示网络的周期性激活特性与几何先验,在时空维度上约束关键点预测,提升重建质量。
- 通过扩展数据集和引入SirenPose损失函数,模型在时空一致性指标上显著优于现有方法,尤其在复杂场景中。
📝 摘要(中文)
本文提出SirenPose,一种新颖的损失函数,它结合了正弦表示网络的周期性激活特性与源自关键点结构的几何先验,从而提高动态3D场景重建的准确性。现有方法通常难以在快速移动和多目标场景中保持运动建模的准确性和时空一致性。通过引入受物理学启发的约束机制,SirenPose在空间和时间维度上强制执行一致的关键点预测。我们进一步扩展了训练数据集到60万个带注释的实例,以支持鲁棒学习。实验结果表明,与先前的方法相比,使用SirenPose训练的模型在时空一致性指标方面取得了显著的改进,在处理快速运动和复杂场景变化方面表现出卓越的性能。
🔬 方法详解
问题定义:论文旨在解决动态3D场景重建中,现有方法在快速运动和多目标场景下,难以保持运动建模准确性和时空一致性的问题。现有方法的痛点在于缺乏有效的时空约束,导致重建结果在时间和空间上不连贯,尤其是在处理快速运动和复杂场景变化时表现不佳。
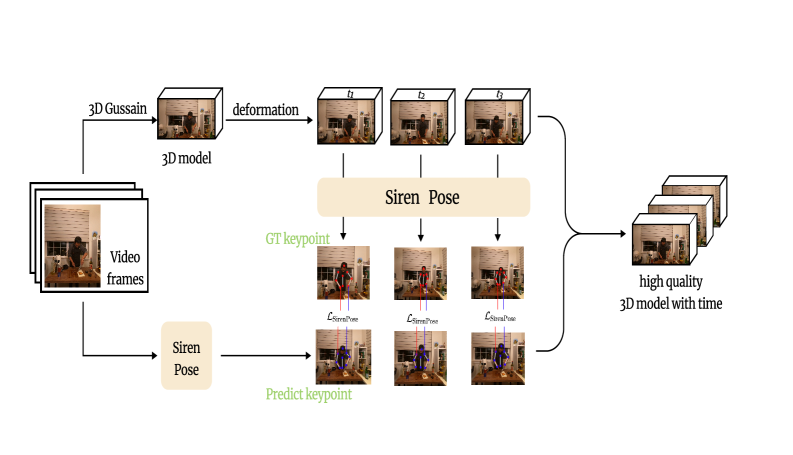
核心思路:论文的核心思路是将正弦表示网络(Siren)的周期性激活特性与从关键点结构导出的几何先验相结合,设计一种新的损失函数SirenPose。通过这种方式,在训练过程中,模型能够学习到更强的时空约束,从而提高重建结果的时空一致性。
技术框架:SirenPose方法的核心在于其损失函数的设计。整体框架包含一个用于预测关键点的网络,该网络以动态场景的图像序列作为输入,输出每个时间步的关键点坐标。SirenPose损失函数则基于这些关键点坐标,结合正弦表示网络的特性和几何先验,对网络的输出进行约束。
关键创新:该方法最重要的创新点在于SirenPose损失函数的设计,它将正弦表示网络的周期性激活特性与几何先验相结合,从而在时空维度上对关键点预测进行约束。这种结合使得模型能够更好地学习到动态场景中的运动模式,从而提高重建结果的时空一致性。与现有方法相比,SirenPose能够更有效地处理快速运动和复杂场景变化。
关键设计:SirenPose损失函数包含多个组成部分,包括基于正弦表示网络的损失项,用于鼓励网络学习到平滑的运动轨迹;以及基于几何先验的损失项,用于约束关键点之间的空间关系。此外,论文还通过扩展训练数据集到60万个带注释的实例,来提高模型的鲁棒性。具体的损失函数权重和网络结构等细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用SirenPose训练的模型在时空一致性指标方面取得了显著的改进。与现有方法相比,SirenPose在处理快速运动和复杂场景变化方面表现出卓越的性能,具体提升幅度在论文中通过量化指标进行了详细展示。扩展到60万实例的训练数据集也显著提升了模型的鲁棒性。
🎯 应用场景
该研究成果可应用于运动捕捉、自动驾驶、机器人导航、增强现实等领域。通过提高动态场景重建的时空一致性,可以为这些应用提供更准确、更稳定的环境感知能力,从而提升系统的整体性能和用户体验。未来,该方法有望进一步扩展到更复杂的场景和任务中。
📄 摘要(原文)
We propose SirenPose, a novel loss function that combines the periodic activation properties of sinusoidal representation networks with geometric priors derived from keypoint structures to improve the accuracy of dynamic 3D scene reconstruction. Existing approaches often struggle to maintain motion modeling accuracy and spatiotemporal consistency in fast moving and multi target scenes. By introducing physics inspired constraint mechanisms, SirenPose enforces coherent keypoint predictions across both spatial and temporal dimensions. We further expand the training dataset to 600,000 annotated instances to support robust learning. Experimental results demonstrate that models trained with SirenPose achieve significant improvements in spatiotemporal consistency metrics compared to prior methods, showing superior performance in handling rapid motion and complex scene changes.