FETAL-GAUGE: A Benchmark for Assessing Vision-Language Models in Fetal Ultrasound
作者: Hussain Alasmawi, Numan Saeed, Mohammad Yaqub
分类: cs.CV
发布日期: 2025-12-25
💡 一句话要点
提出Fetal-Gauge胎儿超声视觉-语言基准,评估并提升VLM在产前诊断中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 胎儿超声 视觉-语言模型 视觉问答 基准数据集 产前诊断
📋 核心要点
- 现有VLM在胎儿超声图像理解方面缺乏标准评估基准,限制了其在该领域的应用和发展。
- Fetal-Gauge基准包含大量胎儿超声图像和问答对,覆盖多种临床任务,用于评估VLM性能。
- 实验表明,现有VLM在Fetal-Gauge上表现不佳,突显了领域自适应和专门训练的必要性。
📝 摘要(中文)
产前超声成像的需求日益增长,导致训练有素的超声医师在全球范围内短缺,这阻碍了基本的胎儿健康监测。深度学习有潜力提高超声医师的效率并支持新从业人员的培训。视觉-语言模型(VLM)在超声图像解释方面尤其有前景,因为它们可以联合处理图像和文本,从而在单个框架内执行多项临床任务。然而,尽管VLM不断扩展,但目前还没有标准化的基准来评估其在胎儿超声成像中的性能。这一差距主要是由于该模态的挑战性、操作者依赖性以及公共数据集的有限可用性。为了弥补这一差距,我们提出了Fetal-Gauge,这是第一个也是最大的视觉问答基准,专门用于评估各种胎儿超声任务中的VLM。我们的基准包括超过42,000张图像和93,000个问答对,涵盖解剖平面识别、解剖结构的可视化定位、胎儿方向评估、临床视图一致性和临床诊断。我们系统地评估了几种最先进的VLM,包括通用模型和医学专用模型,并揭示了巨大的性能差距:性能最佳的模型仅达到55%的准确率,远低于临床要求。我们的分析指出了当前VLM在胎儿超声解释中的关键局限性,强调了对领域自适应架构和专门训练方法的迫切需求。Fetal-Gauge为推进产前护理中的多模态深度学习奠定了坚实的基础,并为解决全球医疗保健可及性挑战提供了一条途径。我们的基准将在论文被接受后公开发布。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型(VLM)在胎儿超声图像理解领域缺乏标准化评估基准的问题。现有方法,即通用VLM和医学专用VLM,直接应用于胎儿超声图像时,由于数据模态的特殊性(噪声大、操作者依赖性强)以及缺乏针对性训练,性能远低于临床需求,阻碍了VLM在该领域的应用。
核心思路:论文的核心思路是构建一个大规模、高质量的胎儿超声视觉问答基准(Fetal-Gauge),用于系统性地评估现有VLM在不同胎儿超声任务上的性能。通过该基准,可以发现现有VLM的局限性,并促进领域自适应VLM的开发。
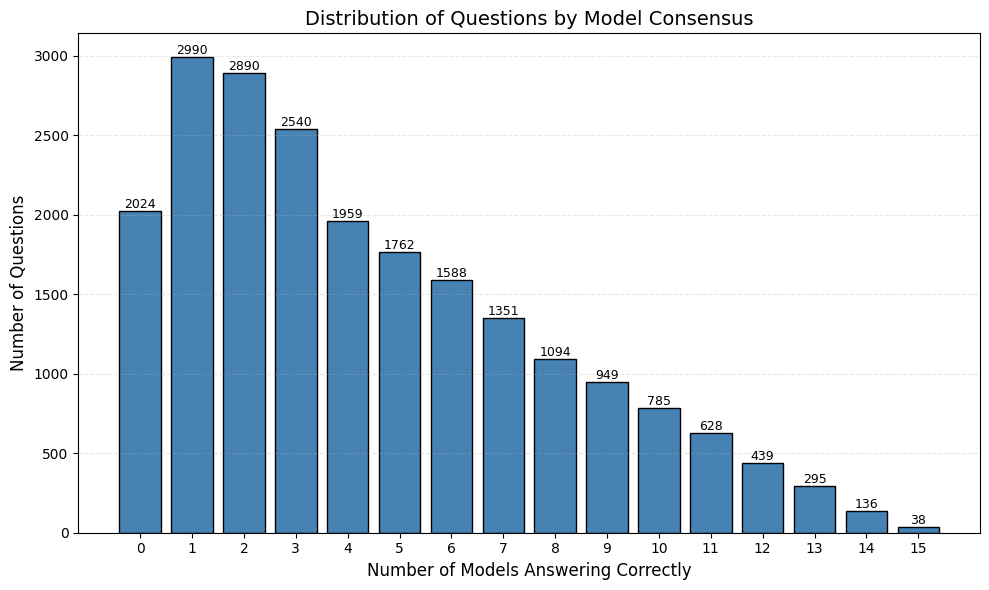
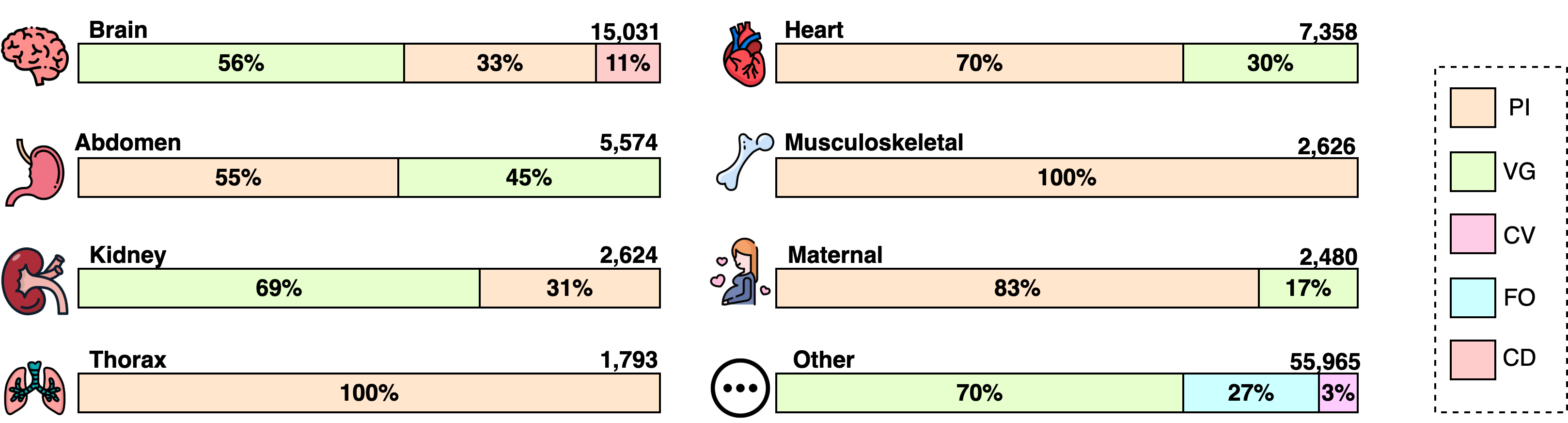
技术框架:Fetal-Gauge基准包含超过42,000张胎儿超声图像和93,000个问答对,涵盖以下五个主要任务:1) 解剖平面识别;2) 解剖结构的可视化定位(Visual Grounding);3) 胎儿方向评估;4) 临床视图一致性检查;5) 临床诊断。该基准提供了一个统一的平台,用于评估VLM在这些任务上的表现。
关键创新:该论文的关键创新在于构建了第一个专门针对胎儿超声图像的视觉问答基准。与现有通用或医学图像基准相比,Fetal-Gauge更关注胎儿超声图像的特殊性,并涵盖了该领域的核心临床任务。这使得Fetal-Gauge能够更准确地评估VLM在胎儿超声图像理解方面的能力。
关键设计:Fetal-Gauge的数据收集和标注过程经过精心设计,以保证数据的质量和多样性。问答对的设计考虑了不同任务的需求,例如,解剖结构的可视化定位任务需要模型能够指出图像中特定结构的位置。此外,论文还对现有VLM进行了系统性的评估,并分析了其在不同任务上的表现,为未来的研究提供了参考。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是最先进的VLM在Fetal-Gauge基准上的准确率仅为55%,远低于临床要求。这突显了现有VLM在胎儿超声图像理解方面的局限性,并强调了开发领域自适应VLM的必要性。该基准的发布为未来的研究提供了重要的评估工具。
🎯 应用场景
该研究成果可应用于辅助超声医师进行胎儿健康监测,提高诊断效率和准确性,尤其是在缺乏专业人员的地区。Fetal-Gauge基准的发布将促进多模态深度学习在产前护理中的发展,最终提升全球医疗保健的可及性。
📄 摘要(原文)
The growing demand for prenatal ultrasound imaging has intensified a global shortage of trained sonographers, creating barriers to essential fetal health monitoring. Deep learning has the potential to enhance sonographers' efficiency and support the training of new practitioners. Vision-Language Models (VLMs) are particularly promising for ultrasound interpretation, as they can jointly process images and text to perform multiple clinical tasks within a single framework. However, despite the expansion of VLMs, no standardized benchmark exists to evaluate their performance in fetal ultrasound imaging. This gap is primarily due to the modality's challenging nature, operator dependency, and the limited public availability of datasets. To address this gap, we present Fetal-Gauge, the first and largest visual question answering benchmark specifically designed to evaluate VLMs across various fetal ultrasound tasks. Our benchmark comprises over 42,000 images and 93,000 question-answer pairs, spanning anatomical plane identification, visual grounding of anatomical structures, fetal orientation assessment, clinical view conformity, and clinical diagnosis. We systematically evaluate several state-of-the-art VLMs, including general-purpose and medical-specific models, and reveal a substantial performance gap: the best-performing model achieves only 55\% accuracy, far below clinical requirements. Our analysis identifies critical limitations of current VLMs in fetal ultrasound interpretation, highlighting the urgent need for domain-adapted architectures and specialized training approaches. Fetal-Gauge establishes a rigorous foundation for advancing multimodal deep learning in prenatal care and provides a pathway toward addressing global healthcare accessibility challenges. Our benchmark will be publicly available once the paper gets accepted.