Scene-VLM: Multimodal Video Scene Segmentation via Vision-Language Models
作者: Nimrod Berman, Adam Botach, Emanuel Ben-Baruch, Shunit Haviv Hakimi, Asaf Gendler, Ilan Naiman, Erez Yosef, Igor Kviatkovsky
分类: cs.CV
发布日期: 2025-12-25
💡 一句话要点
提出Scene-VLM,利用视觉-语言模型进行多模态视频场景分割,显著提升长视频理解能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频场景分割 视觉-语言模型 多模态融合 长视频理解 序列预测
📋 核心要点
- 现有视频场景分割方法主要依赖视觉信息,忽略了文本等其他模态信息,且缺乏对视频叙事的理解。
- Scene-VLM利用视觉-语言模型,融合视频帧、文本转录等多模态信息,进行序列化的场景分割预测。
- 实验表明,Scene-VLM在MovieNet等数据集上取得了显著的性能提升,超越了现有最佳方法。
📝 摘要(中文)
本文提出Scene-VLM,一种用于视频场景分割的微调视觉-语言模型(VLM)框架。现有基于编码器的方法受限于视觉中心偏差,孤立地分类每个镜头而忽略了序列依赖性,并且缺乏叙事理解和可解释性。Scene-VLM联合处理视觉和文本线索,包括帧、转录和可选元数据,以实现跨连续镜头的多模态推理。该模型以镜头间的因果依赖关系顺序生成预测,并引入上下文聚焦窗口机制,以确保每个镜头级别决策的充分时间上下文。此外,我们提出了一种从VLM的token级别logits中提取置信度分数的方法,从而实现可控的精度-召回权衡。我们还证明了我们的模型可以通过最小的目标监督来生成连贯的自然语言理由,解释其边界决策。我们的方法在标准场景分割基准测试中实现了最先进的性能。例如,在MovieNet上,Scene-VLM比之前的领先方法产生了+6 AP和+13.7 F1的显著改进。
🔬 方法详解
问题定义:视频场景分割旨在将长视频分割成语义连贯的片段。现有方法主要依赖于视觉特征,忽略了文本信息,并且通常独立处理每个镜头,无法有效利用镜头间的时序依赖关系。此外,这些方法缺乏可解释性,难以理解其分割决策的原因。
核心思路:Scene-VLM的核心思路是利用预训练的视觉-语言模型(VLM)的强大能力,将视频帧和文本转录等多模态信息融合在一起,进行序列化的场景分割。通过VLM,模型可以更好地理解视频的叙事结构和语义信息,从而做出更准确的分割决策。
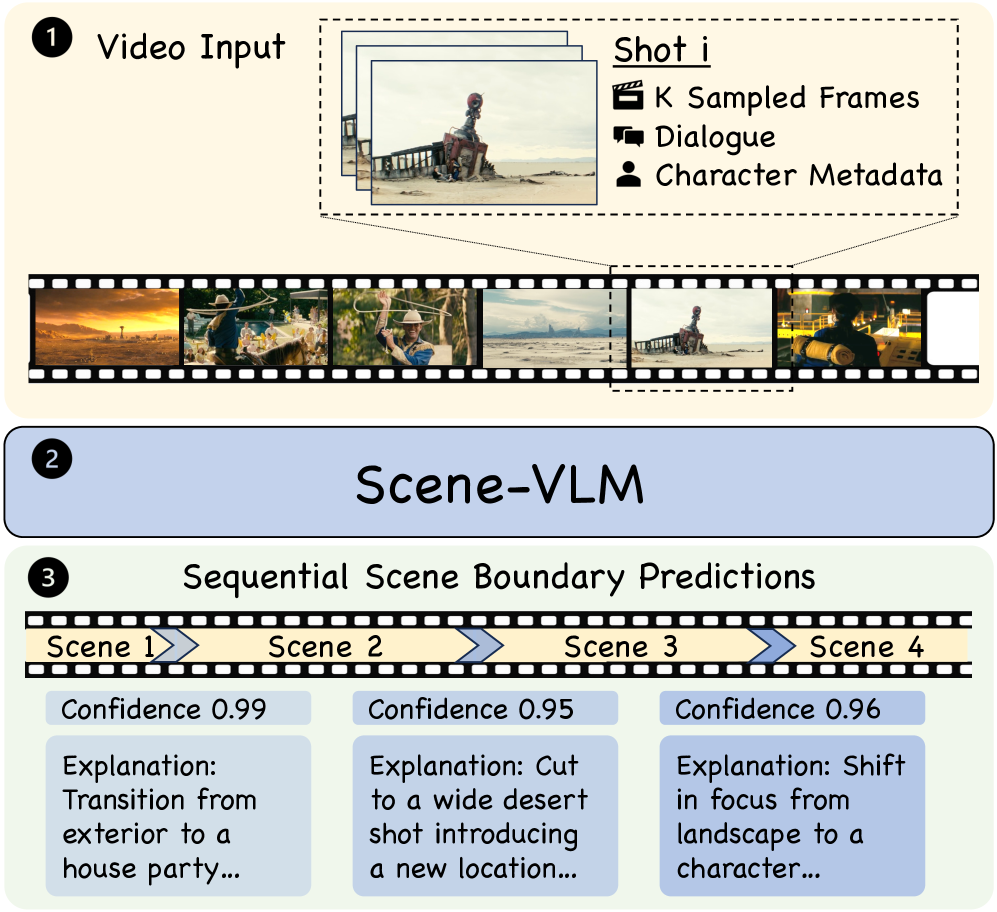
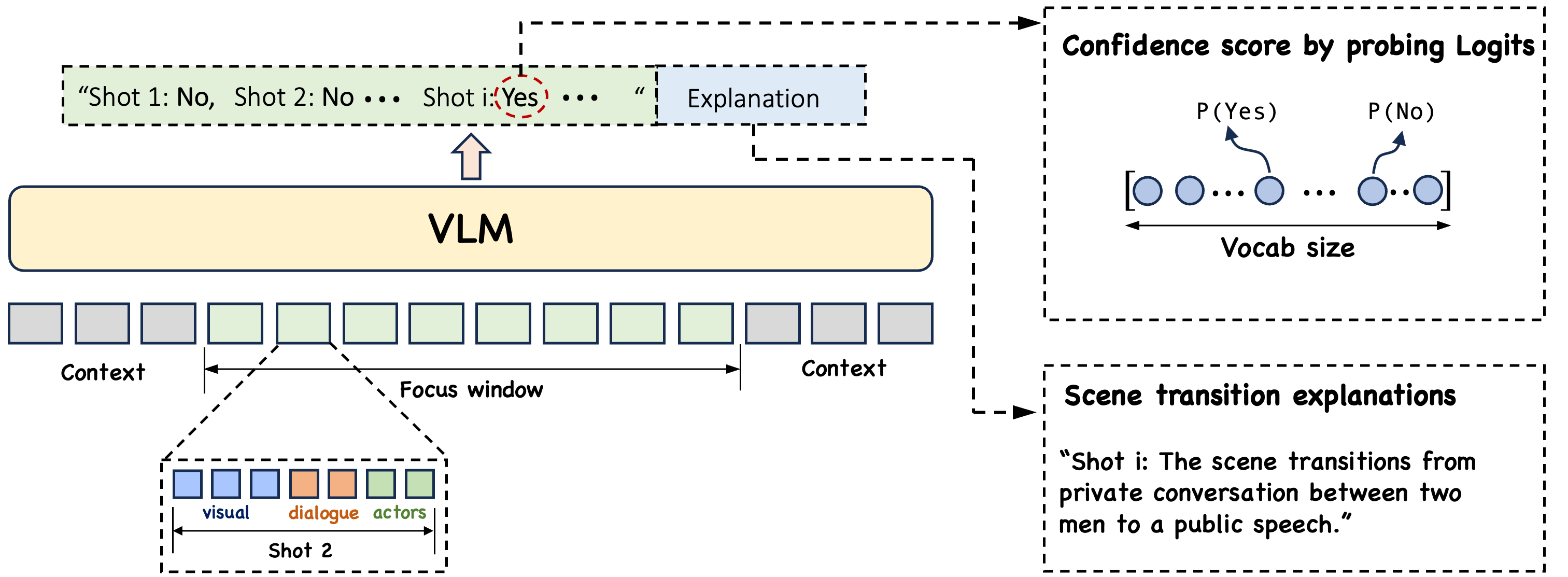
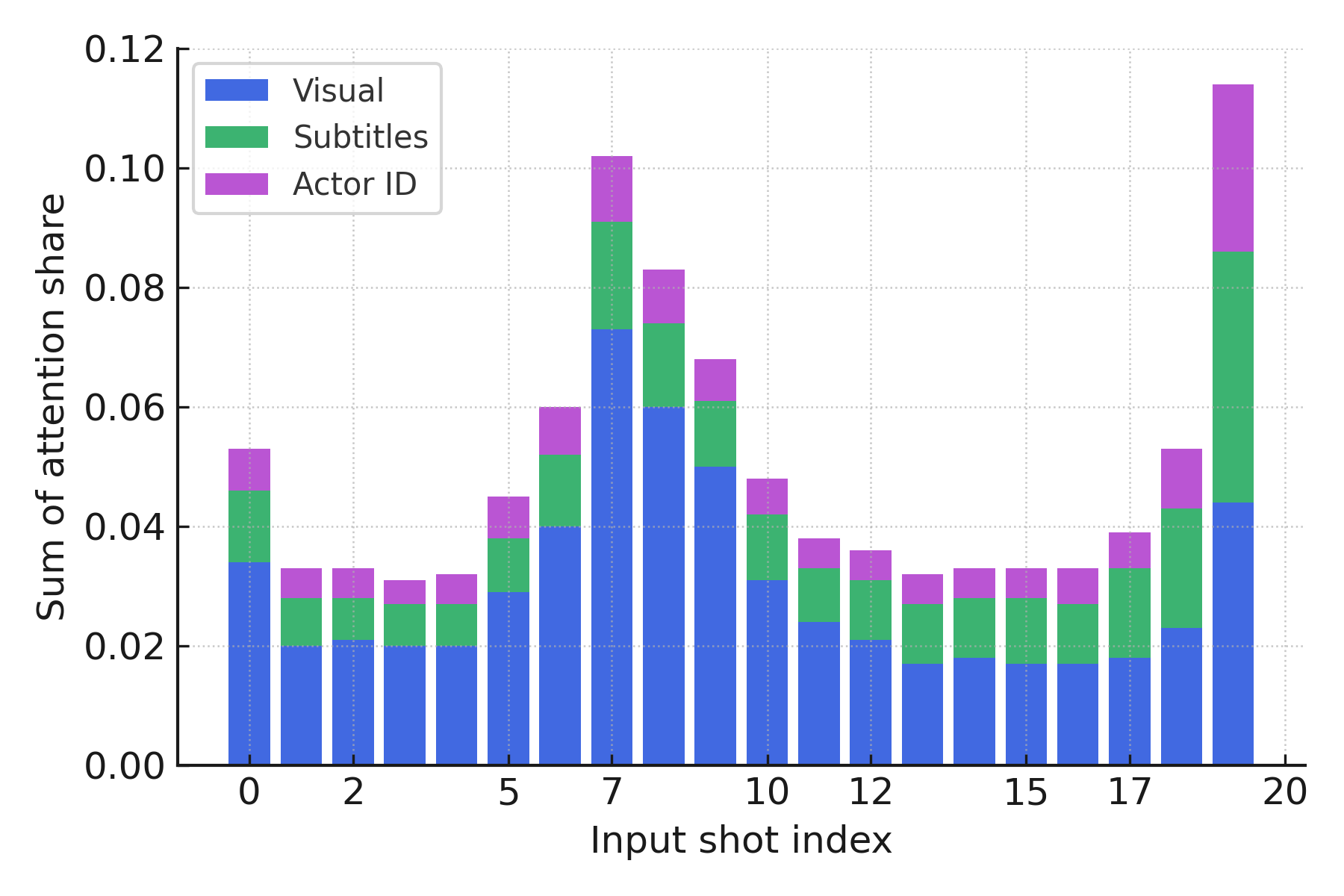
技术框架:Scene-VLM的整体框架包括以下几个主要模块:1) 视觉特征提取模块,用于提取视频帧的视觉特征;2) 文本特征提取模块,用于提取视频转录的文本特征;3) VLM融合模块,将视觉和文本特征输入到VLM中进行融合;4) 序列预测模块,利用VLM的输出进行序列化的场景分割预测,并引入上下文聚焦窗口机制,确保每个镜头级别决策的充分时间上下文。
关键创新:Scene-VLM的关键创新在于:1) 首次将VLM应用于视频场景分割任务;2) 提出了上下文聚焦窗口机制,有效利用了镜头间的时序依赖关系;3) 提出了一种从VLM的token级别logits中提取置信度分数的方法,从而实现可控的精度-召回权衡;4) 能够生成自然语言理由,解释其分割决策的原因,提高了模型的可解释性。
关键设计:Scene-VLM使用了预训练的VLM模型,并对其进行了微调。在训练过程中,使用了交叉熵损失函数来优化模型的分割性能。上下文聚焦窗口的大小是一个重要的超参数,需要根据具体的视频内容进行调整。此外,置信度分数的提取方法也需要仔细设计,以确保其能够准确反映模型对分割决策的置信程度。
🖼️ 关键图片
📊 实验亮点
Scene-VLM在MovieNet数据集上取得了显著的性能提升,AP指标提升了+6,F1指标提升了+13.7,超过了之前的最佳方法。实验结果表明,Scene-VLM能够有效利用视觉和文本信息,进行准确的视频场景分割。
🎯 应用场景
Scene-VLM可应用于视频内容分析、视频编辑、视频检索等领域。例如,可以自动将电影分割成不同的场景,方便用户快速浏览和查找感兴趣的内容。此外,该技术还可以用于视频监控,自动检测异常事件的发生。
📄 摘要(原文)
Segmenting long-form videos into semantically coherent scenes is a fundamental task in large-scale video understanding. Existing encoder-based methods are limited by visual-centric biases, classify each shot in isolation without leveraging sequential dependencies, and lack both narrative understanding and explainability. In this paper, we present Scene-VLM, the first fine-tuned vision-language model (VLM) framework for video scene segmentation. Scene-VLM jointly processes visual and textual cues including frames, transcriptions, and optional metadata to enable multimodal reasoning across consecutive shots. The model generates predictions sequentially with causal dependencies among shots and introduces a context-focus window mechanism to ensure sufficient temporal context for each shot-level decision. In addition, we propose a scheme to extract confidence scores from the token-level logits of the VLM, enabling controllable precision-recall trade-offs that were previously limited to encoder-based methods. Furthermore, we demonstrate that our model can be aligned to generate coherent natural-language rationales for its boundary decisions through minimal targeted supervision. Our approach achieves state-of-the-art performance on standard scene segmentation benchmarks. On MovieNet, for example, Scene-VLM yields significant improvements of +6 AP and +13.7 F1 over the previous leading method.