BertsWin: Resolving Topological Sparsity in 3D Masked Autoencoders via Component-Balanced Structural Optimization
作者: Evgeny Alves Limarenko, Anastasiia Studenikina
分类: cs.CV, cs.LG, eess.IV
发布日期: 2025-12-25
备注: Code available at https://github.com/AlevLab-dev/BertsWinMAE and https://github.com/AlevLab-dev/GCond. Zenodo repository (DOI: 10.5281/zenodo.17916932) contains source images, training logs, trained models, and code
💡 一句话要点
BertsWin:通过组件平衡结构优化解决3D掩码自编码器中的拓扑稀疏性问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 3D医学图像 自监督学习 掩码自编码器 Vision Transformer Swin Transformer 空间拓扑 重建 分割
📋 核心要点
- 传统3D掩码自编码器难以捕捉三维空间关系,尤其是在高比例掩码下,导致拓扑结构信息丢失。
- BertsWin结合BERT风格掩码和Swin Transformer窗口,保留完整3D tokens网格,增强空间上下文学习。
- 实验表明,BertsWin加速语义收敛5.8倍,结合GradientConductor优化器,训练epoch减少15倍。
📝 摘要(中文)
自监督学习(SSL)和Vision Transformers (ViTs)在2D医学图像领域展现出良好效果,但将其应用于3D体数据图像面临诸多挑战。标准的掩码自编码器(MAE)作为2D领域的先进解决方案,难以捕捉三维空间关系,尤其是在预训练期间丢弃75%的tokens时。我们提出了BertsWin,一种混合架构,结合了BERT风格的token掩码和Swin Transformer窗口,以增强3D自监督学习预训练中的空间上下文学习。与仅处理可见区域的经典MAE不同,BertsWin引入了完整的3D tokens网格(掩码和可见),保留了空间拓扑结构。为了平滑ViT的二次复杂度,使用了单层局部Swin窗口。我们引入了一种结构优先级损失函数,并评估了颞下颌关节锥形束计算机断层扫描的结果。后续评估包括3D CT扫描上的TMJ分割。结果表明,BertsWin架构通过保持完整的三维空间拓扑结构,与标准ViT-MAE基线相比,语义收敛速度提高了5.8倍。此外,当与我们提出的GradientConductor优化器结合使用时,完整的BertsWin框架实现了训练epoch减少15倍(44 vs 660),即可达到最先进的重建保真度。分析表明,BertsWin实现了这种加速,而没有通常与密集体积处理相关的计算代价。在规范输入分辨率下,该架构保持了与稀疏ViT基线相当的理论FLOP,从而由于更快的收敛速度而显著减少了总计算资源。
🔬 方法详解
问题定义:论文旨在解决3D掩码自编码器在高比例掩码下,难以有效学习三维空间关系,导致拓扑结构信息丢失的问题。现有方法如标准MAE在处理3D数据时,由于大量tokens被掩码,无法充分捕捉空间上下文,影响重建和下游任务的性能。
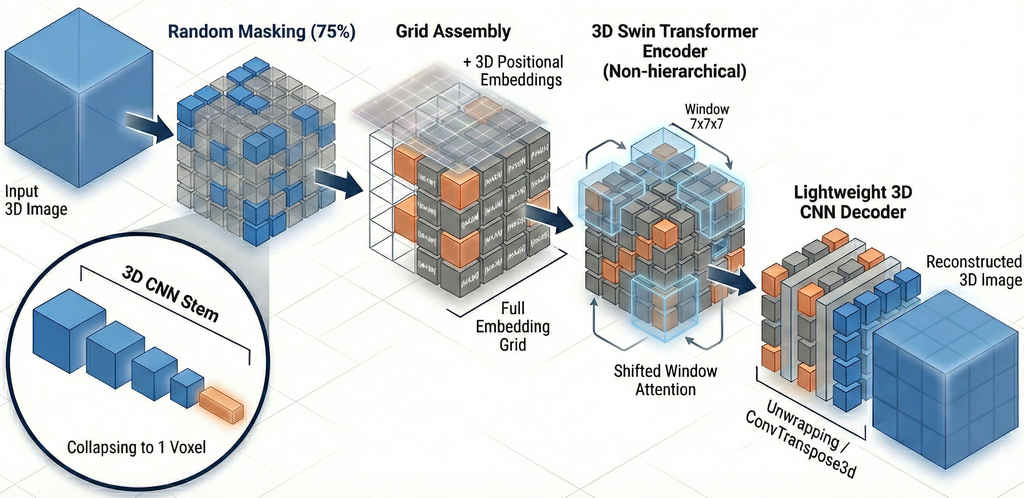
核心思路:BertsWin的核心思路是通过引入完整的3D tokens网格(包括掩码和可见tokens),并结合Swin Transformer窗口,来保留和增强空间拓扑结构的学习。通过BERT风格的掩码策略,模型可以学习到被掩码区域的信息,从而更好地理解整体结构。
技术框架:BertsWin是一个混合架构,主要包含以下几个部分:1) 输入3D体数据;2) BERT风格的token掩码,随机掩码部分tokens;3) Swin Transformer编码器,使用局部窗口处理tokens,降低计算复杂度;4) 解码器,重建被掩码的tokens;5) 结构优先级损失函数,优化重建过程。整个流程旨在通过自监督学习,使模型学习到3D数据的空间结构信息。
关键创新:BertsWin的关键创新在于:1) 引入完整的3D tokens网格,保留空间拓扑结构;2) 结合BERT风格掩码和Swin Transformer窗口,增强空间上下文学习;3) 提出结构优先级损失函数,优化重建过程。与传统MAE相比,BertsWin能够更好地捕捉3D空间关系,提高重建和下游任务的性能。
关键设计:BertsWin的关键设计包括:1) 使用单层局部Swin窗口,降低计算复杂度;2) 设计结构优先级损失函数,鼓励模型重建重要的结构信息;3) 采用GradientConductor优化器,加速训练过程。具体的参数设置和网络结构细节需要在论文中查找。
🖼️ 关键图片
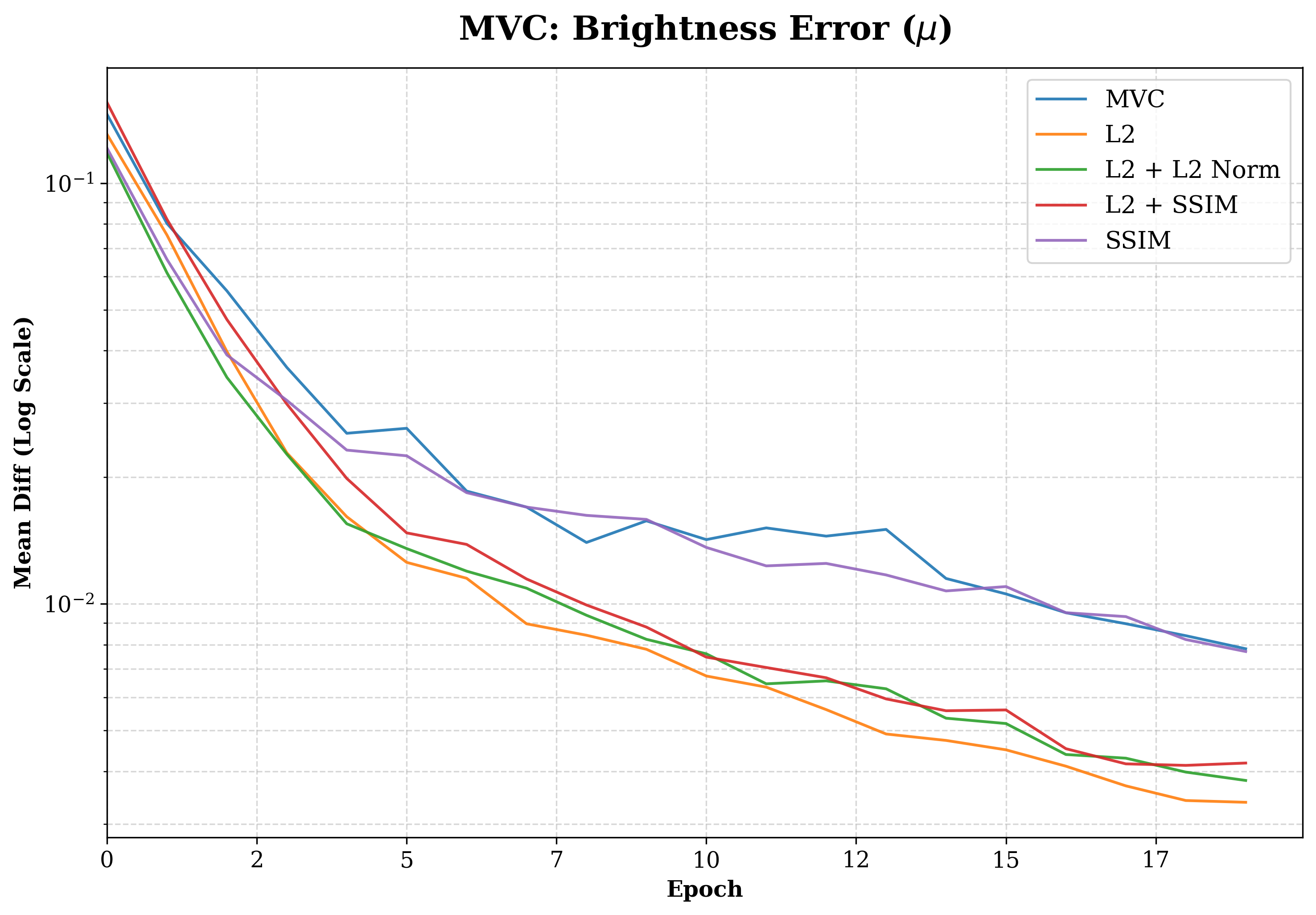
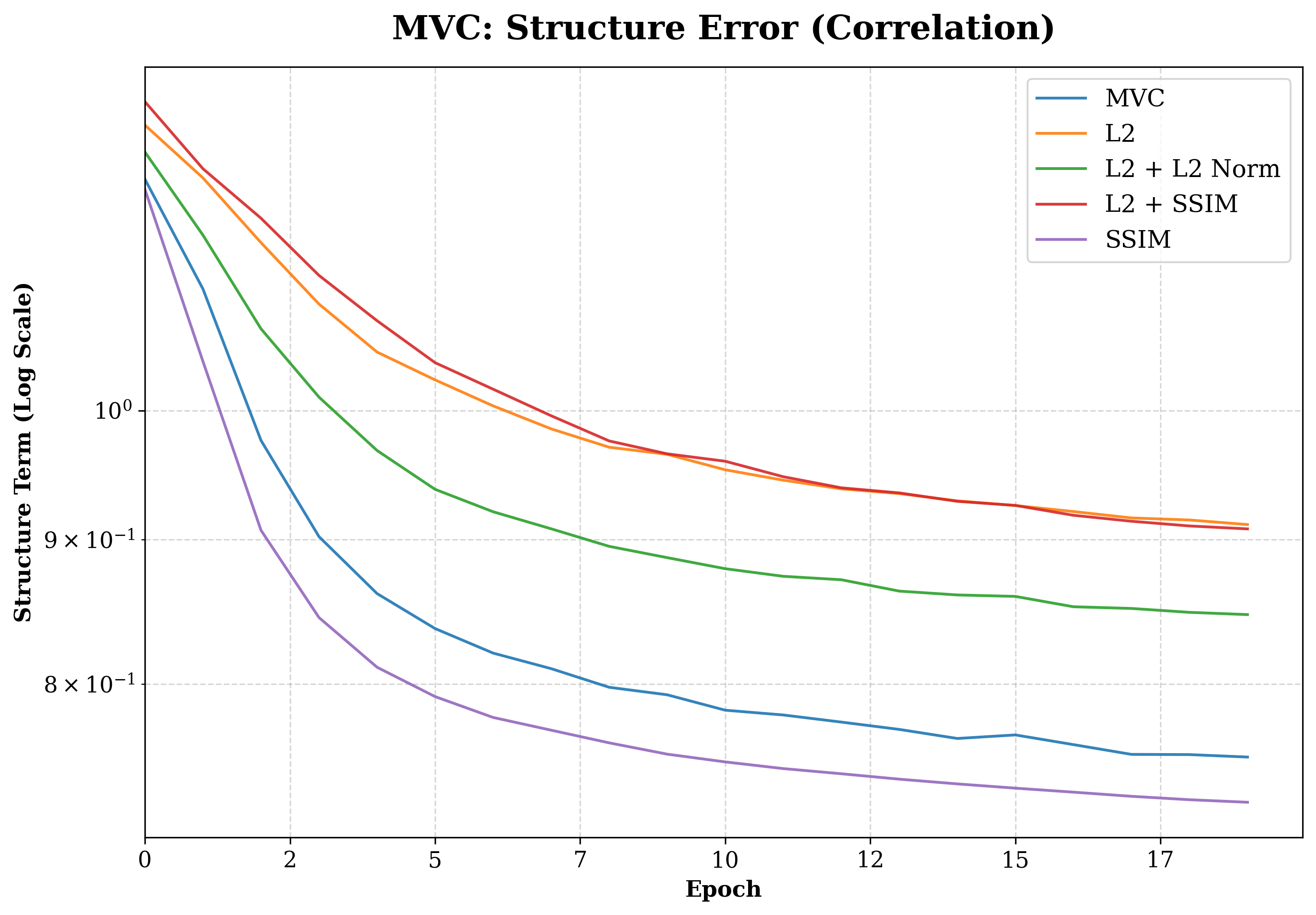
📊 实验亮点
BertsWin在颞下颌关节锥形束计算机断层扫描的TMJ分割任务中表现出色。与标准ViT-MAE基线相比,语义收敛速度提高了5.8倍。结合GradientConductor优化器后,达到最先进重建保真度所需的训练epoch减少了15倍(44 vs 660)。该架构在保持与稀疏ViT基线相当的理论FLOP的同时,显著减少了总计算资源。
🎯 应用场景
BertsWin在医学图像分析领域具有广泛的应用前景,例如3D医学图像重建、分割和配准。它可以用于辅助医生进行疾病诊断和治疗计划制定,提高医疗效率和准确性。此外,该方法还可以应用于其他3D数据分析领域,如遥感图像处理和计算机辅助设计。
📄 摘要(原文)
The application of self-supervised learning (SSL) and Vision Transformers (ViTs) approaches demonstrates promising results in the field of 2D medical imaging, but the use of these methods on 3D volumetric images is fraught with difficulties. Standard Masked Autoencoders (MAE), which are state-of-the-art solution for 2D, have a hard time capturing three-dimensional spatial relationships, especially when 75% of tokens are discarded during pre-training. We propose BertsWin, a hybrid architecture combining full BERT-style token masking using Swin Transformer windows, to enhance spatial context learning in 3D during SSL pre-training. Unlike the classic MAE, which processes only visible areas, BertsWin introduces a complete 3D grid of tokens (masked and visible), preserving the spatial topology. And to smooth out the quadratic complexity of ViT, single-level local Swin windows are used. We introduce a structural priority loss function and evaluate the results of cone beam computed tomography of the temporomandibular joints. The subsequent assessment includes TMJ segmentation on 3D CT scans. We demonstrate that the BertsWin architecture, by maintaining a complete three-dimensional spatial topology, inherently accelerates semantic convergence by a factor of 5.8x compared to standard ViT-MAE baselines. Furthermore, when coupled with our proposed GradientConductor optimizer, the full BertsWin framework achieves a 15-fold reduction in training epochs (44 vs 660) required to reach state-of-the-art reconstruction fidelity. Analysis reveals that BertsWin achieves this acceleration without the computational penalty typically associated with dense volumetric processing. At canonical input resolutions, the architecture maintains theoretical FLOP parity with sparse ViT baselines, resulting in a significant net reduction in total computational resources due to faster convergence.