AstraNav-World: World Model for Foresight Control and Consistency
作者: Junjun Hu, Jintao Chen, Haochen Bai, Minghua Luo, Shichao Xie, Ziyi Chen, Fei Liu, Zedong Chu, Xinda Xue, Botao Ren, Xiaolong Wu, Mu Xu, Shanghang Zhang
分类: cs.CV
发布日期: 2025-12-25
💡 一句话要点
AstraNav-World:用于预见性控制和一致性的世界模型,提升具身导航性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 具身导航 世界模型 视频生成 扩散模型 视觉-语言策略 预见性控制 零样本学习
📋 核心要点
- 现有具身导航方法难以准确预测开放动态环境中世界的演变和动作的展开,导致累积误差。
- AstraNav-World通过统一的概率框架,将基于扩散的视频生成器与视觉-语言策略相结合,同步预测未来视觉状态和动作序列。
- 实验表明,AstraNav-World在具身导航任务中提高了轨迹精度和成功率,并展现了卓越的零样本真实世界适应能力。
📝 摘要(中文)
本文提出AstraNav-World,一个端到端的世界模型,它在一个统一的概率框架内联合推理未来的视觉状态和动作序列。该框架集成了基于扩散的视频生成器和视觉-语言策略,实现了同步展开,其中预测的场景和计划的动作同时更新。训练优化两个互补的目标:生成动作条件下的多步视觉预测,以及推导以这些预测视觉为条件的轨迹。这种双向约束使视觉预测可执行,并使决策基于物理上一致的、与任务相关的未来,从而减轻了解耦的“envision-then-plan”流程中常见的累积误差。在各种具身导航基准测试中进行的实验表明,轨迹精度更高,成功率更高。消融实验证实了紧密的视觉-动作耦合和统一训练的必要性,移除任何一个分支都会降低预测质量和策略可靠性。在真实世界测试中,AstraNav-World展示了卓越的零样本能力,无需任何真实世界微调即可适应以前未见过的场景。这些结果表明,AstraNav-World捕获了可转移的空间理解和与规划相关的导航动态,而不仅仅是过度拟合特定于模拟的数据分布。总而言之,通过在单个生成模型中统一预见性视觉和控制,我们更接近于可靠、可解释和通用的具身智能体,这些智能体可以在开放式真实世界环境中稳健地运行。
🔬 方法详解
问题定义:论文旨在解决具身导航任务中,智能体在开放、动态环境中进行导航时,由于对未来环境变化和自身动作序列预测不准确而导致的导航性能下降问题。现有方法通常采用“envision-then-plan”的解耦流程,即先预测未来视觉信息,再基于预测进行规划,这种方式容易产生累积误差,导致导航失败。
核心思路:论文的核心思路是将视觉预测和动作规划统一到一个端到端的框架中,通过联合推理未来的视觉状态和动作序列,实现更准确的预见性控制。这种紧密的视觉-动作耦合能够使视觉预测更具可执行性,并使决策基于物理上一致的未来,从而减轻累积误差。
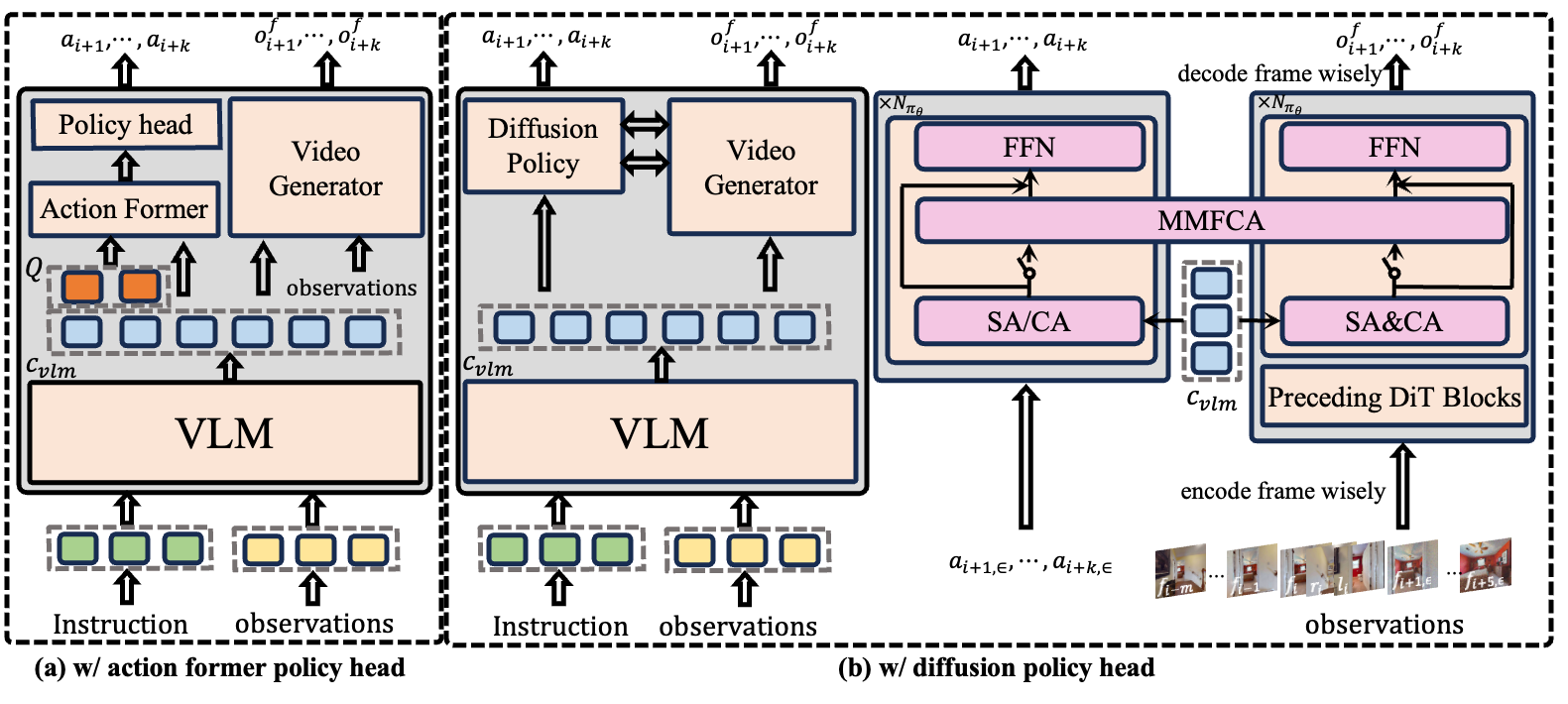
技术框架:AstraNav-World框架包含两个主要组成部分:基于扩散的视频生成器和视觉-语言策略。视频生成器负责预测未来视觉状态,视觉-语言策略负责根据预测的视觉状态规划动作序列。这两个模块在一个统一的概率框架下进行联合训练,实现同步展开,即预测的场景和计划的动作同时更新。整体流程可以概括为:输入当前环境状态,视频生成器预测未来视觉状态,视觉-语言策略根据预测的视觉状态规划动作,然后将动作反馈给视频生成器,用于生成下一步的视觉状态,如此循环往复。
关键创新:论文最重要的技术创新点在于将视觉预测和动作规划统一到一个端到端的生成模型中,通过双向约束(生成动作条件下的多步视觉预测,以及推导以预测视觉为条件的轨迹)实现紧密的视觉-动作耦合。这种统一的框架能够有效减轻累积误差,提高导航性能。与现有方法的本质区别在于,AstraNav-World不是先独立地预测未来视觉信息,然后再进行规划,而是将这两个过程紧密地结合在一起,相互影响,相互促进。
关键设计:论文的关键设计包括:1) 使用基于扩散模型的视频生成器,能够生成更逼真、更多样化的未来视觉状态;2) 使用视觉-语言策略,能够将视觉信息和语言指令结合起来,进行更有效的动作规划;3) 设计了双向约束的损失函数,同时优化视觉预测和动作规划的性能;4) 采用统一的训练方式,使得视频生成器和视觉-语言策略能够相互学习,共同提高导航性能。
🖼️ 关键图片

📊 实验亮点
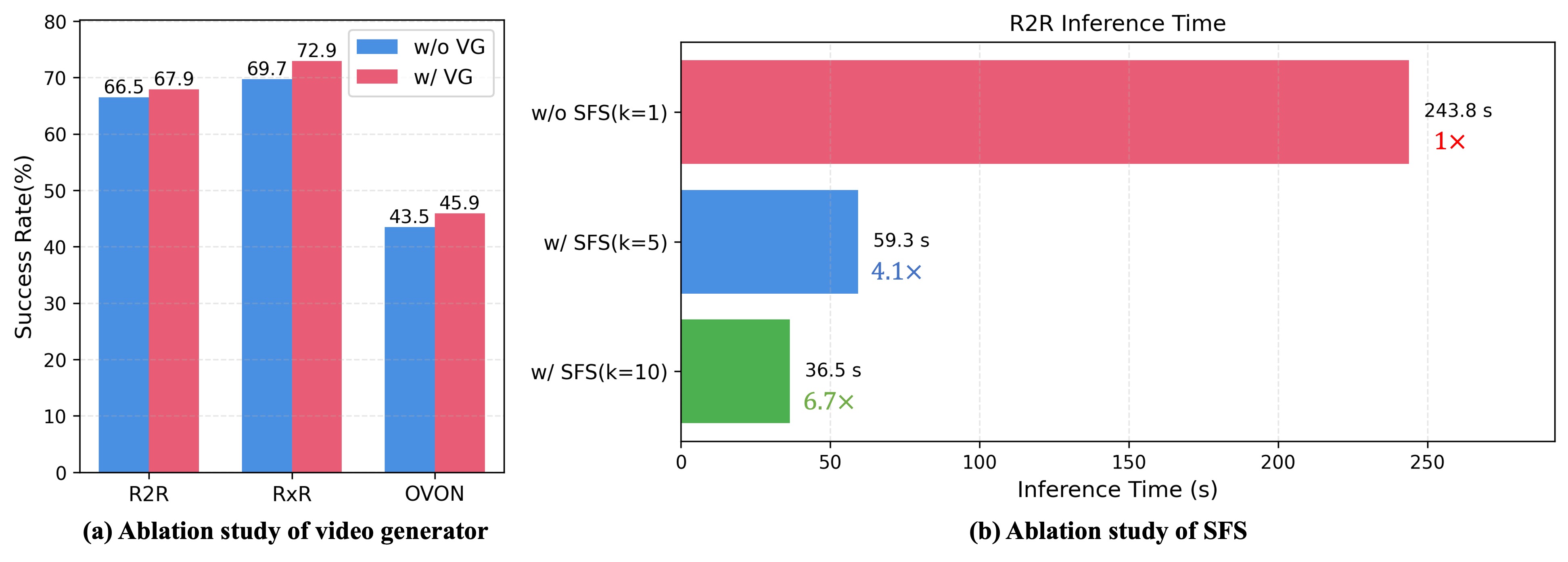
实验结果表明,AstraNav-World在多个具身导航基准测试中取得了显著的性能提升,轨迹精度和成功率均高于现有方法。更重要的是,AstraNav-World在真实世界测试中展现了卓越的零样本能力,无需任何真实世界微调即可适应以前未见过的场景,表明其具有良好的泛化能力和可移植性。
🎯 应用场景
AstraNav-World具有广泛的应用前景,例如:家庭服务机器人、自动驾驶、虚拟现实/增强现实、游戏AI等。该研究的实际价值在于提高了具身智能体在复杂、动态环境中进行导航的可靠性和效率。未来,该技术有望应用于更广泛的机器人领域,例如:搜索救援、灾难应对、太空探索等。
📄 摘要(原文)
Embodied navigation in open, dynamic environments demands accurate foresight of how the world will evolve and how actions will unfold over time. We propose AstraNav-World, an end-to-end world model that jointly reasons about future visual states and action sequences within a unified probabilistic framework. Our framework integrates a diffusion-based video generator with a vision-language policy, enabling synchronized rollouts where predicted scenes and planned actions are updated simultaneously. Training optimizes two complementary objectives: generating action-conditioned multi-step visual predictions and deriving trajectories conditioned on those predicted visuals. This bidirectional constraint makes visual predictions executable and keeps decisions grounded in physically consistent, task-relevant futures, mitigating cumulative errors common in decoupled "envision-then-plan" pipelines. Experiments across diverse embodied navigation benchmarks show improved trajectory accuracy and higher success rates. Ablations confirm the necessity of tight vision-action coupling and unified training, with either branch removal degrading both prediction quality and policy reliability. In real-world testing, AstraNav-World demonstrated exceptional zero-shot capabilities, adapting to previously unseen scenarios without any real-world fine-tuning. These results suggest that AstraNav-World captures transferable spatial understanding and planning-relevant navigation dynamics, rather than merely overfitting to simulation-specific data distribution. Overall, by unifying foresight vision and control within a single generative model, we move closer to reliable, interpretable, and general-purpose embodied agents that operate robustly in open-ended real-world settings.