Analyzing the Mechanism of Attention Collapse in VGGT from a Dynamics Perspective
作者: Huan Li, Longjun Luo, Yuling Shi, Xiaodong Gu
分类: cs.CV
发布日期: 2025-12-25
备注: 8 pages, 4 figures
💡 一句话要点
从动态系统角度分析VGGT中Attention崩塌机制,揭示其根本原因。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D重建 Transformer 注意力机制 动态系统 扩散过程
📋 核心要点
- VGGT在3D重建中表现优异,但长序列输入时全局自注意力机制会发生崩塌,导致性能下降。
- 论文将全局注意力迭代视为退化的扩散过程,从动态系统角度解释了Attention崩塌的数学机理。
- 理论分析与实验结果高度吻合,解释了token合并策略的有效性,并为未来3D视觉Transformer设计提供了指导。
📝 摘要(中文)
视觉几何基础Transformer (VGGT) 在前馈3D重建方面表现出色,但其全局自注意力层在输入序列超过几百帧时会发生严重的崩塌现象:注意力矩阵迅速变为近秩一矩阵,token几何退化为几乎一维的子空间,重建误差超线性累积。本文通过将全局注意力迭代视为退化的扩散过程,对崩塌现象建立了严格的数学解释。证明了在VGGT中,token特征流以O(1/L)的速度收敛到狄拉克型测度,其中L是层索引,从而产生了一个闭式平均场偏微分方程,可以精确预测经验观察到的秩分布。该理论定量地匹配了注意力热图的演变以及相关工作中报告的一系列实验结果,并解释了其token合并补救措施(定期删除冗余token)如何减缓有效扩散系数,从而在无需额外训练的情况下延迟崩塌。我们相信该分析为解释未来可扩展的3D视觉Transformer提供了一个原则性视角,并强调了其在多模态泛化方面的潜力。
🔬 方法详解
问题定义:VGGT在处理长序列3D重建任务时,其全局自注意力机制会发生崩塌,具体表现为注意力矩阵秩降低,token特征退化到低维子空间,最终导致重建误差急剧增加。现有方法缺乏对这种崩塌现象的深入理解,难以有效解决该问题。
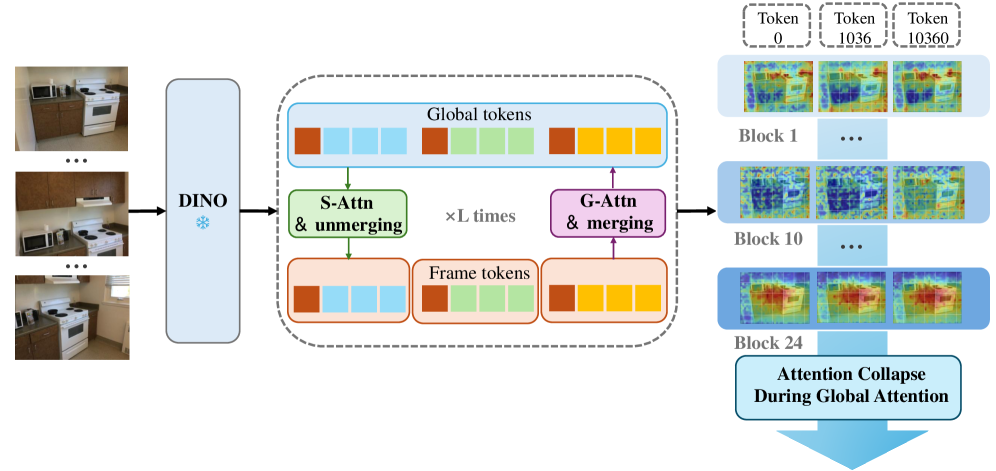
核心思路:论文将VGGT的全局自注意力迭代过程建模为一种退化的扩散过程。通过这种建模,可以将注意力机制的演化与偏微分方程联系起来,从而利用动态系统的理论工具来分析其行为。核心在于揭示token特征在经过多层Transformer后,会逐渐聚集到少数几个“主导”token上,导致信息丢失和性能下降。
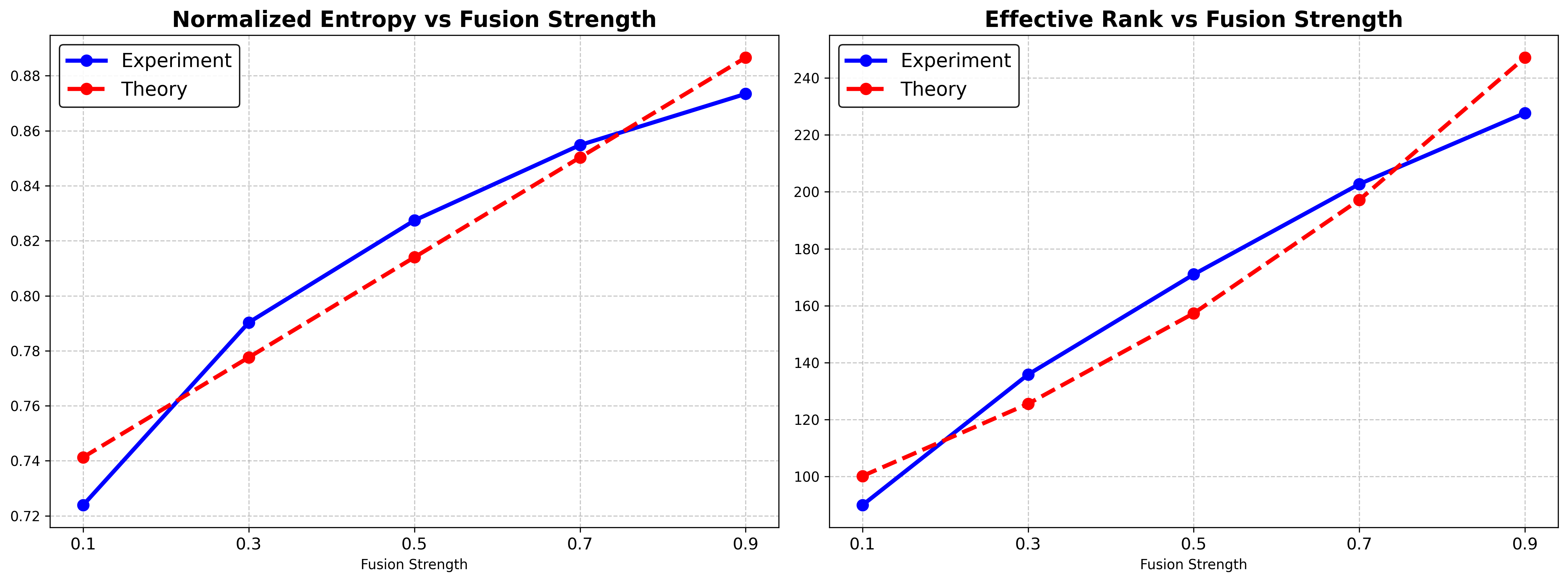
技术框架:论文的核心技术框架包括:1) 将全局注意力迭代建模为离散时间动态系统;2) 推导该动态系统的连续时间近似,得到一个平均场偏微分方程;3) 分析该偏微分方程的解,证明token特征会收敛到狄拉克型测度;4) 将理论分析结果与实验观察到的注意力热图演变进行对比验证。
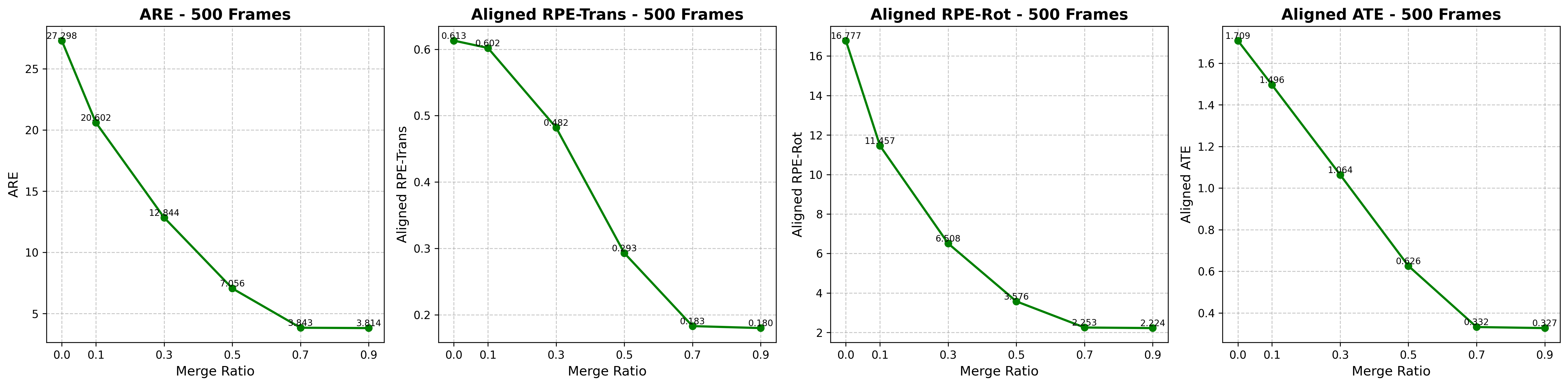
关键创新:论文最重要的创新在于将全局自注意力机制的崩塌现象与退化扩散过程联系起来,并利用动态系统理论对其进行严格的数学分析。这种分析方法为理解和解决Transformer中的注意力崩塌问题提供了一个全新的视角。与现有方法相比,该论文不仅解释了崩塌现象的原因,还提出了token合并策略能够缓解崩塌的理论依据。
关键设计:论文的关键设计包括:1) 使用平均场理论对大规模token特征的演化进行建模;2) 推导闭式解的偏微分方程,精确预测秩分布;3) 通过实验验证理论分析的准确性,并量化token合并策略对扩散系数的影响。没有特别强调特定的参数设置或损失函数,而是侧重于理论分析和验证。
🖼️ 关键图片
📊 实验亮点
论文通过理论分析和实验验证,证明了VGGT中注意力崩塌的根本原因是token特征的退化扩散。理论预测的秩分布与实验观察到的结果高度吻合。此外,论文还解释了token合并策略能够有效缓解崩塌的原因,为未来的模型设计提供了理论依据。
🎯 应用场景
该研究成果可应用于各种基于Transformer的3D视觉任务,例如长序列3D重建、SLAM、以及其他需要处理大量token数据的场景。通过理解和缓解注意力崩塌,可以提升模型的性能和可扩展性,并为多模态Transformer的设计提供指导。
📄 摘要(原文)
Visual Geometry Grounded Transformer (VGGT) delivers state-of-the-art feed-forward 3D reconstruction, yet its global self-attention layer suffers from a drastic collapse phenomenon when the input sequence exceeds a few hundred frames: attention matrices rapidly become near rank-one, token geometry degenerates to an almost one-dimensional subspace, and reconstruction error accumulates super-linearly.In this report,we establish a rigorous mathematical explanation of the collapse by viewing the global-attention iteration as a degenerate diffusion process.We prove that,in VGGT, the token-feature flow converges toward a Dirac-type measure at a $O(1/L)$ rate, where $L$ is the layer index, yielding a closed-form mean-field partial differential equation that precisely predicts the empirically observed rank profile.The theory quantitatively matches the attention-heat-map evolution and a series of experiments outcomes reported in relevant works and explains why its token-merging remedy -- which periodically removes redundant tokens -- slows the effective diffusion coefficient and thereby delays collapse without additional training.We believe the analysis provides a principled lens for interpreting future scalable 3D-vision transformers,and we highlight its potential for multi-modal generalization.