UniPercept: Towards Unified Perceptual-Level Image Understanding across Aesthetics, Quality, Structure, and Texture
作者: Shuo Cao, Jiayang Li, Xiaohui Li, Yuandong Pu, Kaiwen Zhu, Yuanting Gao, Siqi Luo, Yi Xin, Qi Qin, Yu Zhou, Xiangyu Chen, Wenlong Zhang, Bin Fu, Yu Qiao, Yihao Liu
分类: cs.CV
发布日期: 2025-12-25
备注: 27 pages, 14 figures, 17 tables
💡 一句话要点
UniPercept:面向美学、质量、结构和纹理的统一感知级图像理解框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 图像理解 感知层级特征 领域自适应 强化学习
📋 核心要点
- 现有多模态大语言模型在感知图像的美学、质量、结构和纹理等高层语义信息方面存在不足。
- UniPercept通过领域自适应预训练和任务对齐强化学习,提升模型在感知层级图像理解上的泛化能力。
- UniPercept在视觉评分和视觉问答任务上超越现有模型,并可作为文本到图像生成任务的奖励模型。
📝 摘要(中文)
多模态大型语言模型(MLLMs)在视觉理解任务(如视觉定位、分割和描述)中取得了显著进展。然而,它们感知图像感知层级特征的能力仍然有限。本文提出了UniPercept-Bench,一个统一的框架,用于跨越美学、质量、结构和纹理三个关键领域的感知层级图像理解。我们建立了一个分层定义系统,并构建了大规模数据集来评估感知层级图像理解。在此基础上,我们开发了一个强大的基线UniPercept,通过领域自适应预训练和任务对齐强化学习进行训练,从而实现了在视觉评分(VR)和视觉问答(VQA)任务中的鲁棒泛化。UniPercept在感知层级图像理解方面优于现有的MLLM,并且可以作为文本到图像生成的即插即用奖励模型。这项工作定义了MLLM时代下的感知层级图像理解,并通过引入全面的基准测试和强大的基线,为推进感知层级多模态图像理解奠定了坚实的基础。
🔬 方法详解
问题定义:现有方法在理解图像的感知层级特征(如美学、质量、结构和纹理)方面存在局限性。多模态大语言模型虽然在视觉任务上取得了进展,但缺乏对这些高层语义信息的有效建模和推理能力。这限制了它们在需要细粒度图像理解的应用中的表现。
核心思路:UniPercept的核心思路是构建一个统一的框架,通过大规模数据集和有效的训练策略,提升模型对图像感知层级特征的理解能力。通过领域自适应预训练,使模型能够更好地适应不同领域的图像数据。任务对齐强化学习则用于优化模型在特定任务上的表现,例如视觉评分和视觉问答。
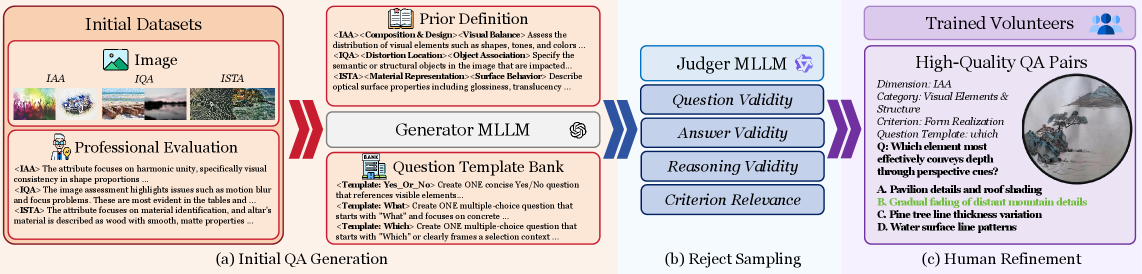
技术框架:UniPercept的整体框架包括以下几个主要模块:1) 数据收集与标注:构建大规模数据集,包含美学、质量、结构和纹理等方面的标注信息。2) 领域自适应预训练:利用大规模图像数据进行预训练,使模型学习到通用的视觉特征表示。3) 任务对齐强化学习:使用强化学习方法,根据特定任务的奖励信号,优化模型的参数。4) 评估与测试:在视觉评分和视觉问答等任务上评估模型的性能。
关键创新:UniPercept的关键创新在于:1) 提出了一个统一的框架,能够同时处理美学、质量、结构和纹理等多个感知层级特征。2) 采用了领域自适应预训练和任务对齐强化学习相结合的训练策略,有效提升了模型的泛化能力。3) 构建了大规模数据集,为感知层级图像理解的研究提供了数据支持。与现有方法相比,UniPercept能够更全面、更准确地理解图像的感知层级信息。
关键设计:在领域自适应预训练阶段,采用了对比学习损失函数,使模型能够学习到具有区分性的视觉特征表示。在任务对齐强化学习阶段,奖励信号的设计至关重要,需要根据具体任务进行调整。例如,在视觉评分任务中,可以使用人类评分作为奖励信号。网络结构方面,采用了Transformer架构,能够有效地捕捉图像中的长程依赖关系。
🖼️ 关键图片


📊 实验亮点
UniPercept在UniPercept-Bench基准测试中取得了显著的性能提升,在视觉评分(VR)和视觉问答(VQA)任务上均优于现有的多模态大语言模型。具体而言,UniPercept在美学、质量、结构和纹理等多个方面都取得了明显的改进,证明了其在感知层级图像理解方面的有效性。此外,UniPercept还被成功应用于文本到图像生成任务,作为奖励模型提升了生成图像的质量。
🎯 应用场景
UniPercept在图像质量评估、图像美学评分、图像编辑和生成等领域具有广泛的应用前景。它可以用于自动评估图像的质量和美观程度,为用户提供个性化的图像编辑建议,并作为文本到图像生成模型的奖励模型,提升生成图像的质量和真实感。该研究有助于推动计算机视觉技术在艺术、设计和娱乐等领域的应用。
📄 摘要(原文)
Multimodal large language models (MLLMs) have achieved remarkable progress in visual understanding tasks such as visual grounding, segmentation, and captioning. However, their ability to perceive perceptual-level image features remains limited. In this work, we present UniPercept-Bench, a unified framework for perceptual-level image understanding across three key domains: Aesthetics, Quality, Structure and Texture. We establish a hierarchical definition system and construct large-scale datasets to evaluate perceptual-level image understanding. Based on this foundation, we develop a strong baseline UniPercept trained via Domain-Adaptive Pre-Training and Task-Aligned RL, enabling robust generalization across both Visual Rating (VR) and Visual Question Answering (VQA) tasks. UniPercept outperforms existing MLLMs on perceptual-level image understanding and can serve as a plug-and-play reward model for text-to-image generation. This work defines Perceptual-Level Image Understanding in the era of MLLMs and, through the introduction of a comprehensive benchmark together with a strong baseline, provides a solid foundation for advancing perceptual-level multimodal image understanding.