TrackTeller: Temporal Multimodal 3D Grounding for Behavior-Dependent Object References
作者: Jiahong Yu, Ziqi Wang, Hailiang Zhao, Wei Zhai, Xueqiang Yan, Shuiguang Deng
分类: cs.CV, cs.AI
发布日期: 2025-12-25
💡 一句话要点
TrackTeller:提出时序多模态3D定位方法,解决行为依赖的对象指代问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D定位 时序推理 多模态融合 自然语言处理 自动驾驶
📋 核心要点
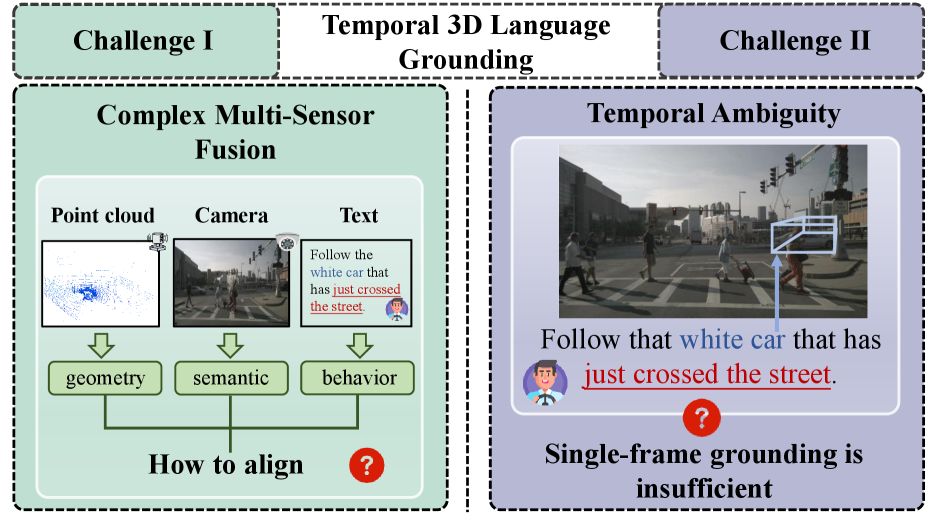
- 现有方法难以处理动态3D场景中基于运动或交互的对象指代,限制了交互式自动驾驶系统的发展。
- TrackTeller通过融合LiDAR-图像信息,结合语言条件解码和时序推理,实现更精确的3D对象定位。
- 实验表明,TrackTeller在NuPrompt基准测试中显著提升了语言定位跟踪性能,降低了误报率。
📝 摘要(中文)
本文研究了基于时序语言的3D定位问题,旨在利用多帧观测识别动态3D驾驶场景中被自然语言提及的对象。针对现有方法难以处理基于近期运动或短期交互的对象指代问题,我们提出了TrackTeller,一个时序多模态定位框架,它在一个统一的架构中集成了LiDAR-图像融合、语言条件解码和时序推理。TrackTeller构建了一个与文本语义对齐的共享UniScene表示,生成语言感知的3D候选框,并使用运动历史和短期动态来优化定位决策。在NuPrompt基准测试上的实验表明,TrackTeller持续提高了语言定位跟踪性能,在平均多目标跟踪精度上优于强大的基线70%,并将误报频率降低了3.15-3.4倍。
🔬 方法详解
问题定义:论文旨在解决动态3D驾驶场景中,自然语言指代对象的定位问题。现有方法主要依赖静态的外观或几何信息,无法有效处理那些通过近期运动或短期交互来描述的对象,导致定位精度下降,尤其是在需要理解对象行为的场景下。
核心思路:论文的核心思路是利用时序信息,将多帧的观测数据融入到定位过程中。通过分析对象的运动历史和短期动态,可以更准确地判断语言描述所指代的目标。同时,融合LiDAR和图像等多模态信息,增强对场景的理解。
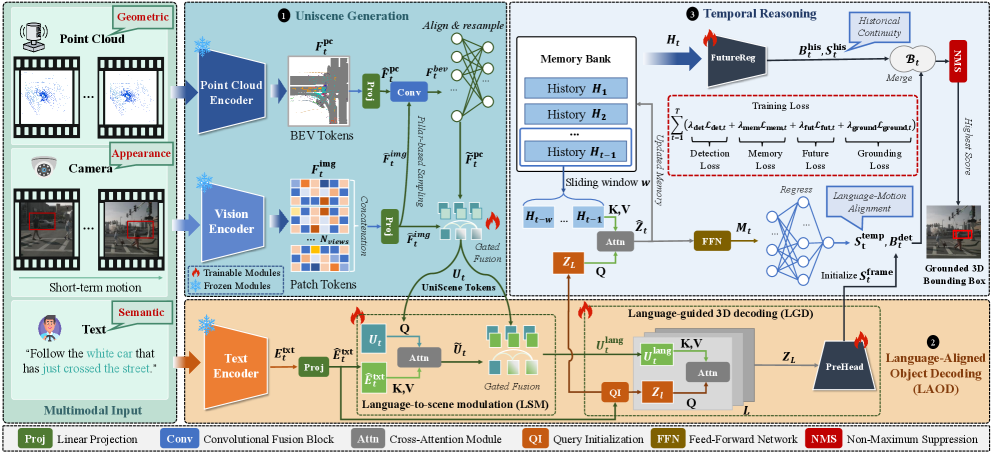
技术框架:TrackTeller框架包含以下几个主要模块:1) UniScene表示构建:融合LiDAR和图像信息,构建一个共享的场景表示,并与文本语义对齐。2) 语言感知3D候选框生成:根据语言描述,生成与语义相关的3D候选框。3) 时序推理:利用对象的运动历史和短期动态,对候选框进行优化和筛选,最终确定目标对象。
关键创新:TrackTeller的关键创新在于其时序推理模块,它能够有效地利用对象的运动信息来提高定位精度。与传统的静态定位方法相比,TrackTeller能够更好地理解基于行为的对象指代。此外,UniScene表示的构建也为多模态信息的融合提供了一个有效的平台。
关键设计:在UniScene表示构建中,采用了LiDAR和图像特征融合的方法,具体实现细节未知。在时序推理模块中,可能使用了循环神经网络(RNN)或Transformer等模型来处理时间序列数据。损失函数的设计可能包括定位损失、分类损失以及其他辅助损失,以提高模型的训练效果。具体参数设置和网络结构细节未知。
🖼️ 关键图片

📊 实验亮点
TrackTeller在NuPrompt基准测试中表现出色,平均多目标跟踪精度(AMOTA)相对基线提高了70%,误报频率降低了3.15-3.4倍。这些结果表明,TrackTeller能够有效地利用时序信息和多模态信息,显著提升语言定位跟踪的性能。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、智能监控等领域。例如,在自动驾驶中,系统可以根据驾驶员的语音指令,准确识别其所指代的车辆或行人,从而实现更安全、更智能的交互。在机器人导航中,机器人可以根据用户的语言描述,找到特定的物体或地点。该研究有助于提升人机交互的自然性和智能化水平。
📄 摘要(原文)
Understanding natural-language references to objects in dynamic 3D driving scenes is essential for interactive autonomous systems. In practice, many referring expressions describe targets through recent motion or short-term interactions, which cannot be resolved from static appearance or geometry alone. We study temporal language-based 3D grounding, where the objective is to identify the referred object in the current frame by leveraging multi-frame observations. We propose TrackTeller, a temporal multimodal grounding framework that integrates LiDAR-image fusion, language-conditioned decoding, and temporal reasoning in a unified architecture. TrackTeller constructs a shared UniScene representation aligned with textual semantics, generates language-aware 3D proposals, and refines grounding decisions using motion history and short-term dynamics. Experiments on the NuPrompt benchmark demonstrate that TrackTeller consistently improves language-grounded tracking performance, outperforming strong baselines with a 70% relative improvement in Average Multi-Object Tracking Accuracy and a 3.15-3.4 times reduction in False Alarm Frequency.