TAMEing Long Contexts in Personalization: Towards Training-Free and State-Aware MLLM Personalized Assistant
作者: Rongpei Hong, Jian Lang, Ting Zhong, Yong Wang, Fan Zhou
分类: cs.CV
发布日期: 2025-12-25
备注: Accepted by KDD 2026 research track. Code and data are available at https://github.com/ronpay/TAME
💡 一句话要点
提出TAME框架及LCMP基准,解决多模态大语言模型在个性化长程对话中的难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 个性化 长上下文 双重记忆 检索增强生成
📋 核心要点
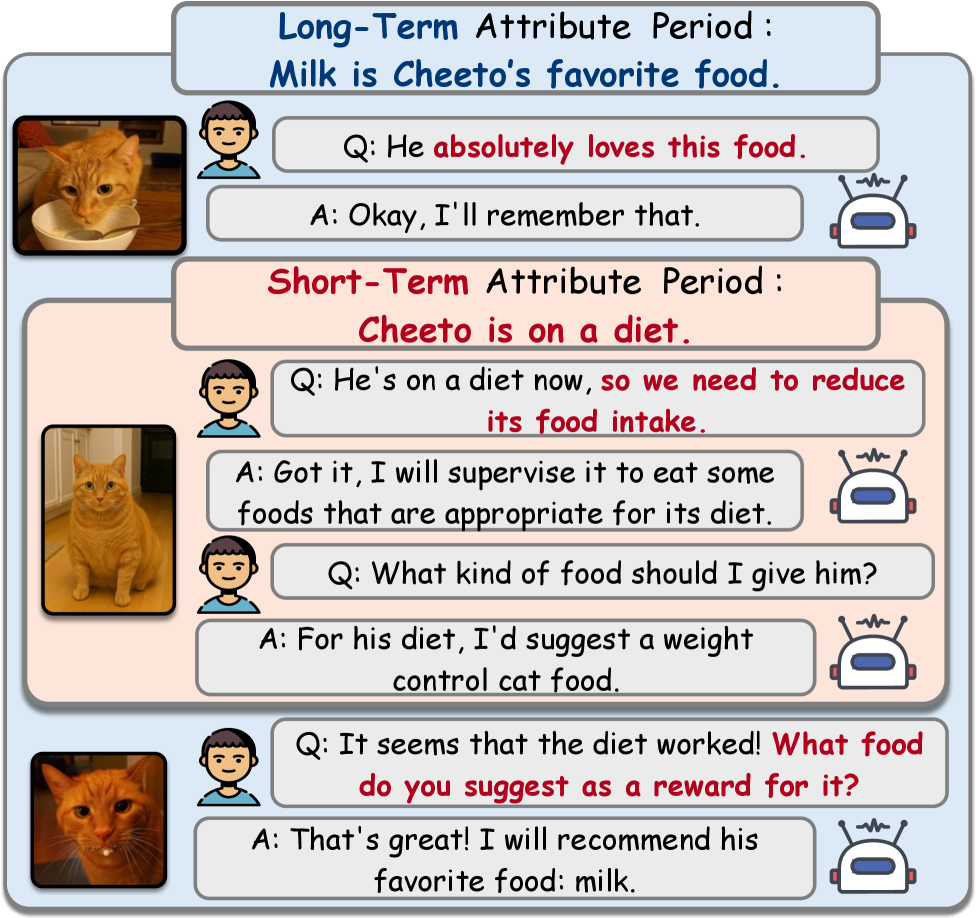
- 现有MLLM个性化方法缺乏对长程对话上下文的感知,无法处理个性化概念随时间的变化。
- TAME框架通过双重记忆和检索-对齐增强生成(RA2G)范例,使MLLM能够感知个性化概念的变化并生成上下文相关的响应。
- 在LCMP基准测试中,TAME取得了最佳性能,证明了其在长上下文场景中进行个性化对话的有效性。
📝 摘要(中文)
多模态大语言模型(MLLM)个性化是一个重要的研究问题,它有助于与针对特定实体(称为个性化概念)的MLLM进行个性化对话。然而,现有的方法和基准侧重于简单的、与上下文无关的视觉识别和个性化概念的文本替换(例如,“一只黄色的小狗”->“你的小狗Mochi”),忽略了支持长上下文对话的能力。理想的个性化MLLM助手应该能够与人类进行长上下文对话,并通过从过去的对话历史中学习不断提高其体验质量。为了弥合这一差距,我们提出了LCMP,这是第一个长上下文MLLM个性化评估基准。LCMP评估MLLM在感知个性化概念的变化并生成反映这些变化的上下文相关的个性化响应的能力。作为LCMP的强大基线,我们引入了一种新颖的免训练和状态感知框架TAME。TAME赋予MLLM双重记忆,以区分方式管理每个个性化概念的时间和持久变化。此外,TAME还包含一种新的免训练的检索-对齐增强生成(RA2G)范例。RA2G引入了一个对齐步骤,从多记忆检索的知识中提取上下文拟合的信息到当前问题,从而为复杂的真实世界用户查询实现更好的交互。LCMP上的实验表明,TAME实现了最佳性能,展示了长上下文场景中卓越且不断发展的交互体验。
🔬 方法详解
问题定义:现有MLLM个性化方法主要关注静态的视觉识别和文本替换,忽略了长程对话中个性化概念的动态变化。例如,用户对某个物品的喜好会随着时间推移而改变,而现有模型无法捕捉这种变化,导致对话不连贯或不准确。因此,需要一种能够感知上下文并适应个性化概念变化的MLLM个性化方法。
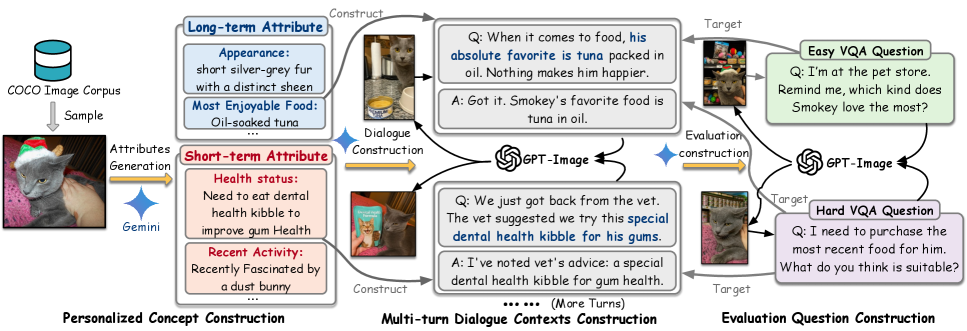
核心思路:TAME的核心思路是赋予MLLM记忆能力,使其能够记住并区分个性化概念的两种变化:时间变化(temporal variations)和持久变化(persistent variations)。通过双重记忆机制,模型可以分别存储这两种变化的信息,并在生成响应时进行综合考虑。此外,RA2G范例通过检索相关知识并进行对齐,确保生成的响应与当前上下文高度相关。
技术框架:TAME框架主要包含以下几个模块:1) 双重记忆模块:用于存储个性化概念的时间和持久变化信息。2) 检索模块:从双重记忆中检索与当前上下文相关的知识。3) 对齐模块:将检索到的知识与当前问题进行对齐,提取上下文拟合的信息。4) 生成模块:基于对齐后的信息生成个性化响应。整个流程是,首先利用双重记忆存储个性化信息,然后根据当前对话检索相关信息,对检索到的信息进行对齐,最后生成个性化的回复。
关键创新:TAME的关键创新在于以下几点:1) 提出了双重记忆机制,能够区分和管理个性化概念的时间和持久变化。2) 引入了免训练的RA2G范例,通过检索和对齐增强生成,提高了响应的上下文相关性。3) 提出了LCMP基准,用于评估MLLM在长上下文个性化对话中的能力。与现有方法相比,TAME无需训练,并且能够更好地处理长上下文和动态变化的个性化概念。
关键设计:TAME框架的关键设计包括:1) 双重记忆的组织方式:如何有效地存储和检索时间变化和持久变化的信息。2) 检索模块的相似度度量:如何准确地检索与当前上下文相关的知识。3) 对齐模块的对齐策略:如何将检索到的知识与当前问题进行有效对齐。4) 生成模块的生成策略:如何生成流畅且上下文相关的个性化响应。论文中可能涉及具体的向量相似度计算方法,以及对齐模块中使用的注意力机制等细节,但具体参数设置和损失函数等细节需要参考论文原文。
🖼️ 关键图片

📊 实验亮点
TAME在LCMP基准测试中取得了显著的性能提升,超越了现有的基线方法。实验结果表明,TAME能够更好地感知个性化概念的变化,并生成上下文相关的个性化响应。具体的性能数据和提升幅度需要在论文原文中查找,但总体而言,TAME展示了其在长上下文个性化对话中的优越性。
🎯 应用场景
TAME框架具有广泛的应用前景,例如个性化智能助手、定制化教育、智能客服等。它可以根据用户的历史对话和偏好,提供更加个性化和贴心的服务。通过不断学习和适应用户的需求,TAME可以显著提升用户体验,并为各行各业带来实际价值。未来,TAME还可以与其他技术相结合,例如语音识别、情感分析等,实现更加智能和人性化的交互。
📄 摘要(原文)
Multimodal Large Language Model (MLLM) Personalization is a critical research problem that facilitates personalized dialogues with MLLMs targeting specific entities (known as personalized concepts). However, existing methods and benchmarks focus on the simple, context-agnostic visual identification and textual replacement of the personalized concept (e.g., "A yellow puppy" -> "Your puppy Mochi"), overlooking the ability to support long-context conversations. An ideal personalized MLLM assistant is capable of engaging in long-context dialogues with humans and continually improving its experience quality by learning from past dialogue histories. To bridge this gap, we propose LCMP, the first Long-Context MLLM Personalization evaluation benchmark. LCMP assesses the capability of MLLMs in perceiving variations of personalized concepts and generating contextually appropriate personalized responses that reflect these variations. As a strong baseline for LCMP, we introduce a novel training-free and state-aware framework TAME. TAME endows MLLMs with double memories to manage the temporal and persistent variations of each personalized concept in a differentiated manner. In addition, TAME incorporates a new training-free Retrieve-then-Align Augmented Generation (RA2G) paradigm. RA2G introduces an alignment step to extract the contextually fitted information from the multi-memory retrieved knowledge to the current questions, enabling better interactions for complex real-world user queries. Experiments on LCMP demonstrate that TAME achieves the best performance, showcasing remarkable and evolving interaction experiences in long-context scenarios.