From Shallow Humor to Metaphor: Towards Label-Free Harmful Meme Detection via LMM Agent Self-Improvement
作者: Jian Lang, Rongpei Hong, Ting Zhong, Leiting Chen, Qiang Gao, Fan Zhou
分类: cs.CV
发布日期: 2025-12-25
备注: 12 pages. Accepted by KDD 2026 research track. Codes are released at https://github.com/Jian-Lang/ALARM
💡 一句话要点
提出ALARM框架,利用LMM Agent自提升实现无标签有害Meme检测。
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 有害Meme检测 无监督学习 多模态学习 大型多模态模型 Agent自提升
📋 核心要点
- 现有有害Meme检测方法依赖大量标注数据,成本高昂且难以适应内容快速演变。
- ALARM框架利用LMM Agent自提升,从“浅层”Meme学习,逐步提升检测复杂Meme的能力。
- 实验表明,ALARM在多个数据集上表现优异,甚至超越了有监督方法,具有很强的适应性。
📝 摘要(中文)
在线媒体上有害Meme的泛滥对公共健康和社会稳定构成严重威胁。现有的检测方法严重依赖于大规模标注数据进行训练,这需要大量的人工标注工作,并限制了它们对不断演变的有害内容的适应性。为了解决这些挑战,我们提出了ALARM,这是第一个基于大型多模态模型(LMM)Agent自提升的无标签有害Meme检测框架。ALARM的核心创新在于利用“浅层”Meme的表达信息来迭代地增强其处理更复杂和微妙Meme的能力。ALARM包含一种新颖的基于置信度的显式Meme识别机制,该机制从原始数据集中分离出显式Meme并为其分配伪标签。此外,还引入了一种新的成对学习引导的Agent自提升范式,其中显式Meme被重组为对比对(正例vs.负例)以改进学习器LMM Agent。该Agent自主地从这些对中推导出高层检测线索,进而使Agent本身能够有效地处理复杂和具有挑战性的Meme。在三个不同的数据集上的实验表明,ALARM具有卓越的性能和对新演变的Meme的强大适应性。值得注意的是,我们的方法甚至优于标签驱动的方法。这些结果突出了无标签框架作为一种可扩展且有前景的解决方案的潜力,可以适应动态在线环境中新型形式和主题的有害Meme。
🔬 方法详解
问题定义:现有有害Meme检测方法依赖于大量人工标注的数据,这不仅耗时耗力,而且难以跟上有害Meme快速演变的趋势。模型泛化能力受限,难以有效检测新型有害Meme。
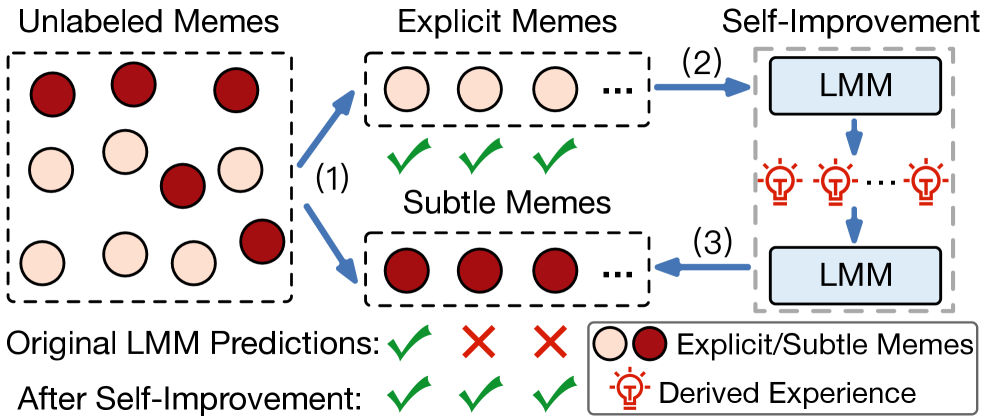
核心思路:ALARM框架的核心思路是利用LMM Agent的自学习能力,通过从易到难的方式逐步提升其检测有害Meme的能力。首先识别出易于识别的“浅层”Meme,然后利用这些“浅层”Meme作为知识来源,训练Agent来检测更复杂的Meme。
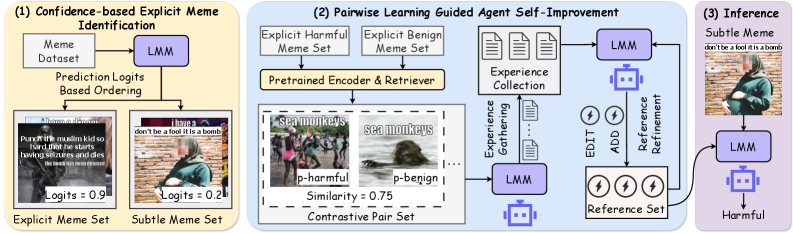
技术框架:ALARM框架主要包含两个阶段:1) 基于置信度的显式Meme识别:从原始数据集中识别出置信度高的“浅层”Meme,并赋予伪标签。2) 成对学习引导的Agent自提升:将“浅层”Meme重组为对比对(正例vs.负例),用于训练LMM Agent。Agent通过学习这些对比对,自主地推导出高层检测线索,从而提升其检测复杂Meme的能力。
关键创新:ALARM框架的关键创新在于提出了一个无标签的有害Meme检测框架,避免了对大量标注数据的依赖。通过LMM Agent的自学习和自提升,实现了对新型有害Meme的有效检测。此外,提出的基于置信度的显式Meme识别机制和成对学习引导的Agent自提升范式,为LMM在无监督学习领域的应用提供了新的思路。
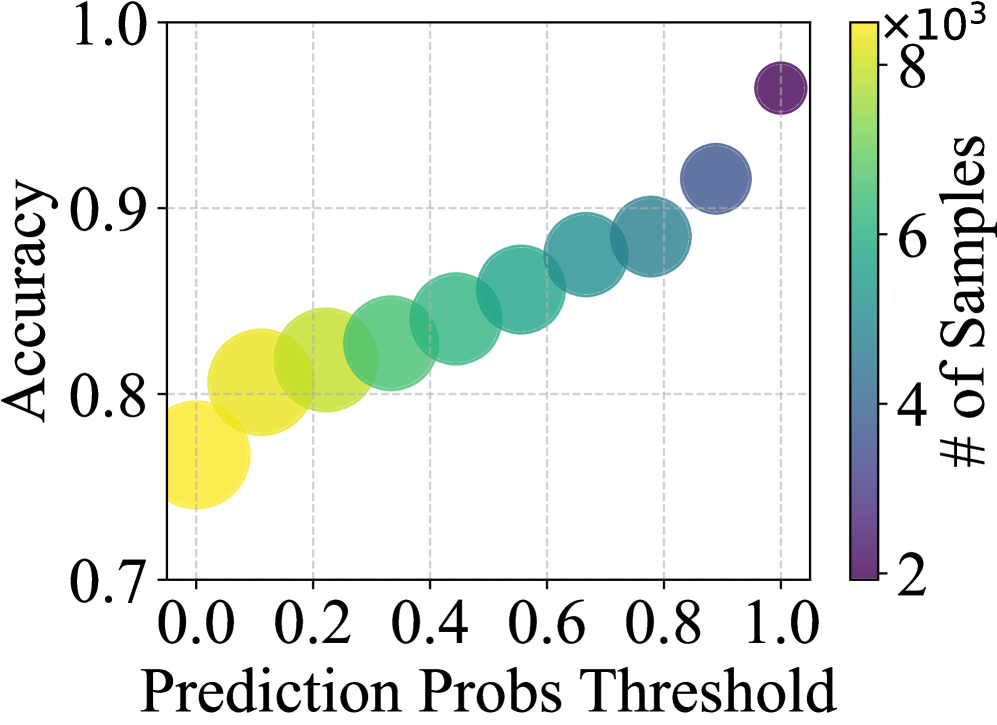
关键设计:在基于置信度的显式Meme识别阶段,使用预训练的LMM模型对Meme进行分类,并根据模型的置信度来判断是否为“浅层”Meme。在成对学习引导的Agent自提升阶段,设计了对比损失函数,用于训练LMM Agent。对比损失函数的目标是拉近正例对之间的距离,推远负例对之间的距离。具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
ALARM框架在三个不同的数据集上进行了实验,结果表明其性能优于现有的无监督方法,甚至可以与有监督方法相媲美。这表明ALARM具有很强的泛化能力和适应性,能够有效检测新型有害Meme。具体的性能数据未知。
🎯 应用场景
ALARM框架可应用于在线社交媒体平台,用于自动检测和过滤有害Meme,维护健康的网络环境。该研究成果有助于降低人工审核成本,提高有害信息处理效率,并为其他无监督多模态内容理解任务提供借鉴。
📄 摘要(原文)
The proliferation of harmful memes on online media poses significant risks to public health and stability. Existing detection methods heavily rely on large-scale labeled data for training, which necessitates substantial manual annotation efforts and limits their adaptability to the continually evolving nature of harmful content. To address these challenges, we present ALARM, the first lAbeL-free hARmful Meme detection framework powered by Large Multimodal Model (LMM) agent self-improvement. The core innovation of ALARM lies in exploiting the expressive information from "shallow" memes to iteratively enhance its ability to tackle more complex and subtle ones. ALARM consists of a novel Confidence-based Explicit Meme Identification mechanism that isolates the explicit memes from the original dataset and assigns them pseudo-labels. Besides, a new Pairwise Learning Guided Agent Self-Improvement paradigm is introduced, where the explicit memes are reorganized into contrastive pairs (positive vs. negative) to refine a learner LMM agent. This agent autonomously derives high-level detection cues from these pairs, which in turn empower the agent itself to handle complex and challenging memes effectively. Experiments on three diverse datasets demonstrate the superior performance and strong adaptability of ALARM to newly evolved memes. Notably, our method even outperforms label-driven methods. These results highlight the potential of label-free frameworks as a scalable and promising solution for adapting to novel forms and topics of harmful memes in dynamic online environments.