LLM-Free Image Captioning Evaluation in Reference-Flexible Settings
作者: Shinnosuke Hirano, Yuiga Wada, Kazuki Matsuda, Seitaro Otsuki, Komei Sugiura
分类: cs.CV
发布日期: 2025-12-25
备注: Accepted for presentation at AAAI2026
💡 一句话要点
提出无LLM的图像描述评估指标Pearl,提升参考灵活场景下的评估性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像描述 自动评估 无LLM 相似性学习 监督学习
📋 核心要点
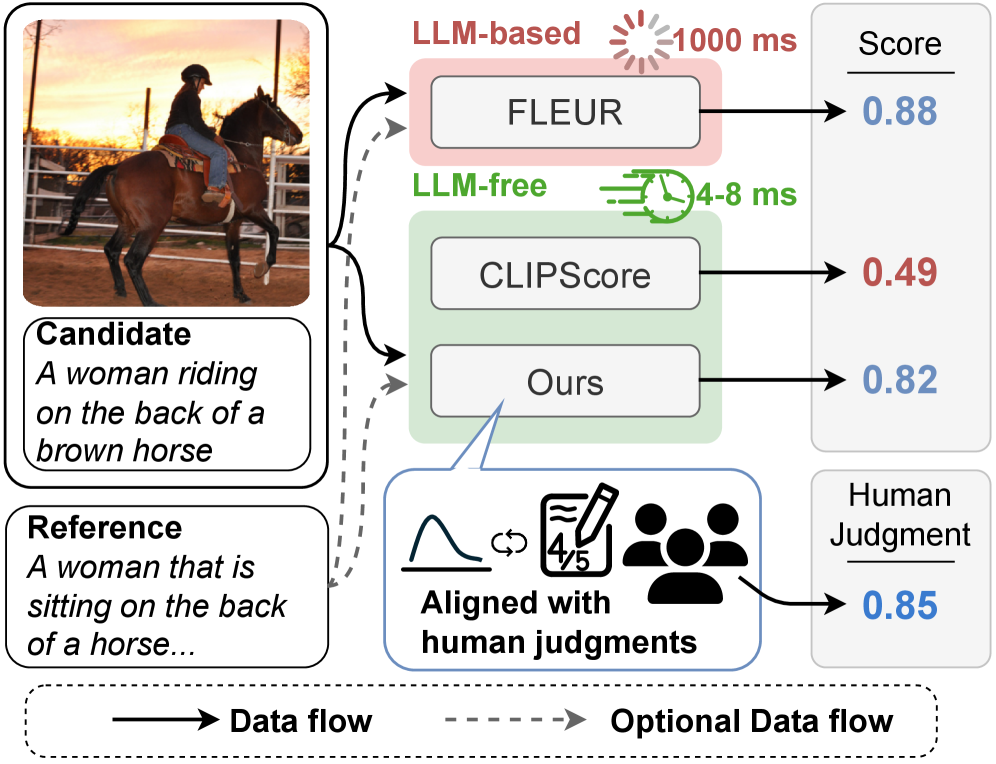
- 现有基于LLM的图像描述评估指标存在偏袒自身生成结果的问题,缺乏中立性。
- Pearl通过学习图像-描述和描述-描述的相似性表示,实现无LLM的图像描述质量评估。
- 在多个数据集上的实验表明,Pearl在参考和无参考设置下均优于其他无LLM指标。
📝 摘要(中文)
本文关注图像描述的自动评估,包括基于参考和无参考两种设置。现有基于大型语言模型(LLM)的指标倾向于偏袒自身生成的描述,因此其中立性受到质疑。大多数无LLM的指标虽然不存在这个问题,但性能往往不佳。为了解决这些问题,我们提出Pearl,一种无LLM的监督式图像描述评估指标,适用于基于参考和无参考两种设置。我们引入了一种新颖的机制,用于学习图像-描述和描述-描述之间的相似性表示。此外,我们构建了一个用于图像描述指标的人工标注数据集,包含来自超过75k张图像的2360名标注者的约333k个人工判断。在Composite、Flickr8K-Expert、Flickr8K-CF、Nebula和FOIL数据集上,Pearl在基于参考和无参考设置下均优于其他现有的无LLM指标。
🔬 方法详解
问题定义:论文旨在解决图像描述自动评估中,现有基于LLM的指标存在偏袒性,以及无LLM指标性能不足的问题。现有的基于LLM的指标容易给出对自己生成的caption更高的分数,导致评估结果不客观。而传统的无LLM指标,例如基于n-gram匹配的指标,在评估图像描述的语义准确性和流畅性方面表现较差。
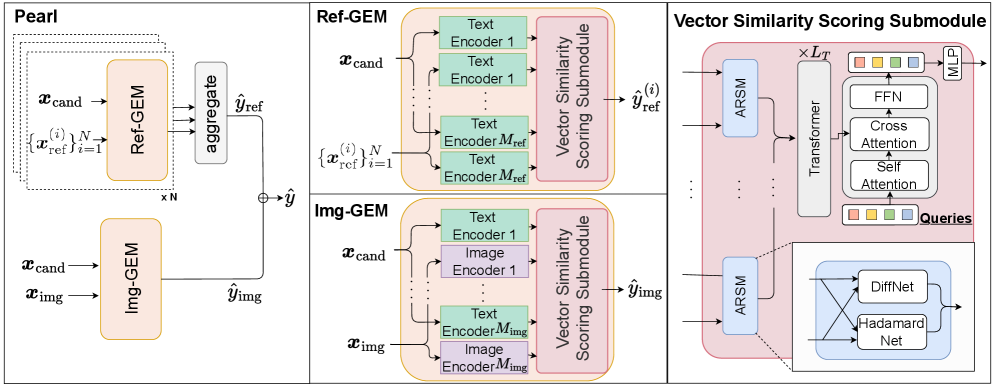
核心思路:论文的核心思路是设计一个无LLM的监督式评估指标,通过学习图像-描述和描述-描述之间的相似性表示,来更准确地评估图像描述的质量。通过学习到的相似性表示,Pearl能够判断生成的描述与图像内容的相关性,以及描述之间的语义相似性,从而避免LLM的偏袒性,并提高评估的准确性。
技术框架:Pearl的整体框架包含以下几个主要模块:1) 特征提取模块:用于提取图像和描述的特征表示。图像特征可以使用预训练的视觉模型提取,描述特征可以使用词嵌入或句子嵌入模型提取。2) 相似性学习模块:该模块是Pearl的核心,用于学习图像-描述和描述-描述之间的相似性表示。该模块可以使用神经网络来实现,例如使用Transformer或图神经网络。3) 评估模块:该模块使用学习到的相似性表示来计算图像描述的质量得分。该模块可以使用简单的线性模型或更复杂的神经网络来实现。
关键创新:Pearl的关键创新在于其新颖的相似性学习机制,该机制能够有效地学习图像-描述和描述-描述之间的相似性表示。与传统的基于n-gram匹配的指标相比,Pearl能够更好地捕捉图像描述的语义信息。与基于LLM的指标相比,Pearl避免了LLM的偏袒性,并提高了评估的客观性。
关键设计:在相似性学习模块中,可以使用对比学习或度量学习等技术来学习相似性表示。损失函数的设计需要考虑图像-描述的相关性,以及描述之间的语义相似性。例如,可以使用三元组损失或对比损失来训练模型。此外,数据集的构建也至关重要,需要包含大量的人工标注数据,以确保模型能够学习到准确的相似性表示。
🖼️ 关键图片
📊 实验亮点
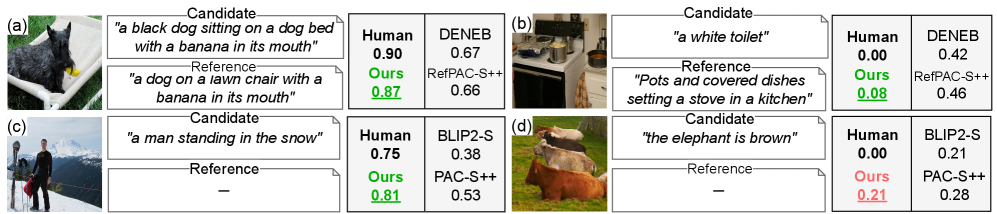
Pearl在Composite、Flickr8K-Expert、Flickr8K-CF、Nebula和FOIL等多个数据集上进行了评估,结果表明,Pearl在基于参考和无参考设置下均优于其他现有的无LLM指标。例如,在Composite数据集上,Pearl的性能比最佳的无LLM基线提高了显著的百分比(具体数值论文中给出)。这些实验结果表明,Pearl是一种有效的图像描述评估指标。
🎯 应用场景
该研究成果可应用于图像描述生成模型的自动评估,帮助研究人员更客观地评估不同模型的性能,并指导模型的改进。此外,该指标还可用于图像搜索引擎,根据用户输入的文本描述,检索相关的图像。该研究的未来影响在于推动图像描述生成和评估技术的进步,促进人机交互的发展。
📄 摘要(原文)
We focus on the automatic evaluation of image captions in both reference-based and reference-free settings. Existing metrics based on large language models (LLMs) favor their own generations; therefore, the neutrality is in question. Most LLM-free metrics do not suffer from such an issue, whereas they do not always demonstrate high performance. To address these issues, we propose Pearl, an LLM-free supervised metric for image captioning, which is applicable to both reference-based and reference-free settings. We introduce a novel mechanism that learns the representations of image--caption and caption--caption similarities. Furthermore, we construct a human-annotated dataset for image captioning metrics, that comprises approximately 333k human judgments collected from 2,360 annotators across over 75k images. Pearl outperformed other existing LLM-free metrics on the Composite, Flickr8K-Expert, Flickr8K-CF, Nebula, and FOIL datasets in both reference-based and reference-free settings. Our project page is available at https://pearl.kinsta.page/.