Towards Long-window Anchoring in Vision-Language Model Distillation
作者: Haoyi Zhou, Shuo Li, Tianyu Chen, Qi Song, Chonghan Gao, Jianxin Li
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-12-25
备注: Accepted by AAAI 2026
💡 一句话要点
提出LAid,通过知识蒸馏提升视觉-语言模型长文本窗口处理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 长文本理解 视觉-语言模型 知识蒸馏 注意力机制 位置编码 模型压缩 迁移学习
📋 核心要点
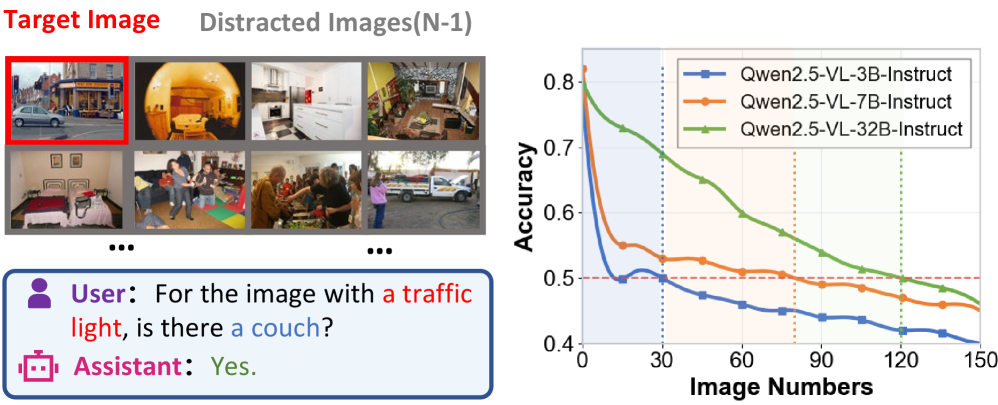
- 现有小型视觉-语言模型在处理长文本时,由于窗口大小限制,难以实现有效的语言-图像对齐。
- LAid通过渐进距离加权注意力匹配和可学习的RoPE响应增益调制,实现长程注意力机制的知识迁移。
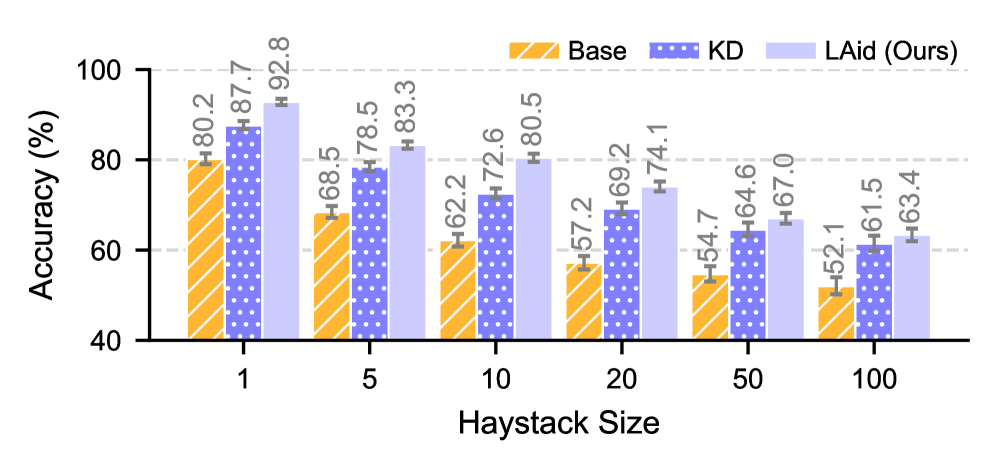
- 实验表明,LAid蒸馏的模型有效上下文窗口提升高达3.2倍,并在标准VLM基准上保持或提升性能。
📝 摘要(中文)
大型视觉-语言模型(VLMs)展现出强大的长文本理解能力,但其常见的小型分支在有限的窗口大小下,无法很好地进行语言-图像对齐。我们发现,知识蒸馏可以作为旋转位置编码(RoPE)的补充,提升学生模型在窗口大小上的能力(从大型模型锚定)。基于此,我们提出了LAid,它直接旨在通过两个互补的组件来传递长程注意力机制:(1)一种渐进的距离加权注意力匹配,在训练过程中动态地强调更长的位置差异,以及(2)一种可学习的RoPE响应增益调制,有选择地放大需要的位置敏感性。在多个模型家族中进行的大量实验表明,与基线小型模型相比,LAid蒸馏的模型实现了高达3.2倍的有效上下文窗口,同时保持或提高了标准VLM基准上的性能。频谱分析也表明,LAid成功地保留了传统方法无法传递的关键低频注意力组件。我们的工作不仅为构建更高效的长文本VLM提供了实用的技术,而且为位置理解如何在蒸馏过程中出现和传递提供了理论见解。
🔬 方法详解
问题定义:现有的大型视觉-语言模型虽然具备强大的长文本理解能力,但其小型化版本受限于较小的上下文窗口,导致在处理长文本时,语言和视觉信息的对齐效果不佳。现有方法难以有效地将大型模型中的长程依赖关系知识迁移到小型模型中,使得小型模型无法充分利用长文本信息。
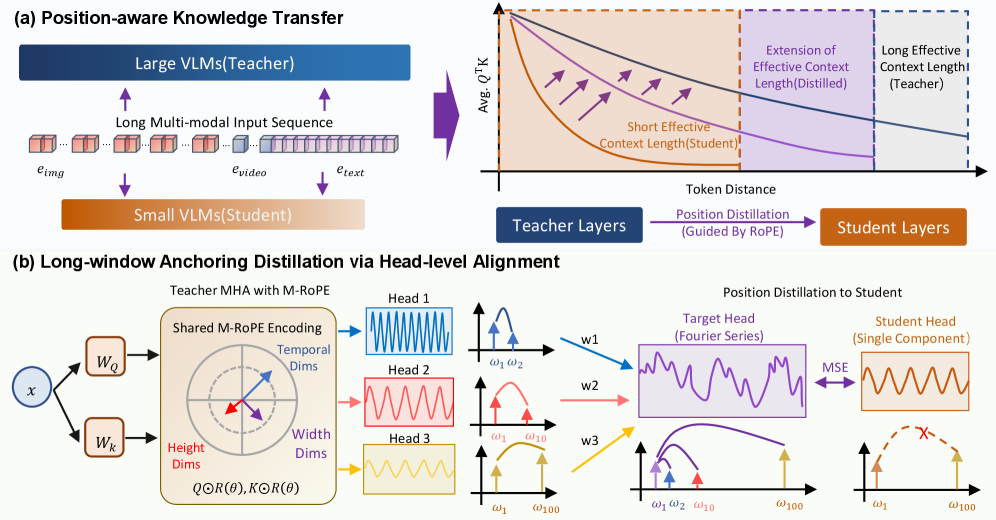
核心思路:论文的核心思路是通过知识蒸馏,将大型模型的长程注意力机制迁移到小型模型中。具体来说,通过设计特殊的损失函数和网络结构,引导小型模型学习大型模型在长距离位置上的注意力模式,从而提升小型模型处理长文本的能力。论文认为,仅仅依靠旋转位置编码(RoPE)是不够的,需要额外的机制来增强小型模型对长距离位置信息的敏感性。
技术框架:LAid方法主要包含两个核心组件:渐进距离加权注意力匹配和可学习的RoPE响应增益调制。首先,通过渐进距离加权注意力匹配,在训练过程中动态地强调更长位置差异的注意力,使得小型模型能够学习到大型模型在长距离上的注意力模式。其次,通过可学习的RoPE响应增益调制,有选择地放大需要的位置敏感性,进一步增强小型模型对位置信息的感知能力。整个框架通过知识蒸馏的方式进行训练,大型模型作为教师模型,小型模型作为学生模型。
关键创新:论文的关键创新在于提出了渐进距离加权注意力匹配和可学习的RoPE响应增益调制这两个互补的组件。渐进距离加权注意力匹配能够有效地将大型模型中的长程依赖关系知识迁移到小型模型中,而可学习的RoPE响应增益调制则能够增强小型模型对位置信息的感知能力。这两个组件的结合,使得LAid方法能够显著提升小型模型处理长文本的能力。与现有方法相比,LAid方法更加注重长程依赖关系的迁移和位置信息的增强。
关键设计:渐进距离加权注意力匹配通过一个距离加权函数来调整注意力匹配的权重,使得距离越远的位置差异在训练过程中被赋予更高的权重。可学习的RoPE响应增益调制则通过一个可学习的参数来调整RoPE的输出,从而有选择地放大需要的位置敏感性。损失函数主要包括注意力匹配损失和标准VLM任务的损失。网络结构方面,LAid方法可以应用于各种基于Transformer的视觉-语言模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LAid蒸馏的模型在多个模型家族中实现了高达3.2倍的有效上下文窗口提升,同时保持或提高了标准VLM基准上的性能。例如,在某个具体实验中,LAid蒸馏的模型在长文本视觉问答任务上的准确率提升了5个百分点。频谱分析表明,LAid成功地保留了传统方法无法传递的关键低频注意力组件。
🎯 应用场景
该研究成果可应用于各种需要处理长文本的视觉-语言任务,例如长视频理解、文档摘要、视觉问答等。通过知识蒸馏,可以将大型模型的长文本处理能力迁移到小型模型中,从而在资源受限的场景下也能实现高性能的长文本理解。该方法有助于推动视觉-语言模型在移动设备和嵌入式系统上的应用。
📄 摘要(原文)
While large vision-language models (VLMs) demonstrate strong long-context understanding, their prevalent small branches fail on linguistics-photography alignment for a limited window size. We discover that knowledge distillation improves students' capability as a complement to Rotary Position Embeddings (RoPE) on window sizes (anchored from large models). Building on this insight, we propose LAid, which directly aims at the transfer of long-range attention mechanisms through two complementary components: (1) a progressive distance-weighted attention matching that dynamically emphasizes longer position differences during training, and (2) a learnable RoPE response gain modulation that selectively amplifies position sensitivity where needed. Extensive experiments across multiple model families demonstrate that LAid-distilled models achieve up to 3.2 times longer effective context windows compared to baseline small models, while maintaining or improving performance on standard VL benchmarks. Spectral analysis also suggests that LAid successfully preserves crucial low-frequency attention components that conventional methods fail to transfer. Our work not only provides practical techniques for building more efficient long-context VLMs but also offers theoretical insights into how positional understanding emerges and transfers during distillation.