Hierarchy-Aware Fine-Tuning of Vision-Language Models
作者: Jiayu Li, Rajesh Gangireddy, Samet Akcay, Wei Cheng, Juhua Hu
分类: cs.CV, cs.AI
发布日期: 2025-12-25
💡 一句话要点
提出层级感知微调框架,高效提升视觉-语言模型在层级分类任务上的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 层级分类 微调 知识图谱 多模态学习
📋 核心要点
- 现有视觉-语言模型在层级分类中忽略了标签的层级结构,导致训练成本高昂且层级间预测不一致。
- 论文提出层级感知微调框架,通过树路径KL散度和层级兄弟平滑交叉熵,在VLM共享嵌入空间中实现层级一致性。
- 实验表明,该方法在多个基准测试中,以极小的参数开销显著提升了全路径准确率并降低了不一致性误差。
📝 摘要(中文)
视觉-语言模型(VLM)通过大规模图像-文本预训练学习到强大的多模态表示,但将其应用于层级分类的研究尚不充分。现有方法将标签视为扁平类别,需要完全微调,这既昂贵又导致分类体系各层级间预测不一致。我们提出了一个高效的层级感知微调框架,该框架仅更新少量参数,同时强制执行结构一致性。我们结合了两个目标:树路径KL散度(TP-KL),用于对齐沿真实标签路径的预测,以实现垂直连贯性;层级兄弟平滑交叉熵(HiSCE),用于鼓励兄弟类别之间的一致性预测。两种损失都在VLM的共享嵌入空间中工作,并与轻量级LoRA适配相结合。在多个基准测试上的实验表明,该方法以最小的参数开销,在全路径准确率和基于树的不一致性误差方面均实现了持续改进。我们的方法为将VLM适配到结构化分类体系提供了一种有效的策略。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型(VLM)在层级分类任务中表现不佳的问题。现有方法通常将层级标签视为扁平的类别,忽略了标签之间的层级关系,导致需要对整个模型进行微调,计算成本高昂,并且容易产生层级结构上的不一致性,即一个样本可能被错误地分类到其父节点或子节点上。
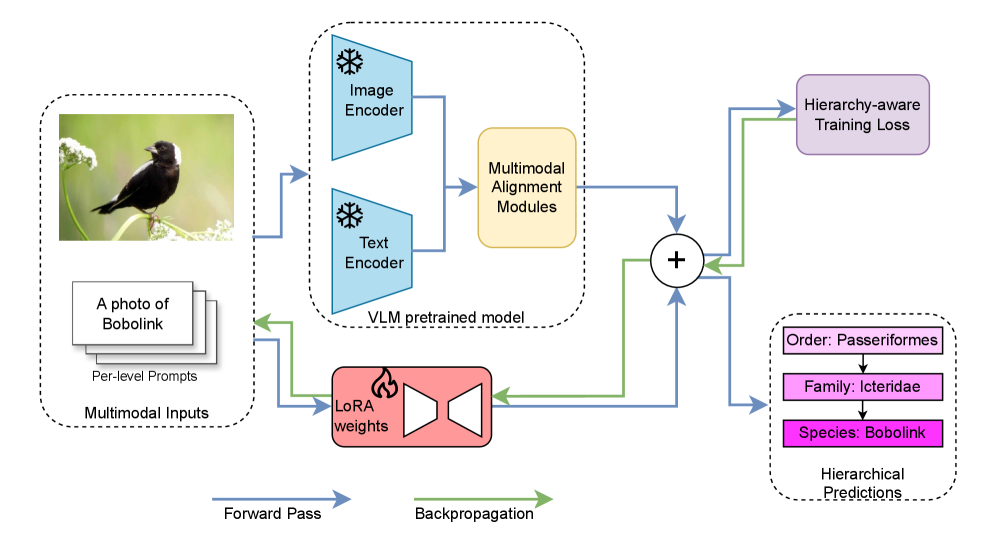
核心思路:论文的核心思路是在微调VLM时,显式地利用标签的层级结构信息,从而提高模型在层级分类任务中的性能和一致性。通过引入新的损失函数,鼓励模型学习到符合层级结构的表示,并减少层级结构上的不一致性。同时,采用参数高效的微调方法(LoRA),降低计算成本。
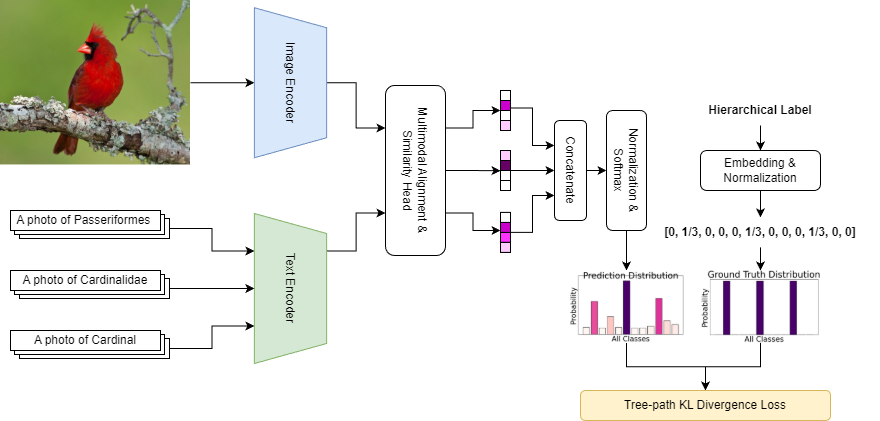
技术框架:该框架主要包含以下几个部分:首先,使用预训练的VLM提取图像和文本的特征。然后,将提取的特征输入到分类器中,得到预测的类别概率分布。接着,计算两个损失函数:Tree-Path KL Divergence (TP-KL) 和 Hierarchy-Sibling Smoothed Cross-Entropy (HiSCE)。TP-KL损失用于对齐预测结果与真实标签路径,确保垂直方向上的一致性。HiSCE损失用于平滑兄弟节点之间的预测结果,鼓励兄弟节点之间的一致性。最后,将两个损失函数加权求和,得到总的损失函数,用于微调VLM的参数。
关键创新:论文的关键创新在于提出了两种新的损失函数:TP-KL和HiSCE,用于显式地建模标签的层级结构信息。TP-KL损失通过最小化预测概率分布与真实标签路径之间的KL散度,鼓励模型预测结果与层级结构保持一致。HiSCE损失通过平滑兄弟节点之间的预测结果,减少了层级结构上的不一致性。此外,论文还采用了参数高效的微调方法(LoRA),降低了计算成本。
关键设计:TP-KL损失的关键设计在于定义了真实标签路径。对于一个给定的样本,其真实标签路径是从根节点到该样本标签的路径。TP-KL损失的目标是最小化模型预测的概率分布与该路径上的概率分布之间的KL散度。HiSCE损失的关键设计在于定义了兄弟节点之间的平滑方式。论文采用了一种基于温度系数的平滑方法,通过调整温度系数来控制平滑的程度。此外,论文还使用了LoRA进行参数高效的微调,只更新少量参数,从而降低了计算成本。
🖼️ 关键图片
📊 实验亮点
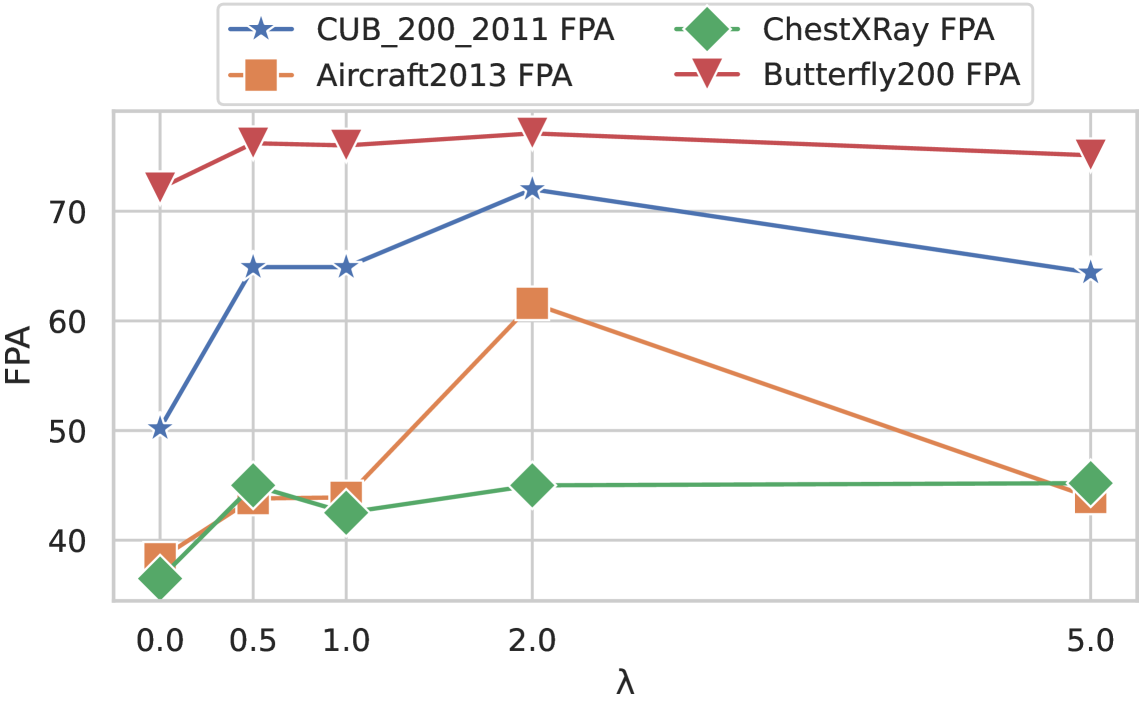
实验结果表明,该方法在多个基准测试中均取得了显著的性能提升。例如,在ImageNet数据集上,该方法在Full-Path Accuracy指标上提升了超过5%,同时显著降低了Tree-based Inconsistency Error。与完全微调相比,该方法仅需更新少量参数,大大降低了计算成本。
🎯 应用场景
该研究成果可广泛应用于需要层级分类的场景,例如:生物分类、产品分类、医学诊断等。通过提升VLM在层级分类任务上的性能,可以更准确地识别图像和文本中的对象,从而提高相关应用的智能化水平。例如,在医学诊断中,可以更准确地诊断疾病的类型和严重程度,辅助医生进行决策。
📄 摘要(原文)
Vision-Language Models (VLMs) learn powerful multimodal representations through large-scale image-text pretraining, but adapting them to hierarchical classification is underexplored. Standard approaches treat labels as flat categories and require full fine-tuning, which is expensive and produces inconsistent predictions across taxonomy levels. We propose an efficient hierarchy-aware fine-tuning framework that updates a few parameters while enforcing structural consistency. We combine two objectives: Tree-Path KL Divergence (TP-KL) aligns predictions along the ground-truth label path for vertical coherence, while Hierarchy-Sibling Smoothed Cross-Entropy (HiSCE) encourages consistent predictions among sibling classes. Both losses work in the VLM's shared embedding space and integrate with lightweight LoRA adaptation. Experiments across multiple benchmarks show consistent improvements in Full-Path Accuracy and Tree-based Inconsistency Error with minimal parameter overhead. Our approach provides an efficient strategy for adapting VLMs to structured taxonomies.