Fixed-Budget Parameter-Efficient Training with Frozen Encoders Improves Multimodal Chest X-Ray Classification
作者: Md Ashik Khan, Md Nahid Siddique
分类: cs.CV
发布日期: 2025-12-25
备注: Accepted at the 2025 28th International Conference on Computer and Information Technology (ICCIT). 6 pages, 6 figures
💡 一句话要点
冻结编码器的参数高效训练提升多模态胸部X光分类性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 胸部X光 参数高效训练 冻结编码器 迁移学习
📋 核心要点
- 现有方法在多模态胸部X光分析中微调大型视觉-语言模型,计算成本高昂,限制了其应用。
- 论文提出采用参数高效训练策略,冻结编码器并使用BitFit、LoRA和Adapter等方法,降低计算成本。
- 实验结果表明,在固定参数预算下,参数高效训练方法显著优于全参数微调,且具有良好的可扩展性。
📝 摘要(中文)
多模态胸部X光分析通常需要微调大型视觉-语言模型,计算成本高昂。本文研究了参数高效训练(PET)策略,包括冻结编码器、BitFit、LoRA和适配器,用于Indiana University Chest X-Ray数据集上的多标签分类(3,851张图像-报告对;579个测试样本)。为了减轻数据泄露,我们从用作文本输入的报告中删除了病理术语,同时保留了临床背景。在固定的参数预算下(237万个参数,占总参数的2.51%),所有PET变体的AUROC均在0.892和0.908之间,优于完全微调(0.770 AUROC),后者使用9430万个可训练参数,减少了40倍。在CheXpert(224,316张图像,大58倍)上的外部验证证实了可扩展性:所有PET方法都实现了>0.69的AUROC,且可训练参数<9%,其中Adapter实现了最佳性能(0.7214 AUROC)。预算匹配的比较表明,仅视觉模型(0.653 AUROC,106万个参数)优于预算匹配的多模态模型(0.641 AUROC,106万个参数),表明性能的提升主要来自参数分配,而不是跨模态协同作用。虽然PET方法显示出比简单模型更差的校准(ECE:0.29-0.34)(ECE:0.049),但这代表了一个可以通过事后校准方法解决的可控限制。这些发现表明,冻结编码器策略以大大降低的计算成本提供了卓越的区分能力,但校准校正对于临床部署至关重要。
🔬 方法详解
问题定义:论文旨在解决多模态胸部X光图像分析中,全参数微调大型视觉-语言模型带来的高计算成本问题。现有方法需要大量的计算资源和时间,限制了其在资源受限环境中的应用,并且可能导致过拟合。
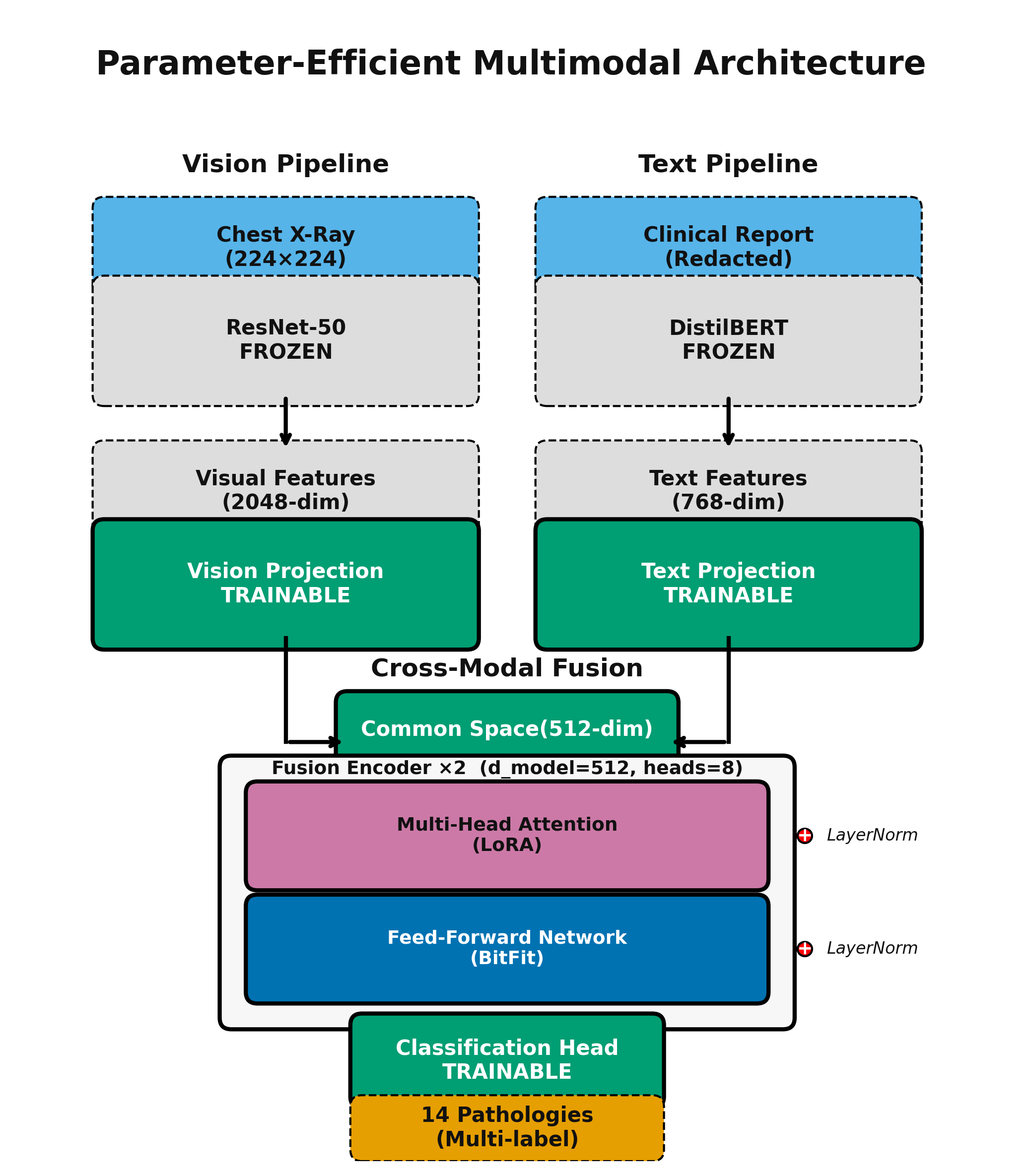
核心思路:论文的核心思路是采用参数高效训练(PET)策略,通过冻结预训练模型的编码器部分,仅训练少量参数,从而显著降低计算成本。同时,探索不同的PET变体(BitFit、LoRA、Adapter)以找到最佳的参数分配方案。
技术框架:整体框架包括以下几个主要步骤:1) 数据预处理:对胸部X光图像和对应的文本报告进行预处理,包括病理术语的删除以防止数据泄露。2) 模型构建:使用预训练的视觉-语言模型,例如CLIP,并冻结其编码器部分。3) 参数高效训练:应用不同的PET方法(BitFit、LoRA、Adapter)来训练少量可训练参数。4) 模型评估:在Indiana University Chest X-Ray数据集和CheXpert数据集上评估模型的性能,使用AUROC和ECE等指标。
关键创新:最重要的技术创新点在于,证明了在多模态胸部X光分析中,通过冻结编码器并采用参数高效训练策略,可以在显著降低计算成本的同时,获得优于全参数微调的性能。此外,论文还发现,在预算匹配的情况下,参数分配比跨模态协同作用更重要。
关键设计:关键设计包括:1) 病理术语删除:为了防止数据泄露,从文本报告中删除了病理术语。2) 参数预算控制:所有PET变体都限制在相同的参数预算内(2.37M参数)。3) 不同的PET变体:探索了BitFit、LoRA和Adapter等不同的PET方法,并比较了它们的性能。4) 外部验证:在CheXpert数据集上进行了外部验证,以评估模型的可扩展性。5) 校准评估:使用ECE指标评估了模型的校准性能,并指出需要进行事后校准。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在Indiana University Chest X-Ray数据集上,所有PET变体的AUROC均在0.892和0.908之间,优于全参数微调的0.770 AUROC,参数量减少了40倍。在CheXpert数据集上,所有PET方法都实现了>0.69的AUROC,且可训练参数<9%,其中Adapter实现了最佳性能(0.7214 AUROC)。预算匹配的比较表明,参数分配比跨模态协同作用更重要。
🎯 应用场景
该研究成果可应用于医疗影像诊断辅助系统,特别是在资源受限的环境中,例如基层医疗机构。通过降低计算成本,使得大型视觉-语言模型能够更广泛地应用于胸部X光图像分析,辅助医生进行疾病诊断,提高诊断效率和准确性。未来的研究可以进一步探索更有效的参数高效训练方法,并结合事后校准技术,提高模型的临床实用性。
📄 摘要(原文)
Multimodal chest X-Ray analysis often fine-tunes large vision-language models, which is computationally costly. We study parameter-efficient training (PET) strategies, including frozen encoders, BitFit, LoRA, and adapters for multi-label classification on the Indiana University Chest X-Ray dataset (3,851 image-report pairs; 579 test samples). To mitigate data leakage, we redact pathology terms from reports used as text inputs while retaining clinical context. Under a fixed parameter budget (2.37M parameters, 2.51% of total), all PET variants achieve AUROC between 0.892 and 0.908, outperforming full fine-tuning (0.770 AUROC), which uses 94.3M trainable parameters, a 40x reduction. External validation on CheXpert (224,316 images, 58x larger) confirms scalability: all PET methods achieve >0.69 AUROC with <9% trainable parameters, with Adapter achieving best performance (0.7214 AUROC). Budget-matched comparisons reveal that vision-only models (0.653 AUROC, 1.06M parameters) outperform budget-matched multimodal models (0.641 AUROC, 1.06M parameters), indicating improvements arise primarily from parameter allocation rather than cross-modal synergy. While PET methods show degraded calibration (ECE: 0.29-0.34) compared to simpler models (ECE: 0.049), this represents a tractable limitation addressable through post-hoc calibration methods. These findings demonstrate that frozen encoder strategies provide superior discrimination at substantially reduced computational cost, though calibration correction is essential for clinical deployment.