Understanding Virality: A Rubric based Vision-Language Model Framework for Short-Form Edutainment Evaluation
作者: Arnav Gupta, Gurekas Singh Sahney, Hardik Rathi, Abhishek Chandwani, Ishaan Gupta, Pratik Narang, Dhruv Kumar
分类: cs.CV
发布日期: 2025-12-24
备注: Under Review
💡 一句话要点
提出基于规则的视觉-语言模型框架,用于短视频教育娱乐内容评估,提升用户参与度预测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 短视频评估 视觉-语言模型 用户参与度预测 多模态特征 教育娱乐内容 特征聚类 回归模型
📋 核心要点
- 现有短视频评估方法缺乏对视听属性与用户参与度之间关系的深入理解,难以有效评估内容质量。
- 利用视觉-语言模型提取视听特征,聚类成可解释因子,并训练回归模型预测用户参与度,实现数据驱动的评估。
- 实验表明,该方法预测的用户参与度与实际情况高度相关,提供了一种可解释且可扩展的评估方案。
📝 摘要(中文)
评估短视频内容需要超越表面质量指标,转向符合人类认知的多模态推理。现有框架如VideoScore-2虽然评估了视觉和语义的保真度,但未能捕捉到特定视听属性如何驱动实际的观众参与度。本文提出了一种数据驱动的评估框架,该框架使用视觉-语言模型(VLM)提取无监督的视听特征,将它们聚类成可解释的因素,并训练一个基于回归的评估器来预测短视频教育娱乐内容的参与度。我们精心策划的YouTube Shorts数据集能够系统地分析VLM衍生的特征与人类参与行为之间的关系。实验表明,预测的参与度与实际参与度之间存在很强的相关性,证明了我们轻量级的、基于特征的评估器与传统指标(例如,SSIM,FID)相比,提供了可解释和可扩展的评估。通过将评估建立在多模态特征重要性和以人为中心的参与信号之上,我们的方法朝着鲁棒且可解释的视频理解迈进。
🔬 方法详解
问题定义:现有短视频评估方法,如VideoScore-2,侧重于视觉和语义保真度,未能充分理解特定视听元素如何影响观众的参与度。这导致无法有效评估短视频教育娱乐内容的质量,并难以预测用户互动行为。现有方法缺乏对多模态特征与用户参与度之间关系的深入分析。
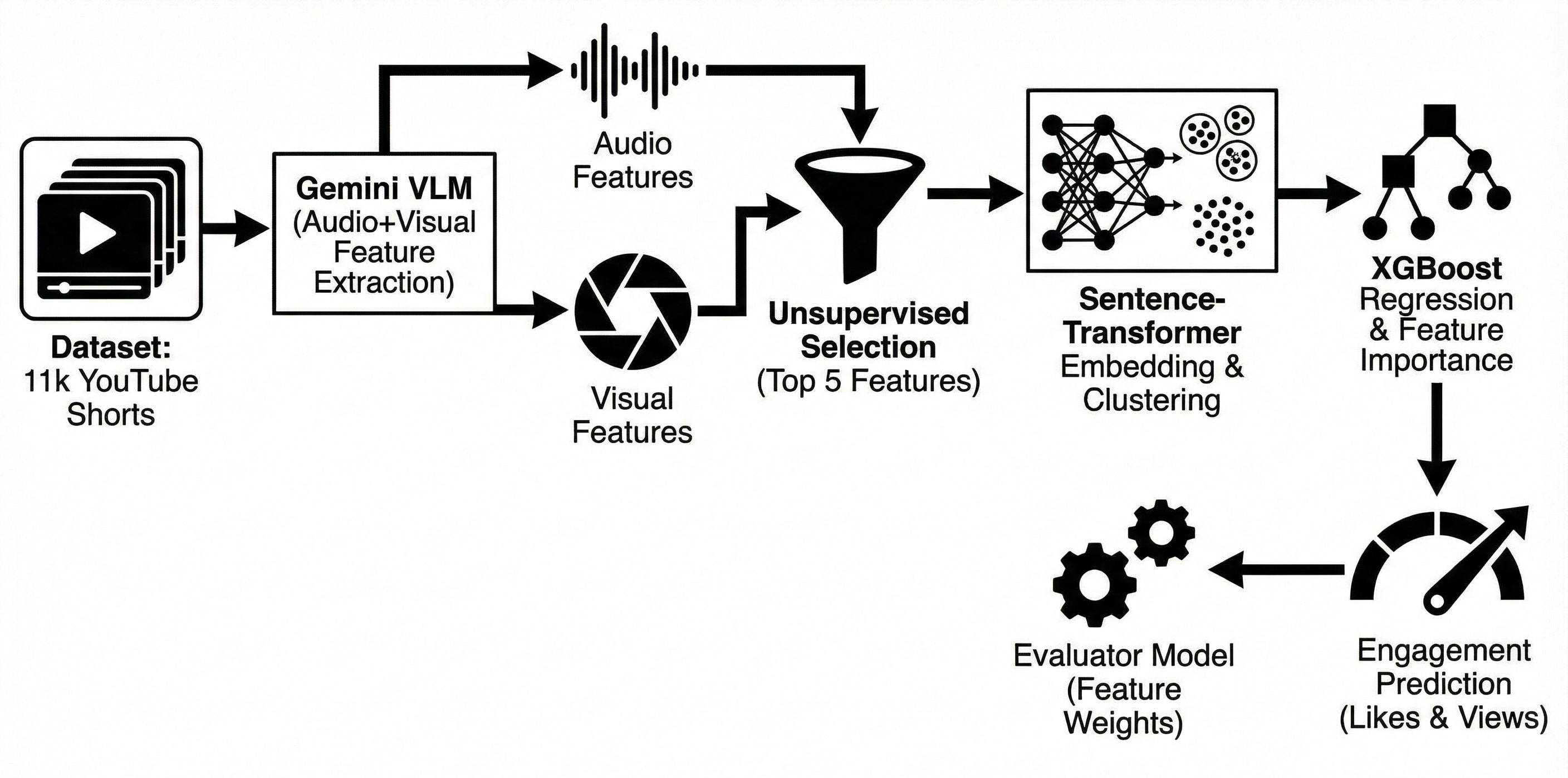
核心思路:本文的核心思路是利用视觉-语言模型(VLM)提取短视频中的视听特征,并将这些特征聚类成具有可解释性的因子。然后,使用这些因子训练一个回归模型,以预测用户在短视频上的参与度。这种方法旨在建立视听特征与用户参与度之间的直接联系,从而提供更准确和可解释的评估。
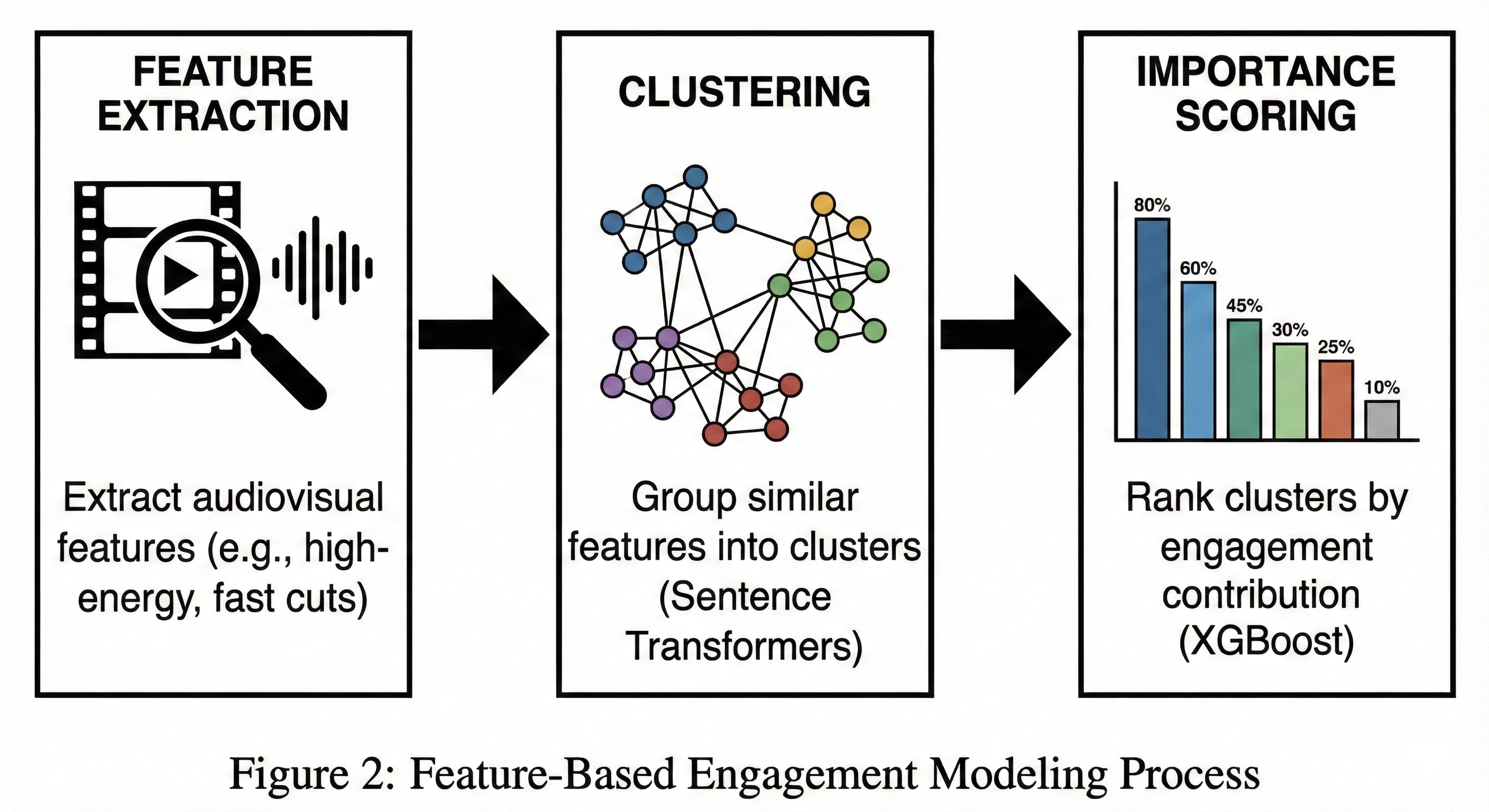
技术框架:该框架包含以下主要模块:1) 视听特征提取:使用VLM从短视频中提取无监督的视听特征。2) 特征聚类:将提取的特征聚类成可解释的因子,例如“幽默”、“信息量”等。3) 回归模型训练:使用聚类后的特征训练一个回归模型,以预测用户参与度。4) 评估与分析:评估模型的预测性能,并分析不同视听特征对用户参与度的影响。
关键创新:该方法的关键创新在于使用VLM提取无监督的视听特征,并通过聚类将其转化为可解释的因子。这使得模型能够理解视频内容中哪些元素对用户参与度有重要影响。与传统的基于像素或手工设计的特征相比,VLM提取的特征更具有语义信息,能够更好地捕捉视频内容的本质。
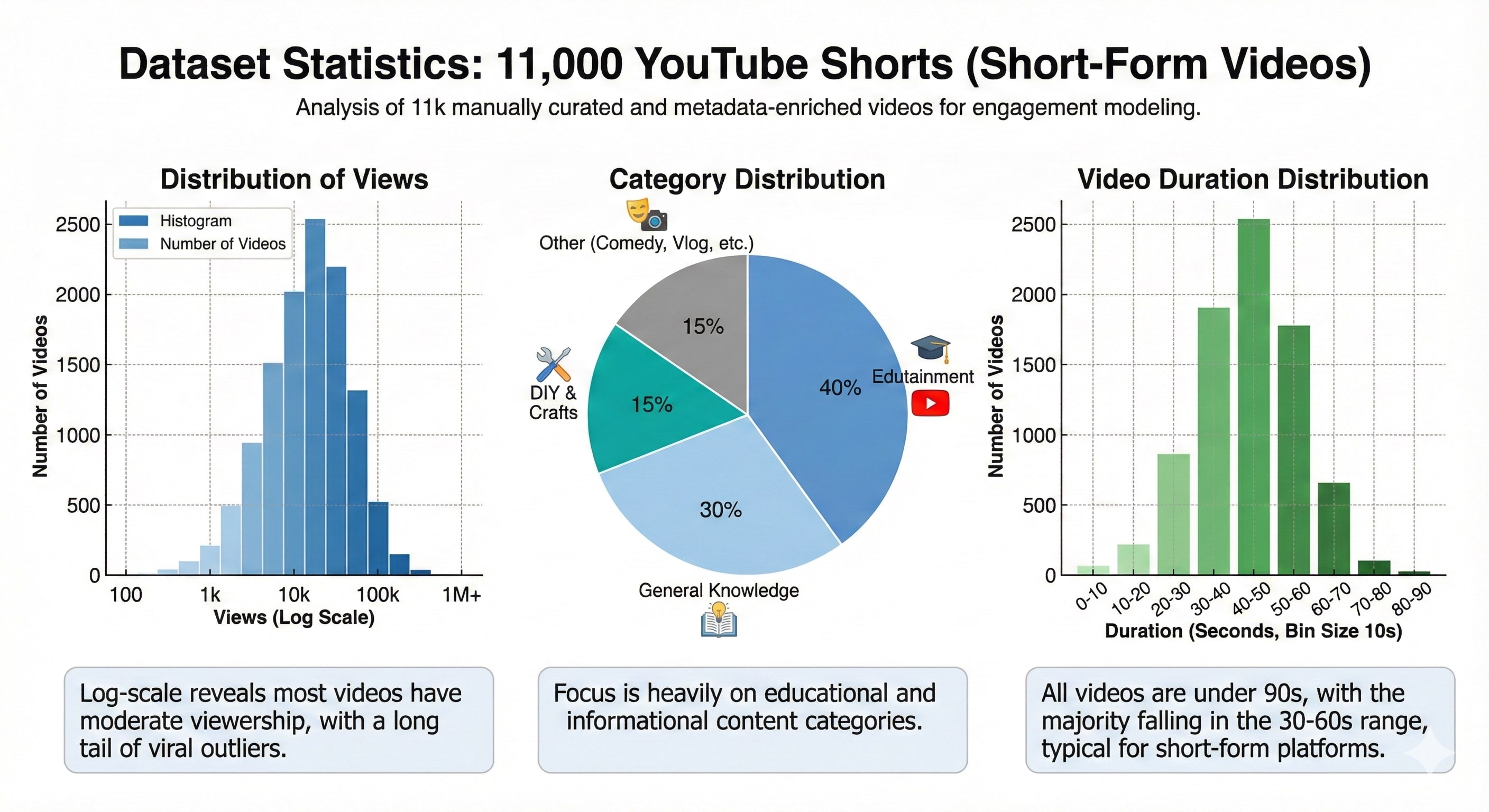
关键设计:具体的技术细节包括:1) 使用预训练的视觉-语言模型(具体模型未知)提取视频帧和音频的特征。2) 使用聚类算法(具体算法未知)将提取的特征聚类成不同的因子。3) 使用回归模型(具体模型未知)预测用户参与度,损失函数可能采用均方误差或类似的回归损失函数。数据集是作者自建的YouTube Shorts数据集,包含短视频教育娱乐内容和用户参与数据(例如点赞、评论、分享)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法预测的用户参与度与实际参与度之间存在很强的相关性。与传统的视频质量评估指标(如SSIM和FID)相比,该方法提供了更可解释和可扩展的评估结果。具体的性能数据和提升幅度在摘要中没有明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于短视频内容推荐、内容创作指导、在线教育资源评估等领域。通过预测用户参与度,平台可以更有效地推荐用户感兴趣的内容,创作者可以更好地了解如何制作更吸引人的视频,教育机构可以评估在线教育资源的质量和效果。该研究有助于提升短视频生态系统的整体质量和用户体验。
📄 摘要(原文)
Evaluating short-form video content requires moving beyond surface-level quality metrics toward human-aligned, multimodal reasoning. While existing frameworks like VideoScore-2 assess visual and semantic fidelity, they do not capture how specific audiovisual attributes drive real audience engagement. In this work, we propose a data-driven evaluation framework that uses Vision-Language Models (VLMs) to extract unsupervised audiovisual features, clusters them into interpretable factors, and trains a regression-based evaluator to predict engagement on short-form edutainment videos. Our curated YouTube Shorts dataset enables systematic analysis of how VLM-derived features relate to human engagement behavior. Experiments show strong correlations between predicted and actual engagement, demonstrating that our lightweight, feature-based evaluator provides interpretable and scalable assessments compared to traditional metrics (e.g., SSIM, FID). By grounding evaluation in both multimodal feature importance and human-centered engagement signals, our approach advances toward robust and explainable video understanding.