VideoScaffold: Elastic-Scale Visual Hierarchies for Streaming Video Understanding in MLLMs
作者: Naishan Zheng, Jie Huang, Qingpei Guo, Feng Zhao
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2025-12-23
备注: 11 pages, 4 figures
🔗 代码/项目: GITHUB
💡 一句话要点
VideoScaffold:面向MLLM的弹性尺度视觉层级,用于流式视频理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 流式视频理解 多模态大语言模型 弹性尺度事件分割 分层事件整合 动态视频表示 长视频理解 视觉层级结构
📋 核心要点
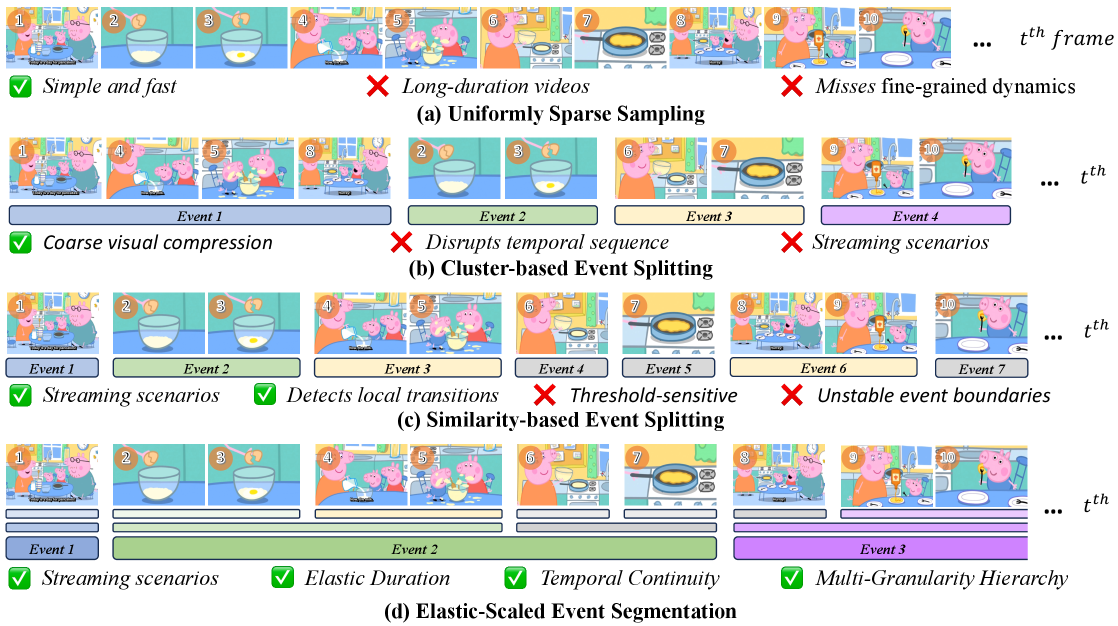
- 现有方法在处理流式长视频理解时,由于帧间冗余和时间连贯性需求,面临着碎片化和过度压缩的问题。
- VideoScaffold通过弹性尺度事件分割(EES)和分层事件整合(HEC),动态调整事件粒度并保留细粒度语义。
- 实验表明,VideoScaffold在离线和流式视频理解任务上均取得了SOTA性能,且易于集成到现有MLLM中。
📝 摘要(中文)
本文提出VideoScaffold,一个为流式视频理解设计的动态表示框架。由于视频帧之间存在大量冗余,以及需要时间上连贯的表示,利用多模态大语言模型(MLLM)理解长视频仍然具有挑战性。现有的静态策略,如稀疏采样、帧压缩和聚类,是为离线设置优化的,当应用于连续视频流时,通常会产生碎片化或过度压缩的输出。VideoScaffold自适应地根据视频时长调整事件粒度,同时保留细粒度的视觉语义。它引入了两个关键组件:弹性尺度事件分割(EES),执行预测引导的分割以动态细化事件边界;以及分层事件整合(HEC),逐步将语义相关的片段聚合到多层次的抽象中。EES和HEC协同工作,使VideoScaffold能够在视频流展开时,从细粒度的帧理解平滑过渡到抽象的事件推理。在离线和流式视频理解基准上的大量实验表明,VideoScaffold实现了最先进的性能。该框架是模块化的,即插即用,无缝地将现有的基于图像的MLLM扩展到连续视频理解。
🔬 方法详解
问题定义:现有方法,如稀疏采样、帧压缩和聚类,在处理流式长视频理解时,通常是针对离线场景设计的,无法很好地适应连续的视频流。这些方法容易产生碎片化或过度压缩的视频表示,导致信息丢失,影响后续的视频理解任务。因此,需要一种能够动态调整事件粒度,并保持时间连贯性的视频表示方法。
核心思路:VideoScaffold的核心思路是构建一个弹性尺度的视觉层级结构,能够根据视频的长度和内容,自适应地调整事件的粒度。通过预测引导的事件分割和分层事件整合,将视频分解成不同层次的语义单元,从而实现从细粒度的帧理解到抽象的事件推理的平滑过渡。这种动态调整的机制使得VideoScaffold能够有效地处理长视频中的冗余信息,并保持时间上的连贯性。
技术框架:VideoScaffold主要包含两个核心模块:弹性尺度事件分割(EES)和分层事件整合(HEC)。EES模块负责动态地细化事件边界,通过预测引导的分割,将视频流分割成具有语义意义的片段。HEC模块则负责将语义相关的片段逐步聚合到多层次的抽象中,构建一个层级的事件表示。这两个模块协同工作,使得VideoScaffold能够根据视频流的展开,从细粒度的帧理解过渡到抽象的事件推理。整体流程是从视频帧输入开始,经过EES进行事件分割,然后由HEC进行层级整合,最终得到多层次的视频表示。
关键创新:VideoScaffold的关键创新在于其动态调整事件粒度的能力。与传统的静态方法不同,VideoScaffold能够根据视频的内容和长度,自适应地调整事件的分割和整合策略。这种动态调整的机制使得VideoScaffold能够更好地处理长视频中的冗余信息,并保持时间上的连贯性。EES和HEC的协同工作,使得VideoScaffold能够构建一个弹性尺度的视觉层级结构,从而实现更有效的视频理解。
关键设计:EES模块的关键设计在于预测引导的分割策略,具体实现细节未知。HEC模块的关键设计在于如何定义和计算片段之间的语义相关性,以及如何进行层级的整合。论文中可能使用了特定的损失函数来优化EES和HEC的性能,具体的网络结构和参数设置未知。
🖼️ 关键图片

📊 实验亮点
VideoScaffold在多个视频理解基准测试中取得了state-of-the-art的性能。具体的数据和提升幅度在论文中给出,但此处未提供详细数值。该框架的模块化设计使其能够无缝集成到现有的基于图像的MLLM中,扩展了MLLM在视频理解方面的能力。
🎯 应用场景
VideoScaffold具有广泛的应用前景,例如智能监控、视频摘要、自动驾驶、在线教育等领域。它可以帮助机器更好地理解长视频内容,从而实现更智能化的视频分析和处理。例如,在智能监控中,VideoScaffold可以用于自动检测异常事件;在视频摘要中,它可以用于提取视频的关键片段;在自动驾驶中,它可以用于理解车辆周围的交通状况。未来,VideoScaffold有望成为多模态大语言模型理解视频内容的重要组成部分。
📄 摘要(原文)
Understanding long videos with multimodal large language models (MLLMs) remains challenging due to the heavy redundancy across frames and the need for temporally coherent representations. Existing static strategies, such as sparse sampling, frame compression, and clustering, are optimized for offline settings and often produce fragmented or over-compressed outputs when applied to continuous video streams. We present VideoScaffold, a dynamic representation framework designed for streaming video understanding. It adaptively adjusts event granularity according to video duration while preserving fine-grained visual semantics. VideoScaffold introduces two key components: Elastic-Scale Event Segmentation (EES), which performs prediction-guided segmentation to dynamically refine event boundaries, and Hierarchical Event Consolidation (HEC), which progressively aggregates semantically related segments into multi-level abstractions. Working in concert, EES and HEC enable VideoScaffold to transition smoothly from fine-grained frame understanding to abstract event reasoning as the video stream unfolds. Extensive experiments across both offline and streaming video understanding benchmarks demonstrate that VideoScaffold achieves state-of-the-art performance. The framework is modular and plug-and-play, seamlessly extending existing image-based MLLMs to continuous video comprehension. The code is available at https://github.com/zheng980629/VideoScaffold.