Input-Adaptive Visual Preprocessing for Efficient Fast Vision-Language Model Inference
作者: Putu Indah Githa Cahyani, Komang David Dananjaya Suartana, Novanto Yudistira
分类: cs.CV
发布日期: 2025-12-23
🔗 代码/项目: GITHUB
💡 一句话要点
提出输入自适应视觉预处理方法,提升FastVLM在视觉问答任务中的推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 自适应预处理 推理效率 内容感知 视觉问答
📋 核心要点
- 现有视觉-语言模型在处理高分辨率图像时计算成本高,推理速度慢,静态预处理方式对简单图像存在冗余计算。
- 提出一种自适应视觉预处理方法,通过内容感知分析动态调整输入分辨率和裁剪区域,减少视觉冗余。
- 实验表明,该方法在DocVQA数据集上将单张图像推理时间降低超过50%,视觉token数量减少超过55%。
📝 摘要(中文)
视觉-语言模型(VLMs)在多模态推理任务中表现出色,但由于高推理延迟和计算成本,尤其是在处理高分辨率视觉输入时,其部署仍然具有挑战性。虽然像FastVLM这样的架构通过优化的视觉编码器提高了效率,但现有的流程仍然依赖于静态视觉预处理,导致对视觉上简单的输入进行冗余计算。本文提出了一种自适应视觉预处理方法,该方法基于图像内容特征动态调整输入分辨率和空间覆盖范围。该方法结合了内容感知图像分析、自适应分辨率选择和内容感知裁剪,以减少视觉编码前的视觉冗余。重要的是,该方法与FastVLM集成,无需修改其架构或重新训练。我们在DocVQA数据集的一个子集上,在仅推理设置中评估了该方法,重点关注效率指标。实验结果表明,自适应预处理将每个图像的推理时间减少了50%以上,降低了平均完整生成时间,并且与基线流程相比,视觉token数量持续减少了55%以上。这些发现表明,输入感知预处理是提高视觉-语言模型面向部署的效率的有效且轻量级的策略。为了便于重现,我们的实现作为FastVLM存储库的一个分支提供,其中包含所提出方法的文件,可在https://github.com/kmdavidds/mlfastlm上找到。
🔬 方法详解
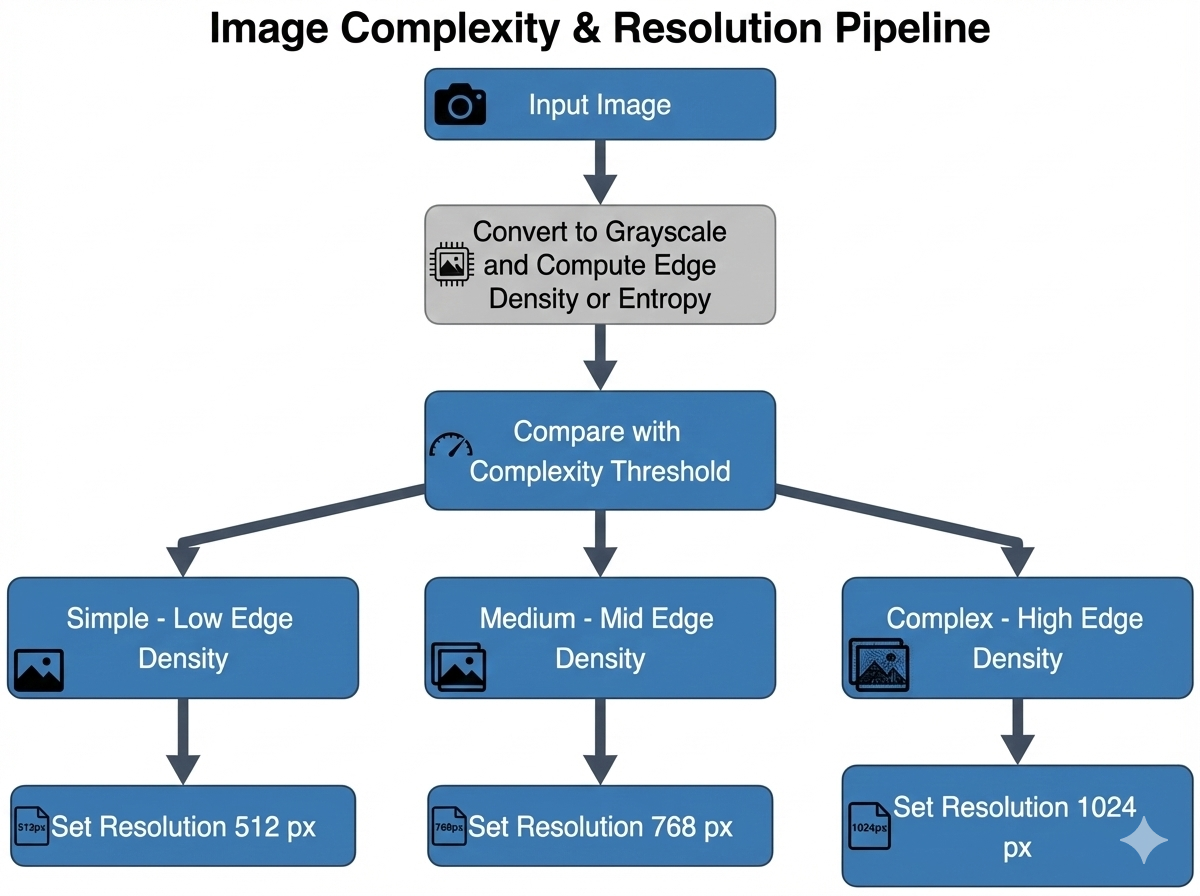
问题定义:现有视觉-语言模型(VLMs)在处理视觉信息时,通常采用固定的预处理流程,例如固定分辨率的缩放和裁剪。这种静态预处理方式忽略了图像本身的内容特性,对于一些视觉信息简单的图像,仍然会进行大量的冗余计算,导致推理效率降低。因此,论文要解决的问题是如何根据输入图像的内容自适应地进行预处理,从而减少计算量,提高VLMs的推理速度。
核心思路:论文的核心思路是利用图像的内容信息来指导视觉预处理过程。具体来说,首先对图像进行内容分析,判断图像的复杂程度,然后根据图像的复杂程度自适应地选择合适的分辨率和裁剪区域。对于视觉信息简单的图像,降低分辨率或裁剪掉不重要的区域,从而减少后续视觉编码器的计算量。
技术框架:该方法主要包含三个阶段:1) 内容感知图像分析:使用图像显著性检测等技术分析图像的内容,提取图像的特征,例如显著区域的位置和大小。2) 自适应分辨率选择:根据图像的复杂程度,动态选择输入图像的分辨率。对于视觉信息简单的图像,降低分辨率。3) 内容感知裁剪:根据图像的显著区域,裁剪掉不重要的背景区域,减少视觉编码器的输入。整个流程与FastVLM模型集成,无需修改FastVLM的架构或重新训练。
关键创新:该方法最大的创新点在于提出了输入自适应的视觉预处理策略。与传统的静态预处理方法相比,该方法能够根据图像的内容动态调整预处理参数,从而更有效地减少视觉冗余,提高推理效率。这种自适应的预处理方式可以应用于各种视觉-语言模型,具有较强的通用性。
关键设计:内容感知图像分析阶段,可以使用现有的显著性检测算法,例如基于深度学习的显著性检测模型。自适应分辨率选择阶段,可以根据图像的显著区域大小和数量,设置不同的分辨率阈值。内容感知裁剪阶段,可以根据显著区域的位置和大小,设置裁剪框的参数。具体参数的选择需要根据实际应用场景进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在DocVQA数据集上取得了显著的性能提升。与基线方法相比,每个图像的推理时间减少了50%以上,平均完整生成时间降低,视觉token数量持续减少了55%以上。这些结果表明,输入自适应预处理是一种有效且轻量级的策略,可以显著提高视觉-语言模型的推理效率。
🎯 应用场景
该研究成果可应用于各种需要高效视觉-语言模型推理的场景,例如移动设备上的视觉问答、智能客服、图像搜索等。通过降低计算成本和推理延迟,可以使VLMs在资源受限的环境中更好地部署和应用,并提升用户体验。未来,该方法可以进一步扩展到视频理解等领域。
📄 摘要(原文)
Vision-Language Models (VLMs) have demonstrated strong performance on multimodal reasoning tasks, but their deployment remains challenging due to high inference latency and computational cost, particularly when processing high-resolution visual inputs. While recent architectures such as FastVLM improve efficiency through optimized vision encoders, existing pipelines still rely on static visual preprocessing, leading to redundant computation for visually simple inputs. In this work, we propose an adaptive visual preprocessing method that dynamically adjusts input resolution and spatial coverage based on image content characteristics. The proposed approach combines content-aware image analysis, adaptive resolution selection, and content-aware cropping to reduce visual redundancy prior to vision encoding. Importantly, the method is integrated with FastVLM without modifying its architecture or requiring retraining. We evaluate the proposed method on a subset of the DocVQA dataset in an inference-only setting, focusing on efficiency-oriented metrics. Experimental results show that adaptive preprocessing reduces per-image inference time by over 50\%, lowers mean full generation time, and achieves a consistent reduction of more than 55\% in visual token count compared to the baseline pipeline. These findings demonstrate that input-aware preprocessing is an effective and lightweight strategy for improving deployment-oriented efficiency of vision-language models. To facilitate reproducibility, our implementation is provided as a fork of the FastVLM repository, incorporating the files for the proposed method, and is available at https://github.com/kmdavidds/mlfastlm.