NULLBUS: Multimodal Mixed-Supervision for Breast Ultrasound Segmentation via Nullable Global-Local Prompts
作者: Raja Mallina, Bryar Shareef
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-12-23
备注: 5 pages, 2 figures, and 4 tables
💡 一句话要点
NullBUS:通过可空全局-局部提示的多模态混合监督乳腺超声分割
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 乳腺超声分割 多模态学习 混合监督 可空提示 医学图像分析
📋 核心要点
- 现有乳腺超声分割方法依赖完整提示信息,但公共数据集常缺乏可靠元数据,限制了模型训练和泛化能力。
- NullBUS框架通过引入可空提示,允许模型在缺少文本提示时回退到图像信息,实现混合监督学习。
- 实验表明,NullBUS在混合提示条件下取得了state-of-the-art的分割性能,平均IoU达到0.8568,平均Dice达到0.9103。
📝 摘要(中文)
乳腺超声(BUS)分割提供了计算机辅助诊断和治疗计划所需的重要病灶边界。虽然当文本或空间提示可用时,可提示方法可以提高分割性能和肿瘤描绘,但许多公共BUS数据集缺乏可靠的元数据或报告,限制了对小型多模态子集的训练,降低了鲁棒性。我们提出了NullBUS,一个多模态混合监督框架,可以在单个模型中学习带有和不带有提示的图像。为了处理缺失的文本,我们引入了可空提示,实现为带有存在掩码的可学习空嵌入,从而在元数据缺失时回退到仅图像证据,并在存在文本时使用文本。在三个公共BUS数据集的统一池上评估,NullBUS实现了0.8568的平均IoU和0.9103的平均Dice,展示了混合提示可用性下的最先进性能。
🔬 方法详解
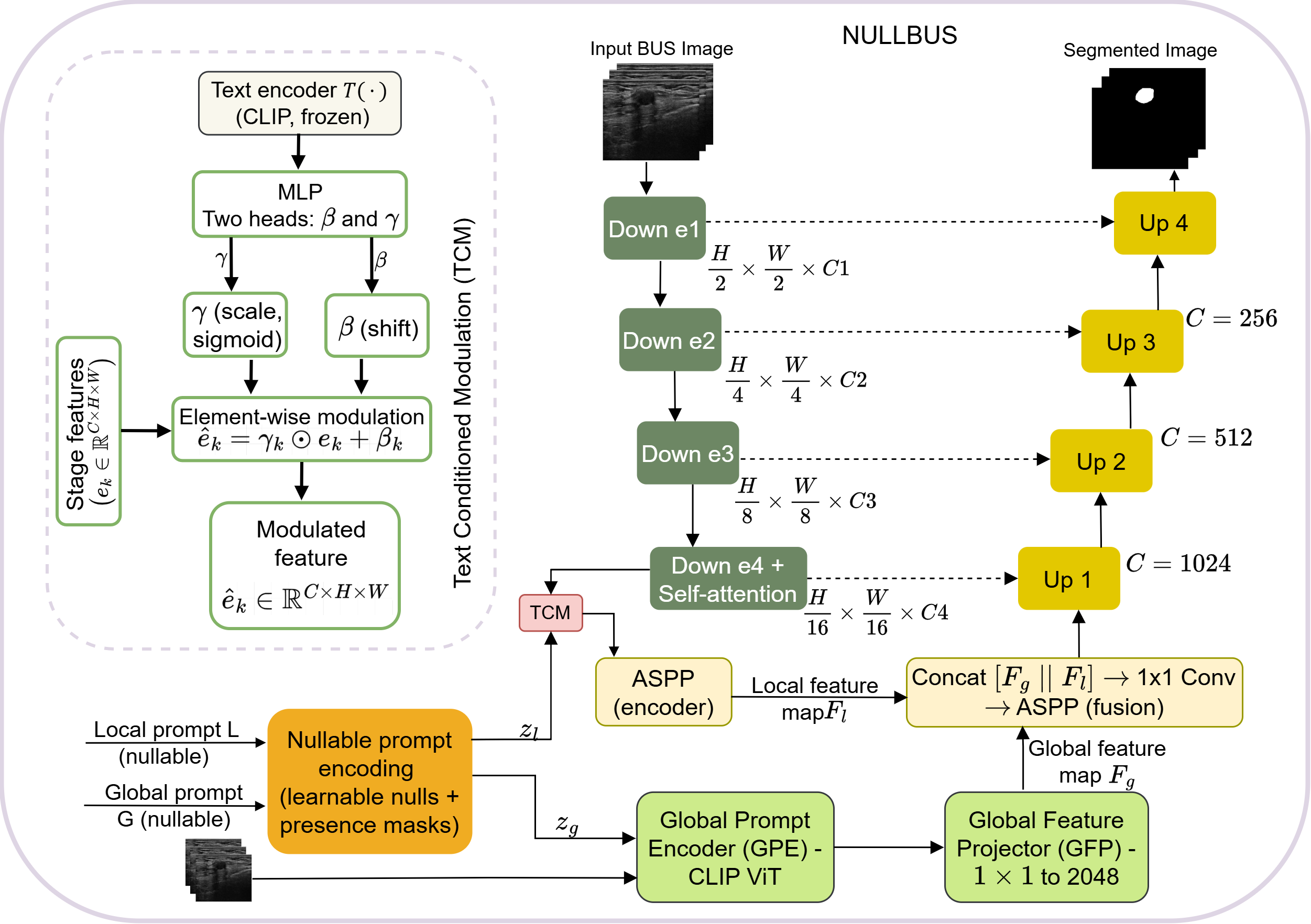
问题定义:乳腺超声图像分割旨在精确识别病灶区域,为诊断和治疗提供依据。然而,现有方法依赖于高质量的文本或空间提示,而公开的乳腺超声数据集中,这些提示信息往往缺失或不完整,导致模型训练受限,泛化能力下降。现有方法难以有效利用同时包含完整和缺失提示信息的数据集进行训练。
核心思路:NullBUS的核心在于引入“可空提示”的概念,允许模型在缺少文本提示时,能够回退到仅使用图像信息进行分割。通过学习一个“空嵌入” (null embedding) 来表示缺失的文本提示,并使用存在掩码 (presence mask) 来指示提示的可用性,模型可以自适应地利用不同模态的信息。
技术框架:NullBUS框架包含图像编码器、文本提示编码器(带有可空提示机制)和分割解码器。图像编码器提取图像特征,文本提示编码器将文本提示(如果存在)编码为特征向量。如果文本提示缺失,则使用可学习的空嵌入代替。分割解码器融合图像特征和文本提示特征,生成分割掩码。整个框架采用混合监督学习策略,同时利用带有完整提示和缺失提示的数据进行训练。
关键创新:NullBUS的关键创新在于可空提示机制,它允许模型在缺少文本提示的情况下,仍然能够有效地利用图像信息进行分割。这种机制使得模型能够利用更大规模的、包含不完整提示信息的数据集进行训练,从而提高模型的鲁棒性和泛化能力。与现有方法相比,NullBUS不需要对数据集进行严格筛选,可以处理更真实、更复杂的数据情况。
关键设计:可空提示通过学习一个可训练的空嵌入向量来实现,该向量代表了缺失的文本提示。存在掩码是一个二元变量,指示文本提示是否可用。损失函数包括分割损失(例如Dice损失或交叉熵损失)和正则化项,用于约束空嵌入的学习。网络结构可以采用常见的分割网络,例如U-Net或Mask R-CNN,并进行适当的修改以适应多模态输入。
🖼️ 关键图片

📊 实验亮点
NullBUS在三个公共乳腺超声数据集的统一测试中,取得了state-of-the-art的性能。具体而言,NullBUS的平均IoU达到0.8568,平均Dice系数达到0.9103,显著优于现有方法。实验结果表明,NullBUS能够有效地利用混合提示信息,提高分割精度和鲁棒性。
🎯 应用场景
NullBUS可应用于乳腺癌的计算机辅助诊断,辅助医生进行病灶识别和分割,提高诊断准确率和效率。该方法还可以推广到其他医学图像分割任务中,尤其是在数据集中存在缺失模态信息的情况下。未来,NullBUS可以集成到临床工作流程中,为医生提供更全面的诊断支持。
📄 摘要(原文)
Breast ultrasound (BUS) segmentation provides lesion boundaries essential for computer-aided diagnosis and treatment planning. While promptable methods can improve segmentation performance and tumor delineation when text or spatial prompts are available, many public BUS datasets lack reliable metadata or reports, constraining training to small multimodal subsets and reducing robustness. We propose NullBUS, a multimodal mixed-supervision framework that learns from images with and without prompts in a single model. To handle missing text, we introduce nullable prompts, implemented as learnable null embeddings with presence masks, enabling fallback to image-only evidence when metadata are absent and the use of text when present. Evaluated on a unified pool of three public BUS datasets, NullBUS achieves a mean IoU of 0.8568 and a mean Dice of 0.9103, demonstrating state-of-the-art performance under mixed prompt availability.