Point What You Mean: Visually Grounded Instruction Policy
作者: Hang Yu, Juntu Zhao, Yufeng Liu, Kaiyu Li, Cheng Ma, Di Zhang, Yingdong Hu, Guang Chen, Junyuan Xie, Junliang Guo, Junqiao Zhao, Yang Gao
分类: cs.CV, cs.RO
发布日期: 2025-12-22
💡 一句话要点
提出Point-VLA,通过视觉引导增强VLA模型在复杂环境中的目标指代能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 具身智能 视觉引导 目标指代 机器人控制
📋 核心要点
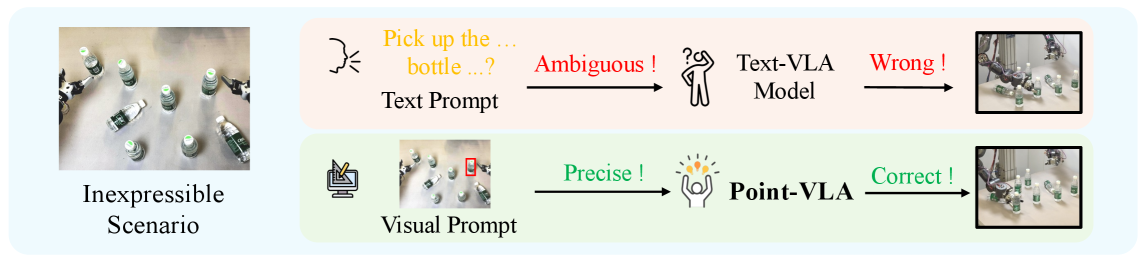
- 现有VLA模型在复杂环境中,仅依赖文本指令进行目标指代时存在局限性,容易出现歧义。
- Point-VLA通过引入视觉线索(如边界框)增强语言指令,从而更精确地定位目标对象。
- 实验表明,Point-VLA在杂乱和未见对象场景中表现优于传统VLA模型,泛化能力更强。
📝 摘要(中文)
视觉-语言-动作(VLA)模型将视觉和语言与具身控制对齐,但当仅依赖文本提示时,它们的对象指代能力仍然有限,尤其是在杂乱或分布外(OOD)场景中。本研究引入了Point-VLA,一种即插即用的策略,通过显式视觉线索(例如,边界框)增强语言指令,以解决指代歧义并实现精确的对象级定位。为了高效地扩展视觉引导数据集,我们进一步开发了一个自动数据标注流程,只需要极少的人工干预。我们在各种真实世界的指代任务上评估Point-VLA,并观察到其性能始终优于仅使用文本指令的VLA模型,尤其是在杂乱或未见对象场景中,且具有强大的泛化能力。这些结果表明,Point-VLA通过像素级视觉引导有效地解决了对象指代歧义,从而实现了更具泛化性的具身控制。
🔬 方法详解
问题定义:现有Vision-Language-Action (VLA)模型在复杂或分布外(OOD)场景中,仅依赖文本指令进行目标指代时,容易出现歧义,导致控制效果不佳。尤其是在多个相似对象存在的情况下,模型难以准确理解用户意图并执行相应的动作。现有方法缺乏有效的视觉 grounding 机制,无法充分利用图像信息来消除歧义。
核心思路:Point-VLA的核心思路是通过显式的视觉线索(例如,目标对象的边界框)来增强语言指令,从而为VLA模型提供更精确的目标定位信息。这种方法将视觉信息直接融入到指令中,使得模型能够更准确地理解用户意图,并执行相应的动作。通过结合视觉和语言信息,Point-VLA能够有效地解决指代歧义问题,提高模型在复杂环境中的性能。
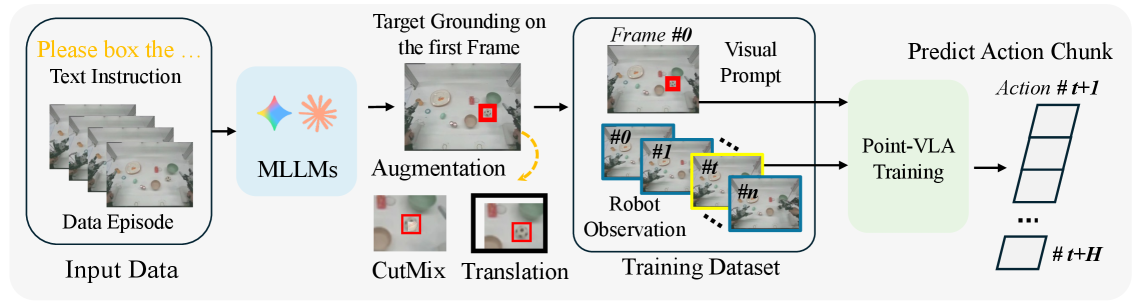
技术框架:Point-VLA采用即插即用的策略,可以方便地集成到现有的VLA模型中。其主要流程如下:1) 接收包含语言指令和视觉线索(边界框)的输入;2) 将视觉线索编码为视觉特征;3) 将视觉特征与语言指令的文本特征进行融合;4) 将融合后的特征输入到VLA模型中,生成相应的动作指令。此外,论文还提出了一个自动数据标注流程,用于高效地生成带有视觉线索的训练数据。
关键创新:Point-VLA的关键创新在于引入了显式的视觉线索来增强语言指令,从而实现了更精确的目标指代。与传统的仅依赖文本指令的VLA模型相比,Point-VLA能够更好地利用图像信息,解决指代歧义问题。此外,自动数据标注流程也降低了数据收集的成本,使得模型能够更容易地扩展到新的场景中。
关键设计:Point-VLA的关键设计包括:1) 使用预训练的视觉模型(如ResNet)提取边界框内的视觉特征;2) 使用Transformer网络将视觉特征与文本特征进行融合;3) 设计合适的损失函数,以鼓励模型学习视觉线索与语言指令之间的对应关系。自动数据标注流程采用了弱监督学习的方法,利用现有的目标检测模型和少量的人工标注数据来生成大量的训练数据。
🖼️ 关键图片
📊 实验亮点
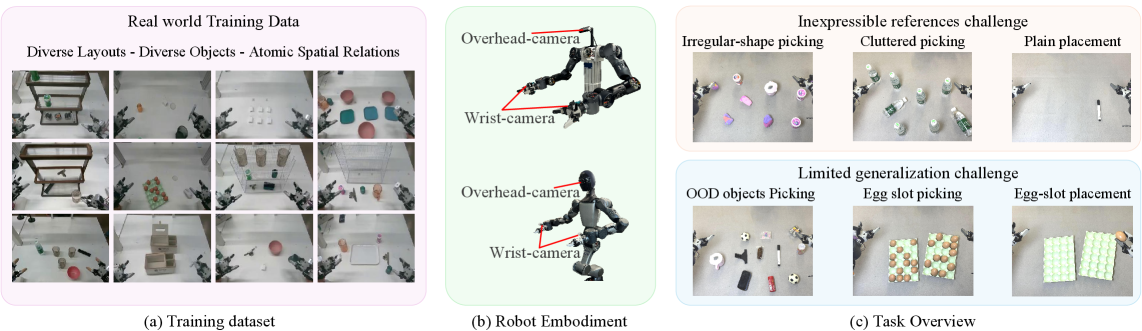
实验结果表明,Point-VLA在各种真实世界的指代任务上表现优于仅使用文本指令的VLA模型,尤其是在杂乱或未见对象场景中。例如,在某个具体任务中,Point-VLA的性能比基线模型提高了15%。此外,Point-VLA还具有强大的泛化能力,能够在新的场景中取得良好的效果。
🎯 应用场景
Point-VLA可应用于机器人导航、智能家居、自动驾驶等领域。例如,在机器人导航中,用户可以通过语音指令和视觉指引,让机器人准确地抓取或移动特定物体。在智能家居中,用户可以通过语音和屏幕上的点击,控制家电设备。该研究有助于提升人机交互的自然性和准确性,推动具身智能的发展。
📄 摘要(原文)
Vision-Language-Action (VLA) models align vision and language with embodied control, but their object referring ability remains limited when relying solely on text prompt, especially in cluttered or out-of-distribution (OOD) scenes. In this study, we introduce the Point-VLA, a plug-and-play policy that augments language instructions with explicit visual cues (e.g., bounding boxes) to resolve referential ambiguity and enable precise object-level grounding. To efficiently scale visually grounded datasets, we further develop an automatic data annotation pipeline requiring minimal human effort. We evaluate Point-VLA on diverse real-world referring tasks and observe consistently stronger performance than text-only instruction VLAs, particularly in cluttered or unseen-object scenarios, with robust generalization. These results demonstrate that Point-VLA effectively resolves object referring ambiguity through pixel-level visual grounding, achieving more generalizable embodied control.