Delta-LLaVA: Base-then-Specialize Alignment for Token-Efficient Vision-Language Models
作者: Mohamad Zamini, Diksha Shukla
分类: cs.CV
发布日期: 2025-12-21
💡 一句话要点
Delta-LLaVA:面向token高效的视觉-语言模型,提出Base-then-Specialize对齐方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉语言模型 token效率 低秩投影 Transformer 视觉问答 图像描述
📋 核心要点
- 现有MLLM视觉投影器在高分辨率输入下扩展性差,引入冗余,导致计算成本高昂。
- Delta-LLaVA采用低秩DeltaProjection进行基础对齐,再用轻量级Transformer进行专门化,实现token高效。
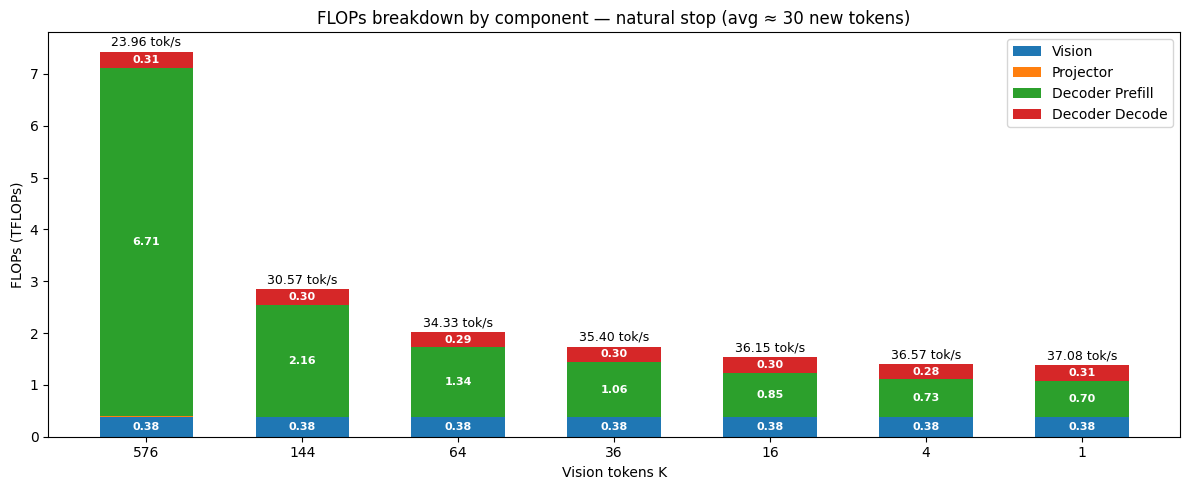
- 实验表明,Delta-LLaVA在多个基准测试中取得一致收益,推理吞吐量提升高达55%,训练加速4-5倍。
📝 摘要(中文)
多模态大型语言模型(MLLMs)结合视觉和文本表示,实现了丰富的推理能力。然而,处理密集视觉token的高计算成本仍然是一个主要瓶颈。视觉投影器是此流程中的关键组件,它连接视觉编码器和语言模型。标准设计通常采用简单的多层感知器进行直接token映射,但这种方法在高分辨率输入下扩展性较差,引入了显著的冗余。我们提出了Delta-LLaVA,一种token高效的投影器,它采用低秩DeltaProjection将多层视觉特征对齐到紧凑的子空间,然后再进行进一步交互。在此基础对齐之上,轻量级Transformer块充当专门化层,在受限的token预算下捕获全局和局部结构。大量的实验和消融研究表明,这种base-then-specialize设计仅使用144个token即可在多个基准测试中产生一致的收益,突出了在扩展交互能力之前进行token形成的重要性。使用Delta-LLaVA,推理吞吐量提高了高达55%,而端到端训练在预训练中加速了近4-5倍,在微调中加速了超过1.5倍,突出了我们设计在效率和可扩展性方面的双重优势。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLMs)中,视觉投影器处理高分辨率图像时计算成本过高的问题。现有的方法,例如使用多层感知器直接映射视觉token,在高分辨率输入下会产生大量的冗余token,导致计算效率低下。
核心思路:论文的核心思路是采用一种“base-then-specialize”的对齐策略。首先,使用低秩的DeltaProjection将多层视觉特征投影到一个紧凑的子空间,进行基础对齐,减少token数量。然后,在此基础上,使用轻量级的Transformer块作为专门化层,捕获全局和局部结构,提升模型性能。
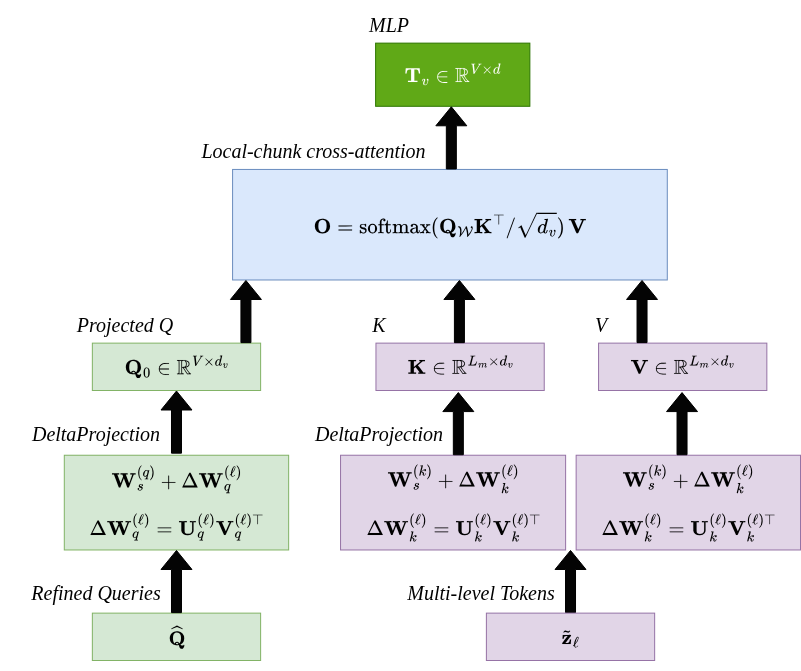
技术框架:Delta-LLaVA的整体架构包含以下几个主要模块:1) 视觉编码器:提取多层视觉特征。2) DeltaProjection:一个低秩投影模块,将多层视觉特征对齐到紧凑的子空间。3) 专门化层:轻量级的Transformer块,用于捕获全局和局部结构。4) 语言模型:接收视觉特征和文本输入,进行多模态推理。整个流程是先通过视觉编码器提取特征,然后通过DeltaProjection进行降维和对齐,再通过Transformer块进行特征增强,最后输入到语言模型中。
关键创新:论文最重要的技术创新点在于提出了DeltaProjection,这是一种低秩投影方法,能够有效地减少视觉token的数量,降低计算成本,同时保持模型性能。与直接使用多层感知器进行token映射的方法相比,DeltaProjection能够更好地处理高分辨率输入,避免产生大量的冗余token。
关键设计:DeltaProjection的关键设计在于使用低秩矩阵进行投影,从而减少参数数量和计算量。专门化层使用轻量级的Transformer块,以减少计算成本,同时捕获全局和局部结构。论文还对token数量进行了约束,以进一步提高效率。具体的参数设置和损失函数等技术细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Delta-LLaVA在多个基准测试中取得了显著的性能提升。例如,在推理吞吐量方面,Delta-LLaVA提高了高达55%。在端到端训练方面,Delta-LLaVA在预训练中加速了近4-5倍,在微调中加速了超过1.5倍。这些结果表明,Delta-LLaVA在效率和可扩展性方面都具有显著的优势。
🎯 应用场景
Delta-LLaVA具有广泛的应用前景,包括图像描述、视觉问答、机器人导航、自动驾驶等领域。通过提高多模态模型的效率和可扩展性,Delta-LLaVA可以促进这些领域的发展,并为实际应用带来更大的价值。例如,在机器人导航中,Delta-LLaVA可以帮助机器人更快速、更准确地理解周围环境,从而做出更明智的决策。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) combine visual and textual representations to enable rich reasoning capabilities. However, the high computational cost of processing dense visual tokens remains a major bottleneck. A critical component in this pipeline is the visual projector, which bridges the vision encoder and the language model. Standard designs often employ a simple multi-layer perceptron for direct token mapping, but this approach scales poorly with high-resolution inputs, introducing significant redundancy. We present Delta-LLaVA, a token-efficient projector that employs a low-rank DeltaProjection to align multi-level vision features into a compact subspace before further interaction. On top of this base alignment, lightweight Transformer blocks act as specialization layers, capturing both global and local structure under constrained token budgets. Extensive experiments and ablations demonstrate that this base-then-specialize design yields consistent gains across multiple benchmarks with only 144 tokens, highlighting the importance of token formation prior to scaling interaction capacity. With Delta-LLaVA, inference throughput improves by up to 55%, while end-to-end training accelerates by nearly 4-5x in pretraining and over 1.5x in finetuning, highlighting the dual benefits of our design in both efficiency and scalability.